
El lado oscuro de los microservicios: transacciones cross-service & patrón saga
Publicado por Daniel Sánchez el
Bienvenidos al apasionante y maravilloso mundo de los microservicios... o quizá no tan maravilloso… ¡pero sin duda apasionante! :)

En este artículo vamos a intentar mostrar el lado más oscuro sobre el desarrollo de microservicios: el diseño y la necesidad de transacciones entre servicios.

Problemática
Recordemos la naturaleza de las arquitecturas basadas en microservicios, en las que de forma más o menos purista, el diseño de los microservicios ha sido concebido en base al paradigma de contextos aislados o delimitados. En este escenario ya no existen las transacciones ACID y tarde o temprano se hará patente la necesidad de realizar transacciones entre estos contextos para mantener la consistencia de los datos a nivel de negocio.
Nada como un ejemplo: Tenemos un microservicio para reservar un vuelo y otro para elegir o actualizar el número de plaza. Estas 2 operaciones están separadas por la propia naturaleza del problema en 2 servicios distintos: la elección del nº de plaza no tiene la misma prioridad en el tiempo que la reserva de vuelo. Pero al final deberemos tener consistencia en la relación de la información de vuelo y nº de plaza, es decir, que si la reserva de plaza falla debemos gestionar la consistencia del sistema por ejemplo haciendo rollback sobre la reserva de vuelo. En definitiva, debemos simular una transacción entre servicios para mantener la consistencia en el sistema.
Dado que las transacciones distribuidas al estilo 2PC no son una buena idea, necesitamos implementar algún mecanismo que nos ayude a mantener esta consistencia en los datos: y aquí es donde aparece el patrón saga.
¿Pero qué es una saga?
Una saga es:
- Una forma alternativa de mantener la consistencia: Podemos definir una saga como una secuencia de transacciones locales que hay que coordinar. Además para cada una de estas transacciones se debe definir una acción compensatoria que deshaga el cambio que ha hecho la transacción.
- Explicado de otra manera: la implementación del patrón saga es la ejecución secuencial de una serie de steps (transacciones), de modo que si uno de los steps falla, se deben ejecutar las acciones compensatorias definidas para cada step en el orden inverso.
- Explicado de otra manera: para mantener la consistencia debemos implementar las gallinas que entran por las que salen.

Podemos representar una saga como una máquina de estados:
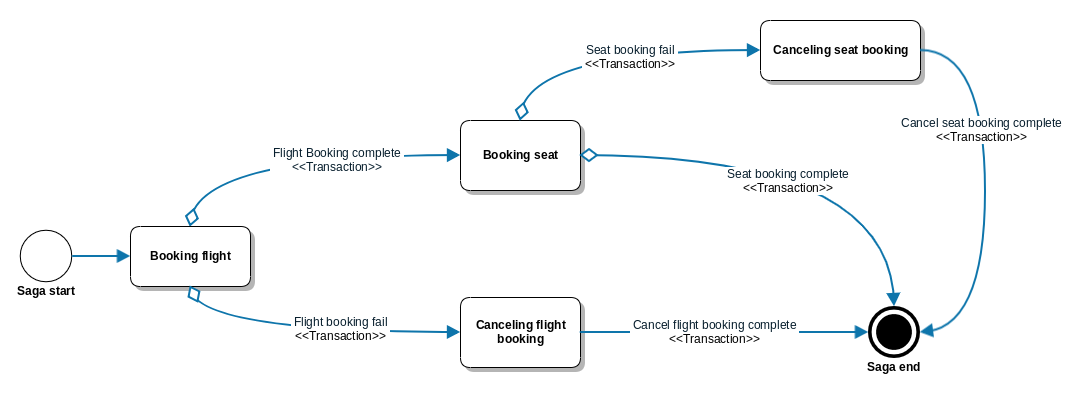
Patrones de implementación
Ahora que tenemos una idea conceptual de qué es el patrón saga, vamos a ver dos patrones a la hora de implementarlo:
- Mediante Coreografía: Bajo este patrón, tendremos la implementación de la lógica de la misma distribuida a lo largo de los servicios que intervienen (participantes). Cada servicio debe conocer e implementar cómo responder a cierto o ciertos estados (eventos) de la saga:
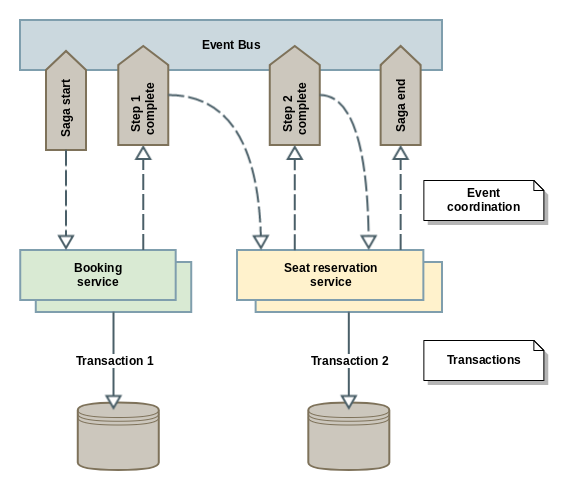
El inconveniente que tiene este patrón es que tendremos la lógica de la saga distribuida en varios sitios, lo que dificultará su comprensión y mantenimiento. Además, corremos el riesgo de introducir dependencias cíclicas entre servicios.
