
Arquitectura de microservicios - Parte 1: Introducción
Publicado por Daniel Sánchez el
Este es el primer post de una serie en la que vamos a ver diferentes cuestiones a tener en cuenta a la hora de diseñar una arquitectura basada en microservicios.
En primer lugar, muy brevemente (ya que hay amplia literatura sobre el tema) nos planteamos la cuestión del porqué de una arquitectura de microservicios:

Este tipo de arquitecturas surgen para dar solución a los problemas inherentes a los sistemas monolíticos. Estas son algunas de las ventajas que aportan:
- Servicios pequeños e independientes (principio de responsabilidad única).
- Unidades de despliegue pequeñas.
- Reducción de tiempo de desarrollo.
- Agilidad en hot fixes (consecuencia de las anteriores).
- Multitecnología.
- Fácil escalado horizontal.

La tendencia natural en cuanto a microservicios es crecer, tanto por nueva funcionalidad del sistema como por escalado horizontal. Es por esto, que surgen nuevas cuestiones que hay que resolver, como son:
- Localización de los servicios.
- Tolerancia a fallos.
- Gestión de la configuración.
- Gestión de logs.
- Gestión de los despliegues.

Afortunadamente, actualmente existen un número más que razonable de librerías y herramientas sobre las que apoyarse para la implementación de estas cuestiones. Entre ellas contamos con el stack tecnológico de Spring Cloud y Netflix OSS que veremos más adelante.
Para la implantación de una arquitectura de microservicios hemos tener en cuenta 3 aspectos principalmente:
- Un modelo de referencia en el que definir las necesidades de una arquitectura de microservicios.
- Un modelo de implementación en el que decidiremos y concretaremos la implementación de los componentes vistos en el modelo de referencia.
- Un modelo de despliegue donde definir cómo se van a desplegar los distintos componentes de la arquitectura en los diferentes entornos.

