
Acelerando los desarrollos con contenedores : Infraestructura de Apache Kafka
Publicado por Víctor Madrid el
En este artículo se va a mostrar cómo poder disponer de una infraestructura para Apache Kafka de forma rápida para utilizarla en distintos entornos: locales, desarrollo, integración y QA.

Contexto
En mi caso particular cambio de contexto muy rápido y muchas veces... y la mayoría de las veces cosas que suelen ser totalmente diferentes entre ellas. Con este planteamiento si te gusta guardar TODO (instalaciones, configuraciones, variables de entorno, diferentes versiones, librerías, etc.) lo que utilizas por si lo volverás a utilizar en un futuro y encima lo haces de forma poco organizada lo que sueles tener es ... un super-problema. En muchos casos puede que seas organizado y el problema lo tengas por la forma de instalación de cada producto y de cada versión (Por ejemplo: uso de variables de entorno diferentes)
Este super-problema es lo que yo denomino en broma el "Síndrome de Diógenes del Desarrollo". Es decir, que acabas acumulando en muchos casos ciertos "productos" instalados que muchas veces son exactamente los de fábrica, otras veces no lo son porque usan ficheros de configuración específicos tuyos, disponemos de mucha configuración instalada en la máquina, en algunos casos decidimos incorporación plugin/integraciones extras (oficiales y no oficiales), etc. Al final lo que suele pasar es que esos productos en muchos casos NO funcionan o no como deberían porque tu "manipulación" se lo ha cargado.
Curiosidad sobre el origen de este artículo
En algún momento de mi trabajo dejé mi infraestructura de Kafka local inoperativa, no la corregí en el momento (mal hecho por mi parte o quizás no me di cuenta), cambie de contexto y cuando tiempo después volví ya NO me acordaba que había tocado.
Seguro que much@s os sentís identificad@s con esto...jejeje.
Ante la situación de tener un producto instalado inoperativo siempre surgen 2 opciones:
Opción "Empezar desde 0"
Borrar la instalación y todos sus elementos asociados (temporales, registros, configuración, etc.) NO dejándote nada, instalar la misma versión de la misma manera o la nueva según digan en el manual, configurarlo todo otra vez a como tu quieres, etc.
Todo esto supone volver a dedicar un tiempo muy valioso que ya invertiste una vez y si encima se elige instalar otra versión entonces NO se puede asegurar la total compatibilidad del resto de las cosas que se necesitaban (así que cruzamos los dedos durante su uso...)
Opción "Descubrir el Expediente X"
Investigar los ficheros de configuración, variables de entorno, comparar los ficheros actuales con posibles backups de los originales (si los tienes), revisar los logs para ver posibles errores, etc.
En definitiva, es ver que ha cambiado desde la última vez que lo viste funcionar.
La solución en mi caso fue decidir plantear una solución para que NO volviera a pasarme con la infraestructura de Kafka y para ello decidí plantear mi solución mediante contenedores y así aprovecharme de todas sus ventajas.
Por cierto, además de resolver el caso anterior también me ha ayudado para solucionar otros "problemas" como:
- Cambiar de portátil (mismo entorno o diferente entorno) y por lo tanto era necesario volver a montar la infraestructura Kafka
- Probar otra nueva versión de Kafka y sus componentes para ver nuevas funcionalidades o resolución de bugs
- Probar algo rápido con alguna configuración específica
- Ayudarme a preparar PoCs rápidas
- Etc.
Este artículo está dividido en 4 partes:
- 1. Introducción
- 2. Stack Tecnológico
- 3. Ejemplos de Uso
- 4. Mejoras
- 5. Conclusiones
1. Introducción
En este apartado se tratarán los siguiente puntos :
- 1.1. Introducción al uso de contenedores como aceleradores del desarrollo
- 1.2. ¿Qué necesidades tenemos para tener una "Infraestructura de Apache Kafka" con contenedores?
1.1. Introducción al uso de contenedores como aceleradores del desarrollo
Para centralizar esta información en un único punto y así poder facilitar su consulta se ha diseñado un artículo específico
1.2. ¿Qué necesidades tenemos para requerir una "Infraestructura de Apache Kafka" con contenedores?
Pueden ser muchos los motivos para querer disponer de una infraestructura de Apache Kafka en local basada en contenedores pero yo voy a describir para lo que yo la he utilizado :
- Disponer de un entorno inmutable
- Entender y diseñar diferentes escenarios tipo
- Aprender a utilizar cada uno de los componentes
- Probar compatibilidad entre componentes
- Probar con diferentes versiones de cada uno de los componentes utilizados y asi verificar nueva funcionalidad o posibles arreglos de bugs
- Probar cambios de configuración sin miedo a romper nada -> "Si se rompe pues lo volvemos a reconstruir"
- Disponer de un entorno de testing con un comportamiento predecible al ser determinista -> "Si te funciona una vez y no cambias nada, te funcionará el resto de las veces"
- Acelerar mis desarrollos de productores y consumidores asegurando su correcta integración con la plataforma
- Etc.