- Mediante Orquestación: Habrá un proceso o servicio encargado de la coordinación de los steps de la saga al que llamaremos manager o coordinador de la saga. Este manager aglutina toda la lógica de la saga simplificándola de esta manera y evitando dependencias cíclicas entre servicios.
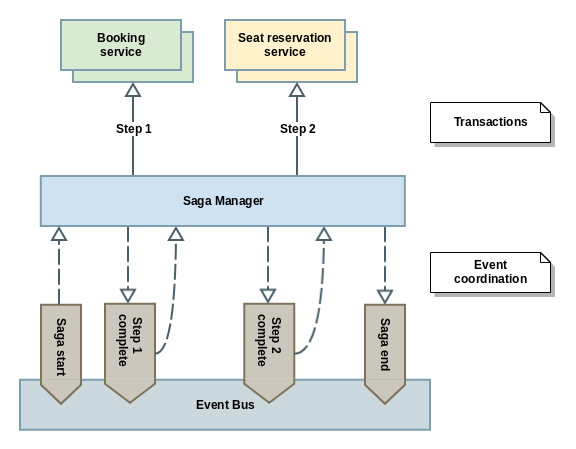
Una vez que tenemos claro qué patrón se adapta mejor a nuestras necesidades, sólo nos queda llevar a cabo la implementación. Hay frameworks que nos ayudan en esta labor, abstrayéndonos de tener que implementar nosotros la parte de infraestructura software necesaria, por ejemplo para el manejo de eventos, ya que sea dicho, una saga se construye sobre el concepto de servicios asíncronos y débilmente acoplados. Por tanto será una buena idea implementar nuestra saga orientada a mensajes:
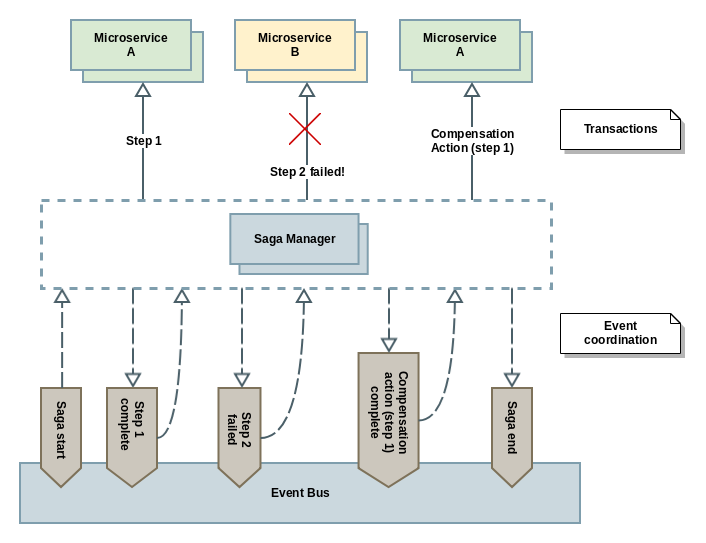
Conceptos importantes/interesantes
A la hora de implementar una saga o elegir un framework:
- Tener en cuenta la escalabilidad horizontal: Cualquier instancia del proceso que ejecuta una saga debe ser capaz de retomar la saga en cualquiera de sus estados. El proceso en sí es stateless, y el estado se almacena externamente al proceso (por ejemplo en BBDD). Para ello, cada ejecución de un step (transacción) debe almacenar su resultado (el estado de la saga).
- Distribución de eventos: Necesitamos un canal por el que distribuir y consumir los eventos que representan el estado de la saga y en base a los cuales nuestro proceso (manager) actuará ejecutando el siguiente step o acción compensatoria según corresponda.