Modelo de referencia
Los siguientes serán los componentes que vamos a necesitar en una arquitectura de microservicios:
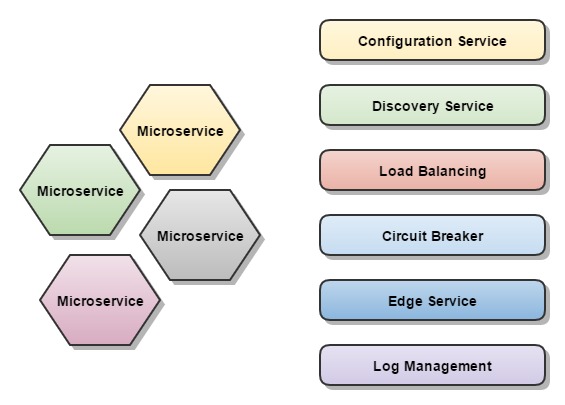
- Servidor de configuración central
Este componente se encargará de centralizar y proveer remotamente la configuración a cada microservicio. Esta configuración se mantiene convencionalmente en un repositorio Git, lo que nos permitirá gestionar su propio ciclo de vida y versionado.
- Servicio de registro / descubrimiento
Este servicio centralizado será el encargado de proveer los endpoints de los servicios para su consumo. Todo microservicio se registrará automáticamente en él en tiempo de bootstrap.
- Balanceo de carga (Load balancer)
Este patrón de implementación permite el balanceo entre distintas instancias de forma transparente a la hora de consumir un servicio.
- Tolerancia a fallos (Circuit breaker)
Mediante este patrón conseguiremos que cuando se produzca un fallo, este no se propague en cascada por todo el pipe de llamadas, y poder gestionar el error de forma controlada a nivel local del servicio donde se produjo.
- Servidor perimetral / exposición de servicios (Edge server)
Será un gateway en el que se expondrán los servicios a consumir.
- Centralización de logs
Se hace necesario un mecanismo para centralizar la gestión de logs. Pues sería inviable la consulta de cada log individual de cada uno de los microservicios.
Adicionalmente, también son interesantes los dos siguientes componentes:
- Servidor de Autorización
Para implementar la capa de seguridad (recomendable en la capa de servicios API)
- Monitorización
Es interesante el poder disponer de mecanismos y algún dashboard para monitorizar aspectos de los nodos como, salud, carga de trabajo...
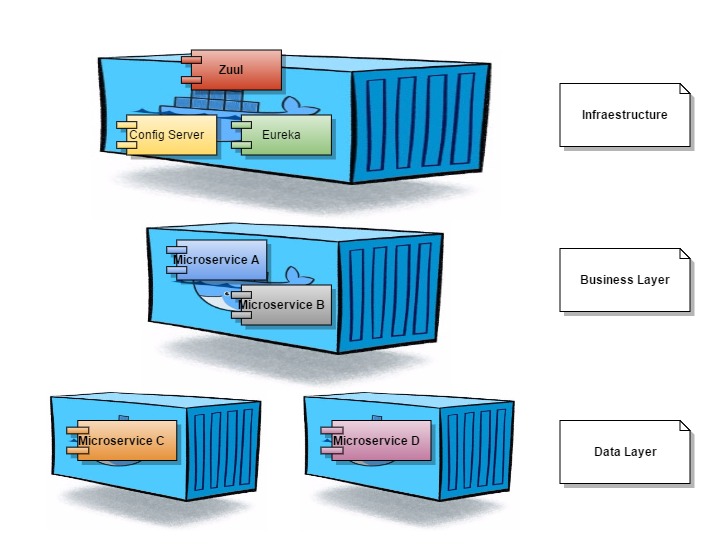
El siguiente diagrama muestra la arquitectura de microservicios en capas:
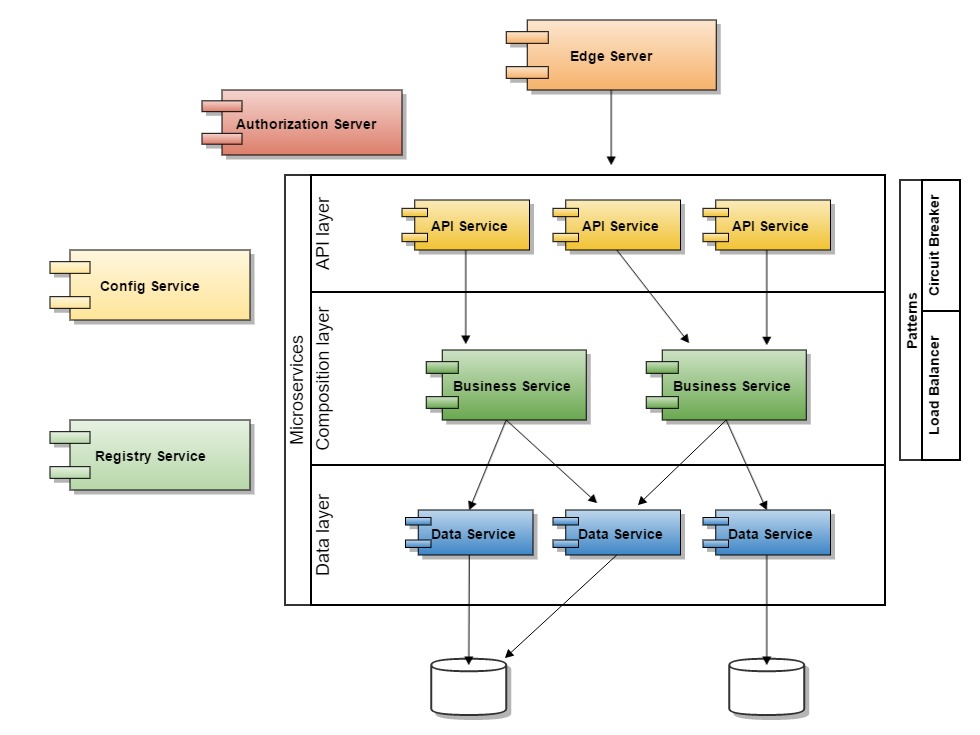
Modelo de implementación
Basándonos en el modelo de referencia, vamos a definir un modelo de implementación para cada uno de los componentes descritos. Para ello haremos uso del stack tecnológico de Spring Cloud y Netflix OSS:
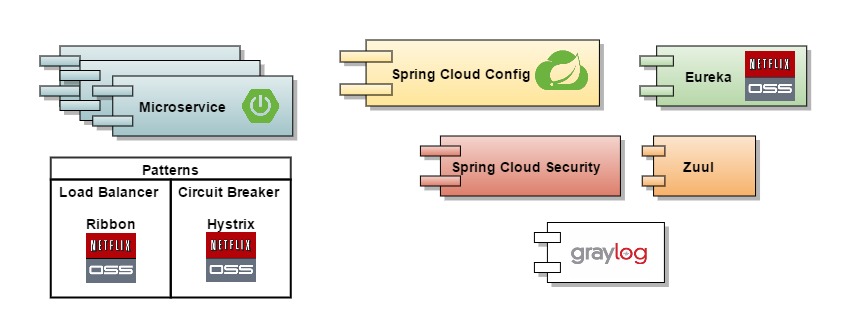
- Microservicios propiamente dichos: Serán aplicaciones Spring Boot con controladores Spring MVC. Utilizaremos Swagger para documentar y definir nuestro API.
- Config Server: microservicio basado en Spring Cloud Config. Utilizaremos Git como repositorio de configuración.
- Registry / Discovery Service: microservicio basado en Eureka de Netflix OSS.
- Load Balancer: utilizaremos Ribbon de Netflix OSS que ya viene integrado en REST-template de Spring.
- Circuit breaker: utilizaremos Hystrix de Netflix OSS.
- Gestión de Logs: utilizaremos Graylog
- Servidor perimetral: utilizaremos Zuul de Netflix OSS.
- Servidor de autorización: implementaremos el servicio con Spring Cloud Security.
Modelo de despliegue
La siguiente cuestión a tener en cuenta cuando pensamos en arquitecturas de microservicios es su modelo de despliegue. Nos referimos aquí al modo en que vamos a organizar y gestionar los despliegues de los microservicios, así como a las tecnologías que podemos usar para tal fin.
Existen convencionalmente dos tendencias en este sentido a la hora de encapsular microservicios:
- Máquinas virtuales.
- Contenedores.
En nuestro caso optaremos por contenedores Docker, ya que esta tecnología es la que está teniendo mayor acogida y repercusión en entornos cloud y PaaS.
El siguiente paso será pensar en la automatización y orquestación de los despliegues siguiendo el paradigma cloud.
Las opciones son montar sobre una PaaS un cluster de Docker donde desplegar de forma automágica y transparente nuestros contenedores.
En este punto, herramientas como Kubernetes y OpenShift aportan registry y config management a nivel de infraestructura, mientras que en nuestro ejemplo hemos utilizado las opciones de Spring Cloud y Netflix OSS para implementar estos servicios.
Aquí entrarían también cuestiones sobre alta disponibilidad, pero estos temas los relegaremos a futuros artículos.
El siguiente diagrama muestra un modelo simple de despliegue:
En siguientes posts de esta serie entraremos en más detalles, así que ¡síguenos en Twitter para estar informado!