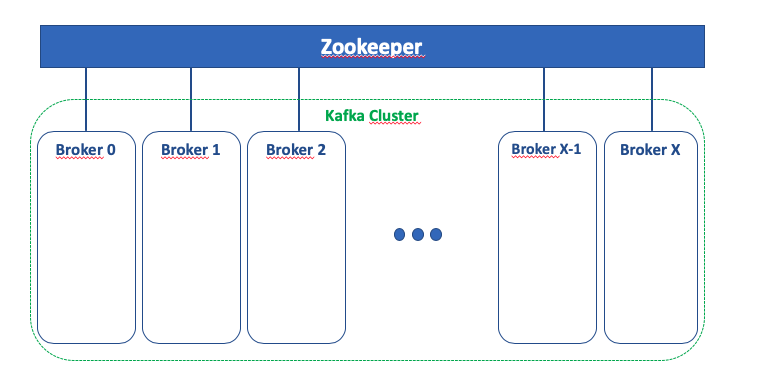
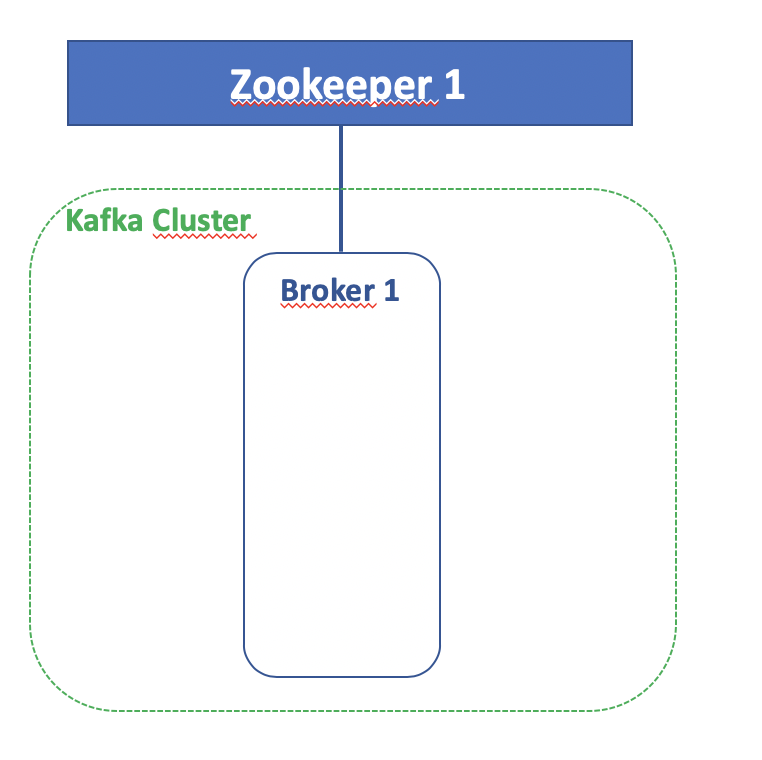
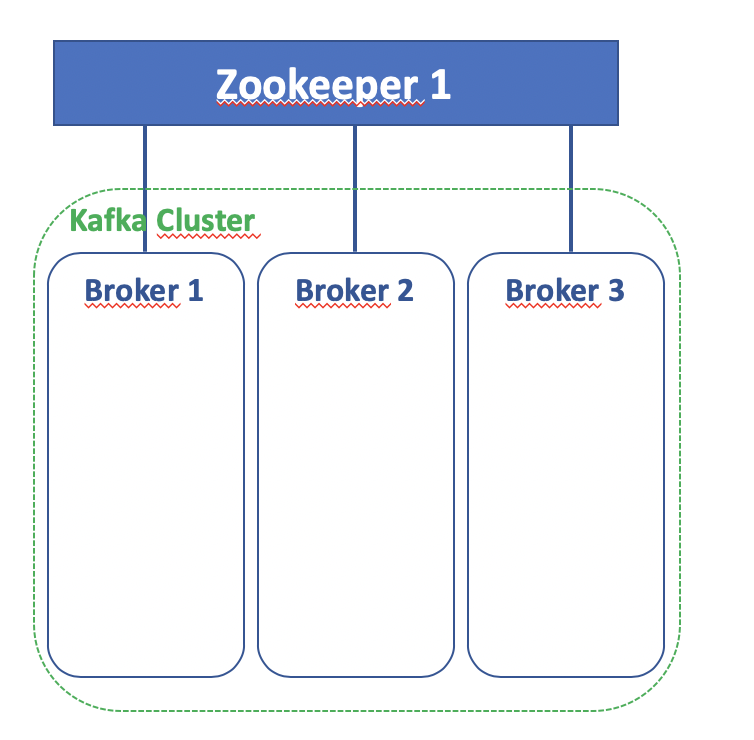
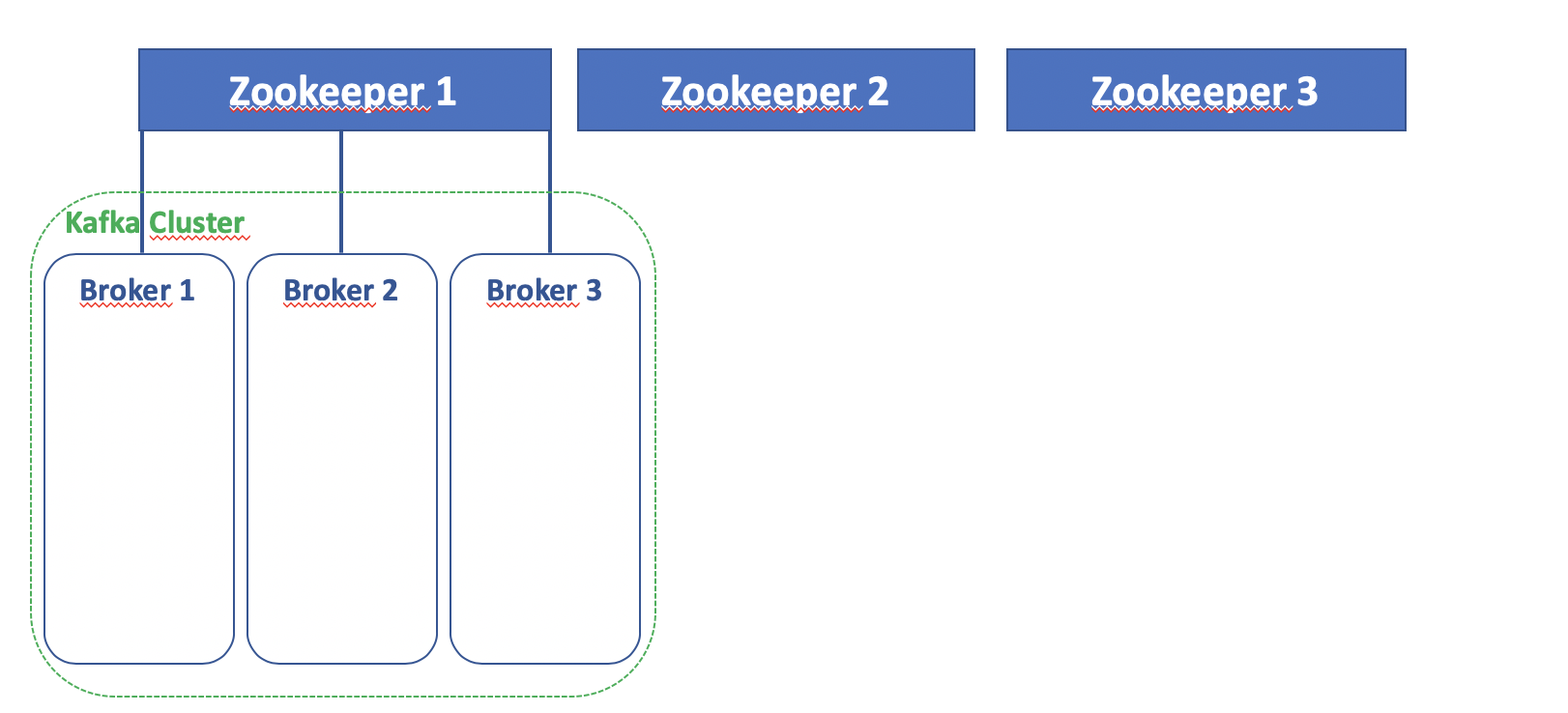
Este es el dagrama de componentes básicos implicados en la infraestructura de Kafka:
2. Stack Tecnológico
Este es stack tecnológico elegido para implementar la funcionalidad "Infraestructura de Apache Kafka":
- Java 8
- Docker - Tecnología de Contenedores/Containers
- Docker Hub - Repositorio de Docker Público donde se ubican las imágenes oficiales
- Zookeeper - Gestor centralizado para componentes distribuidos
- Kafka - Plataforma de Streaming distribuida
3. Ejemplos de Uso
Para enseñar a utilizarlo y así practicar se ha habilitado un repositorio, este repositorio se reutilizará para otros artículos con Kafka.