- Idempotencia de las acciones codificadas en los steps: En la medida de lo posible debemos programar las acciones de los steps de forma que sean operaciones idempotentes, de esta manera minimizaremos errores por ejemplo, al reintentar la ejecución de una operación o de una acción compensatoria.
- Posibilidad de ejecución concurrente de steps: habrá casos en los que resulte interesante ejecutar concurrentemente varios steps de una saga por motivos de rendimiento. En estos casos será necesario controlar las dependencias entre steps y las condiciones de carrera que puedan darse. Una manera de evitar estas condiciones de carrera es establecer un punto de serialización de los steps. Podría ser en la propia cola de mensajes o mediante lectura bloqueante en una BBDD donde se almacene el estado de la saga.
Hay varios frameworks que nos ayudan a la hora de implementar sagas, por ejemplo:
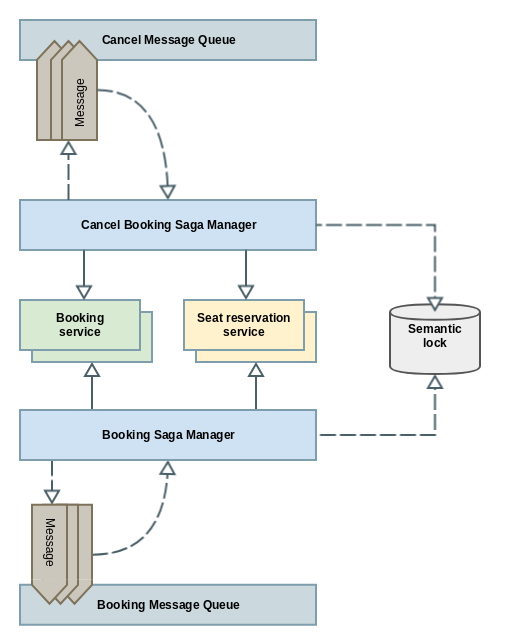
Una última cuestión que debemos tener en cuenta a la hora de trabajar con el patrón saga, es que las sagas no se ejecutan de forma aislada, es decir, es probable que en algún momento se ejecuten de forma concurrente 2 o más sagas que operen sobre el mismo dato. Por ejemplo, una saga para la reserva de vuelo y a la vez otra que está cancelando el mismo vuelo. En este caso se produce lo que en terminología de base de datos se denomina anomalías.
Las anomalías más frecuentes son:
- Lost updates: Sucede cuando una saga ignora un update hecho por otra. Por ejemplo, si la saga de cancelar vuelo ha hecho la cancelación, pero concurrentemente la saga de reservar vuelo ejecuta su lógica y se produce la reserva.
- Dirty reads: Se produce cuando una saga lee un dato que posteriormente va a ser actualizado por otra saga en curso que no ha acabado su ejecución. Por ejemplo, si la saga de reserva de vuelo tiene que comprobar previamente el nº de plaza, obtendrá información erronea si de forma concurrente hay otra saga que estaba en medio de su ejecución y va a acabar modificando el dato.
Para resolver este tipo de situaciones utilizaremos contramedidas:

Una contramedida es una estrategia para manejar las anomalías causadas por la ausencia de aislamiento de la saga (sagas concurrentes accediendo al mismo dato), entendiendo “manejar” como prevenir la inconsistencia o minimizar el impacto en negocio.
Existen varias contramedidas para dar solución a distintas variantes del problema. Entre ellas, la más utilizada es el uso de bloqueos semánticos: El concepto básico es implementar un semáforo para operar sobre el dato. Debemos utilizar para este fin un almacenamiento común y accesible por todas las sagas, ni que decir tiene que este almacenamiento deberá ser lo más eficiente y rápido posible, ya que estaremos serializando los procesos de las sagas y perderemos rendimiento en pro de recrear aislamiento para las sagas (otra vez las gallinas que entran por las que salen...).
En resumen ...
Estos son los aspectos que debemos tener en cuenta a la hora de implementar nuestro patrón saga:
- Este patrón es aplicable para mantener la consistencia de datos en arquitecturas basadas en microservicios.
- Es un patrón stateful y necesitaremos mantener el estado persistente.
- A la hora de implementarlo es aconsejable hacerlo de forma asíncrona basándonos en mensajes.
- Es necesario tener en cuenta la concurrencia de sagas e implementar contramedidas para solucionar las posibles anomalías.
Si te ha gustado, ¡síguenos en Twitter para estar al día de los próximos posts!
Bibliografía:
Microservices Patterns (Chris Richardson)