La parte de que tiene que ver con este artículo se encuentra en el apartado de infrastructure/environment/basic
Se han habilitado diferentes instalaciones de Zookeeper:
- Zookeeper 3.4.9
- Acceso al repositorio GitHub
- Acceso a la Imagen Docker Hub
- CP-Zookeeper 5.5.0
- Acceso al repositorio GitHub
- Acceso a la Imagen Docker Hub
Cada implementación se configurado con diferentes escenarios:
- zk-single-kafka-single : 1 Zookeeper y 1 Broker Kafka
- zk-single-kafka-multiple : 1 Zookeeper y 3 Brokers Kafka
- zk-multiple-kafka-single : 3 Zookeepers y 1 Broker Kafka
- zk-multiple-kafka-multiple : 3 Zookeepers y 3 Brokers Kafka
3.1. Scripts de Soporte
Se han habilitado una primera versión de dos scripts para ayudar a entender y probar los entornos Kafka:
- info-kafka-infrastructure-v1
- test-kafka-infrastructure-v1
Los scripts se ubican en el repositorio
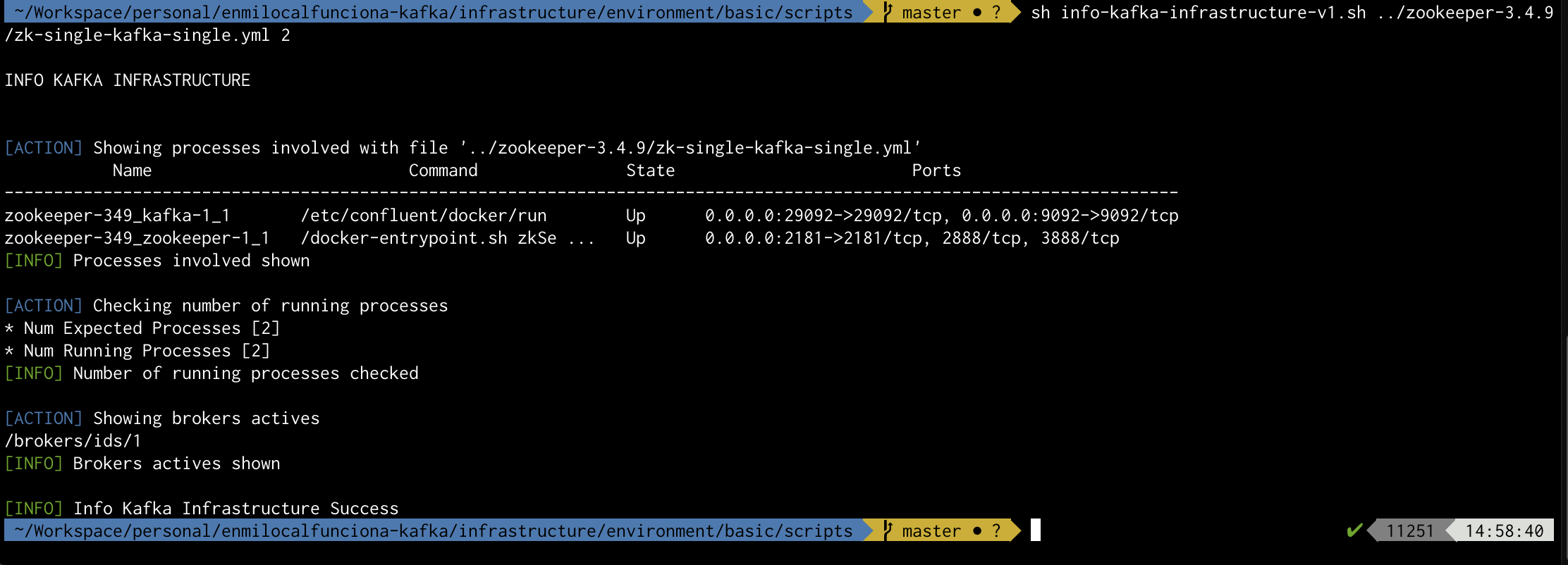
info-kafka-infrastructure-v1
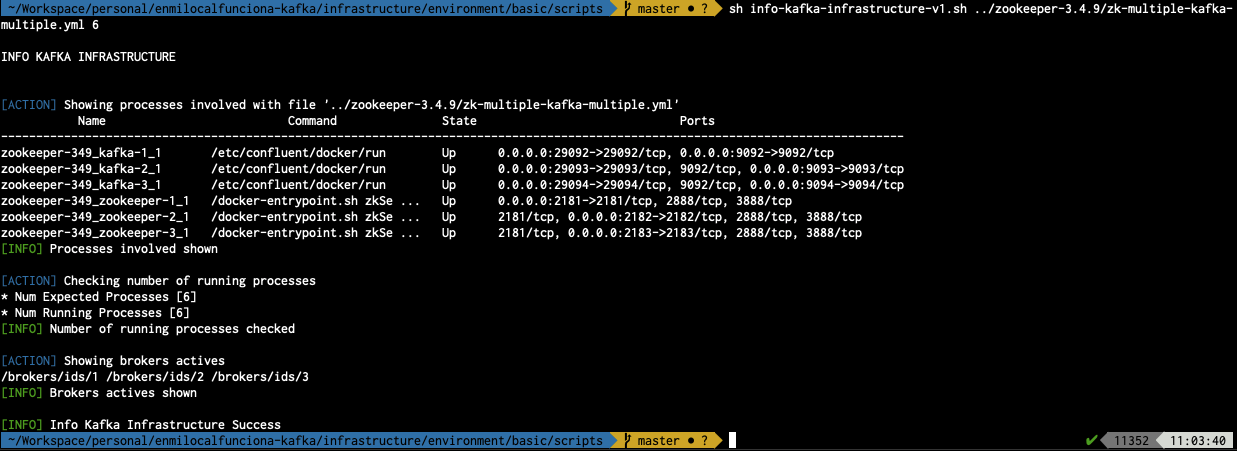
Script informativo utilizado para :
- Mostrar los procesos involucrados en un fichero "docker-compose"
- Validar el nº de procesos ejecutados respecto a un parámetro esperado
- Mostrar los brokers disponibles
Ejemplo de ejecución para el caso zk-single-kafka-single de zookeeper-3.4.9
sh info-kafka-infrastructure-v1.sh ../zookeeper-3.4.9/zk-single-kafka-single.yml 2
Nota: Requiere que la infraestructura elegida se encuentre arrancada
El primer parámetro se corresponde con el fichero docker-compose con el que se quiere trabajar.
El segundo parámetro establece el nº de procesos esperados durante su ejecución.
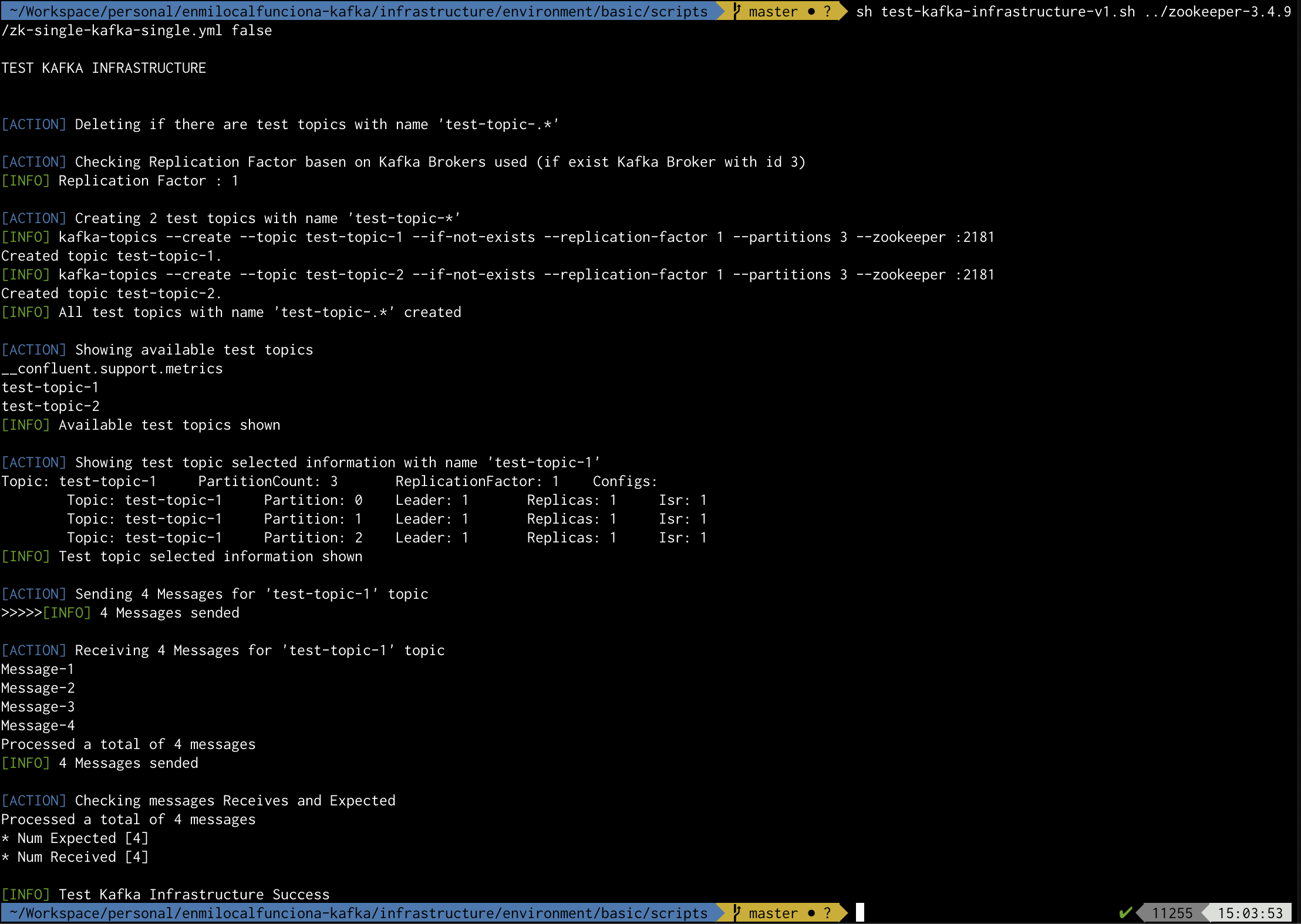
test-kafka-infrastructure-v1
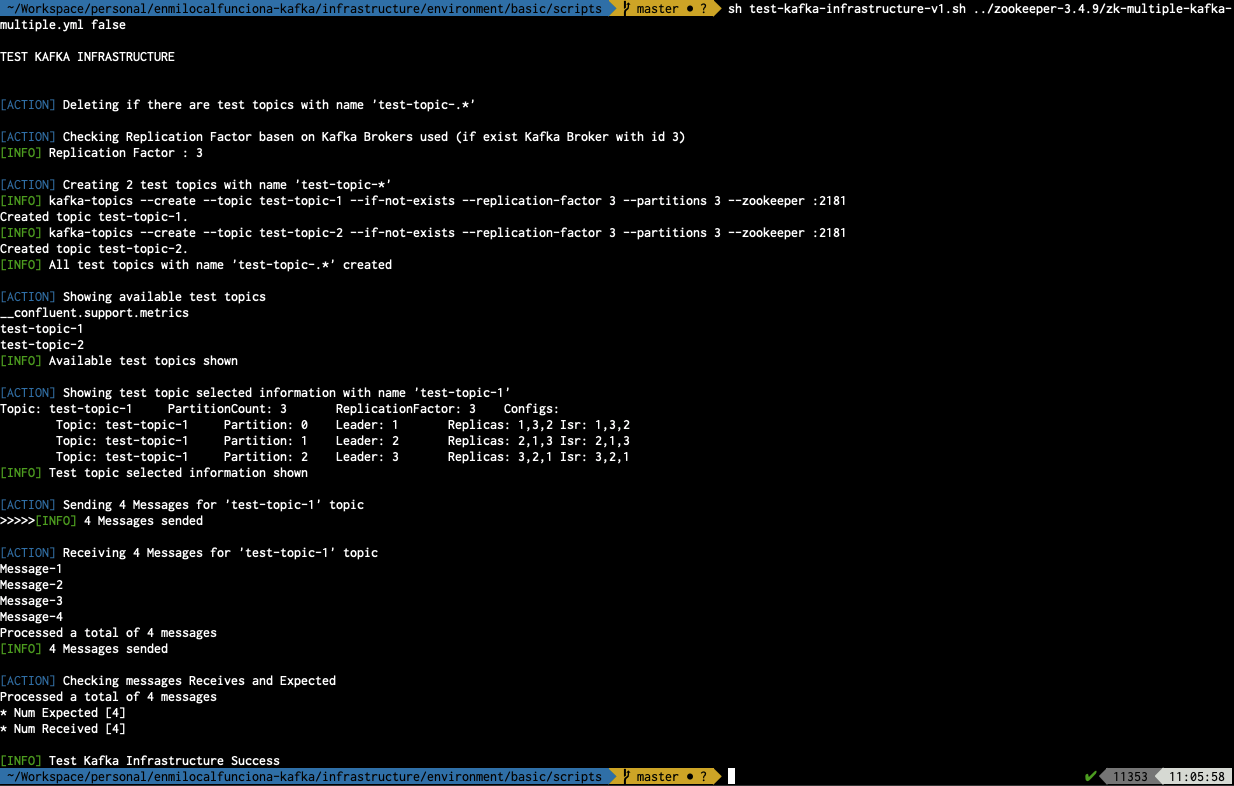
Script de testing de la infraestructura utilizado para:
- Probar la creación y eliminación de topics
- Probar el envío de mensajes
- Probar la recepción de mensajes
- Validar el número de mensajes recibidos para validar la prueba
Ejemplo de ejecución para el caso zk-single-kafka-single de zookeeper-3.4.9
sh test-kafka-infrastructure-v1.sh ../zookeeper-3.4.9/zk-single-kafka-single.yml false
Nota : Requiere que la infraestructura elegida se encuentre arrancada
El primer parámetro se corresponde con el fichero docker-compose con el que se quiere trabajar
El segundo parámetro establece si requiere probar a eliminas los topics utilizados durante la prueba de inicio
3.2. Investigar lo que se usa
Cuando uno crea un contenedor basado en una imagen ya se ha visto que consideraciones se debe tener para llegar a entender que es lo que hace.
Si tiene alguna duda vuelve a revisar el apartado "Soporte de Análisis de Contenedores" del artículo de introducción : Acelerando los desarrollos con contenedores: Introducción
Ejemplo de ejecución para mostrar la información de los procesos para el caso zk-single-kafka-single

Ejemplo de inspección de un Broker Kafka (para la anterior ejecución de entorno)
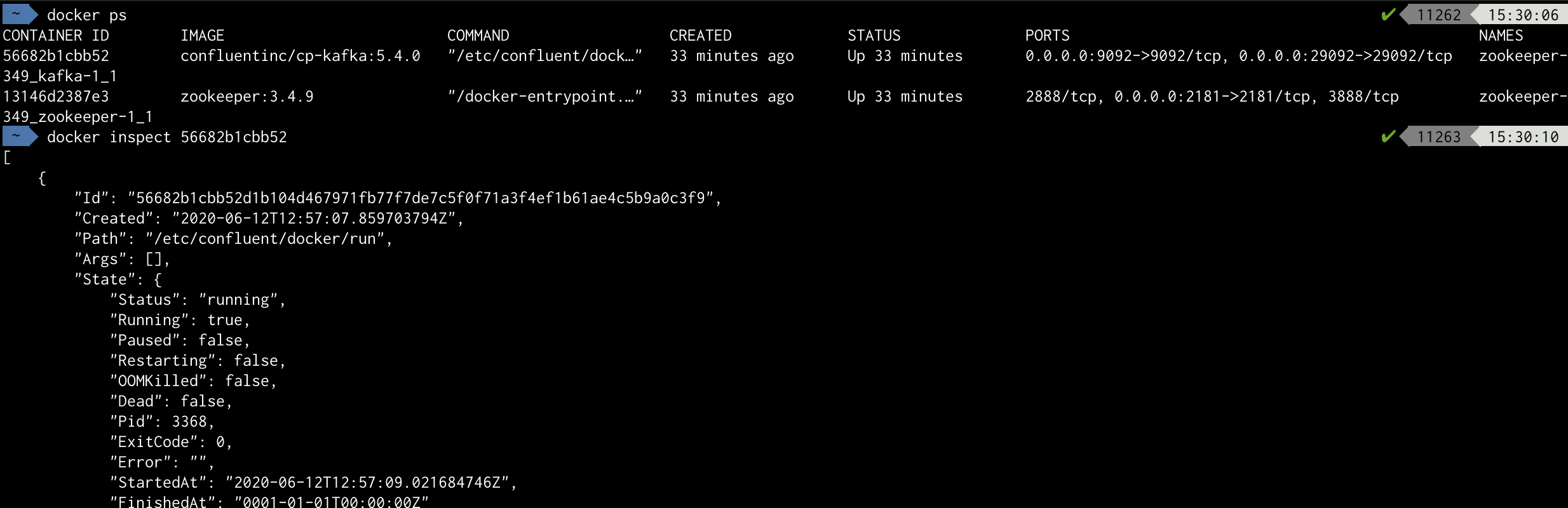
Ejemplo de investigación general dentro del contenedor : Broker Kafka (anterior ejecución de entorno)
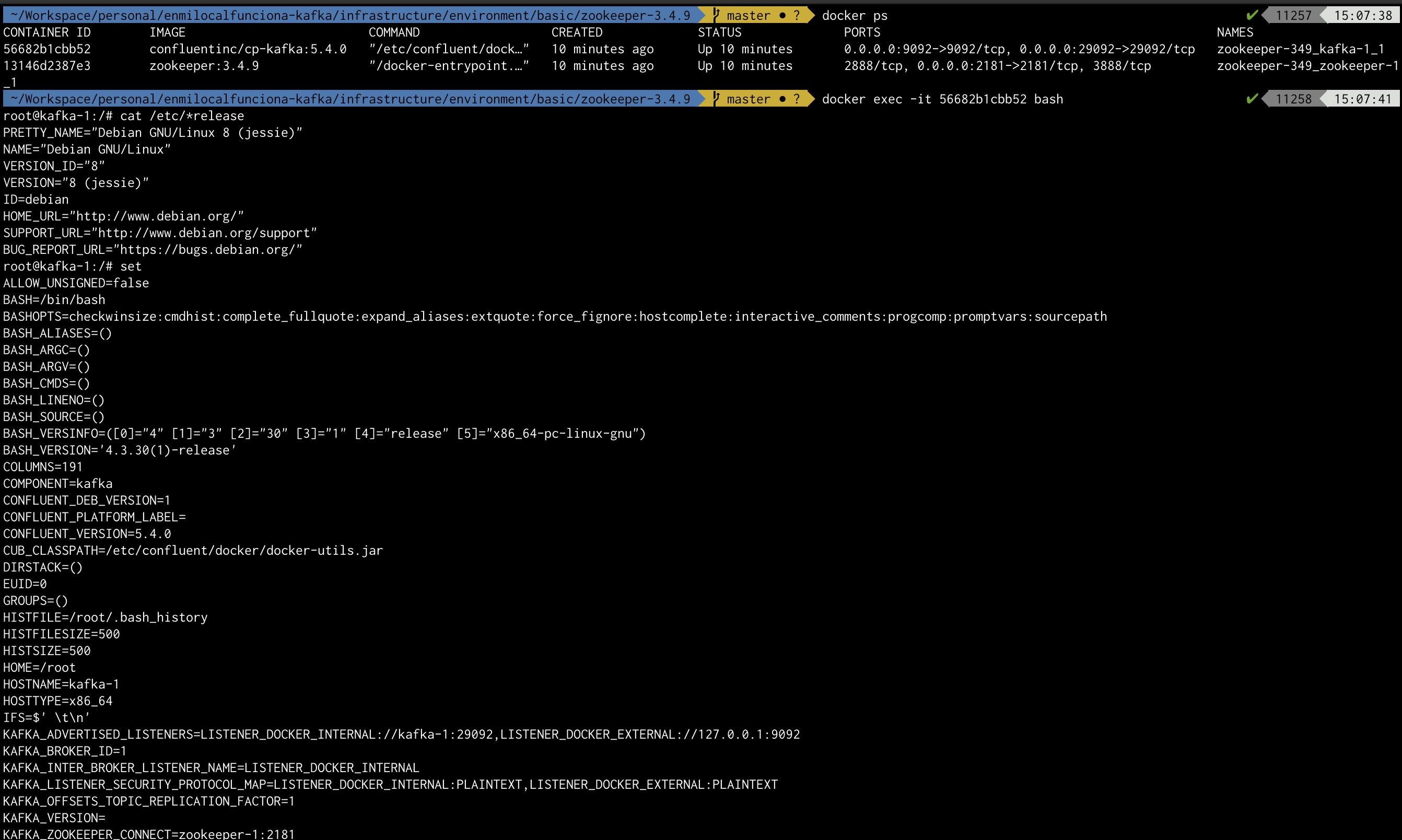
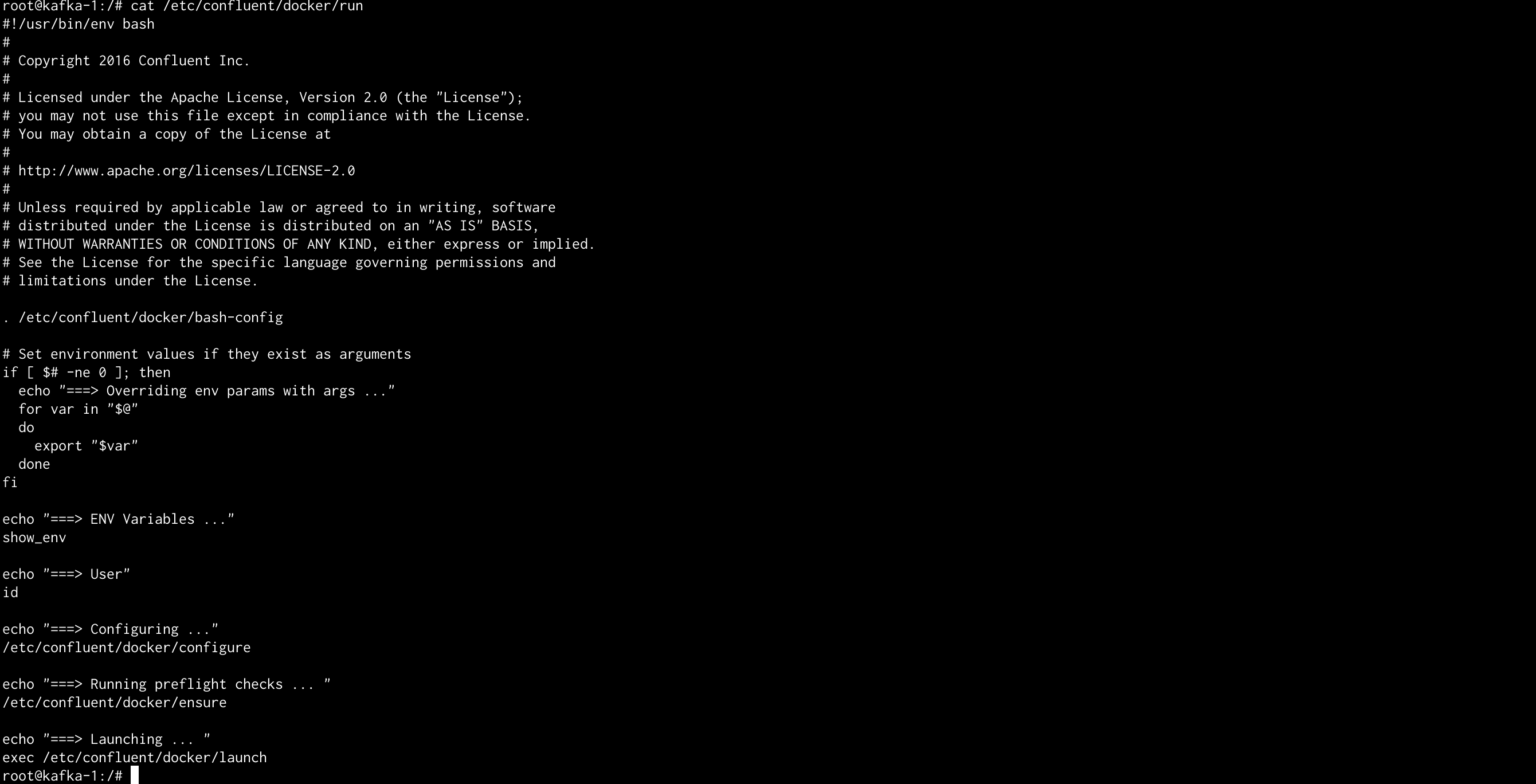
Ejemplo de investigación del comando de ejecución : Broker Kafka (anterior ejecución de entorno)
Ejemplo de investigación del fichero "configure"
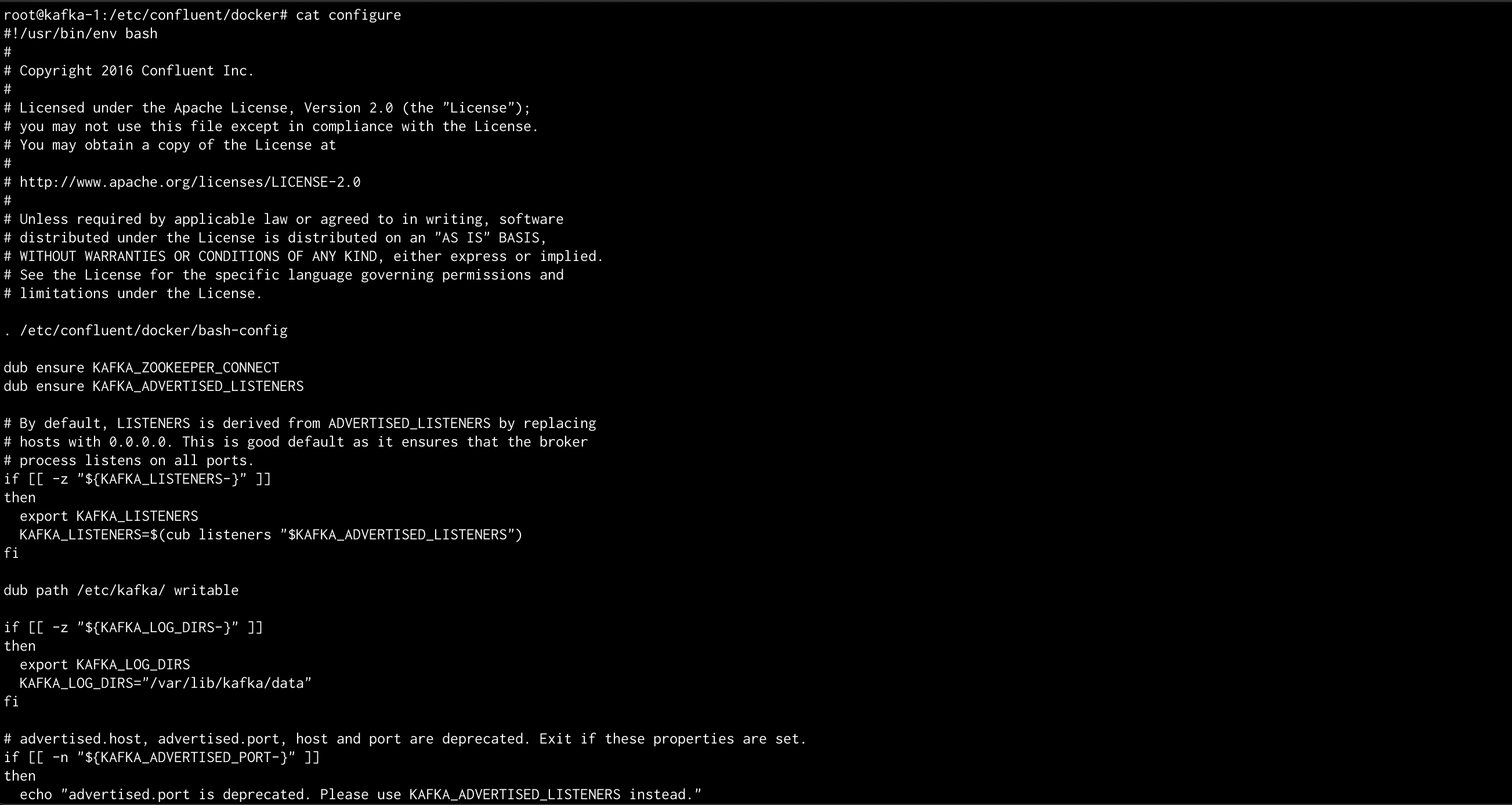
En mi caso esta investigación me ha ayudado a conocer mucho más como están configuradas cada una de las imágenes, ver que valores por defecto utilizan, ver las condiciones que los establecen, ver que cosas no tienen habilitadas, encontrar errores en mi configuración, verificar si la documentación estaba bien o no (un clásico), etc.
Por ejemplo, un punto que me costo mucho sacar es el de la configuración de múltiples Zookeepers que difería de una implementación a otra
- Para la imagen de Zookeeper original la configuración mediante variables de entorno era :
ZOO_SERVERS: server.1=zookeeper-1:2888:3888 server.2=zookeeper-2:2888:3888 server.3=zookeeper-3:2888:3888
- Para la imagen de Zookeeper proporcionada por Confluent la configuración mediante variables de entorno era :
ZOOKEEPER_SERVERS: zookeeper-1:2888:3888;zookeeper-2:2888:3888;zookeeper-3:2888:3888
Cambiaba el nombre de la variable utiliza, la forma de estructurar múltiples valores y la forma de representar cada propio valor.
3.3. Escenarios
Estos son los escenarios con los que se trabaja :
- zk-single-kafka-single : 1 Zookeeper y 1 Broker Kafka
- zk-single-kafka-multiple : 1 Zookeeper y 3 Brokers Kafka
- zk-multiple-kafka-single : 3 Zookeepers y 1 Broker Kafka
- zk-multiple-kafka-multiple : 3 Zookeepers y 3 Brokers Kafka
Cada uno de los escenarios se define mediante un fichero docker.compose.yml donde se define:
- La implementación de Zookeeper y su versión
- La implementación de un Broker Kafka y su versión
- La configuración de ambos componentes vía variables de entorno
- El mapeo de puertos de ambos hacia el exterior
- El mapeo de los volumenes para el acceso y persistencia sobre la configuración, logs etc
Nota :
Se han realizado las pruebas de escenario para la implementación zookeeper-3.4.9 pero tiene un comportamiento similar para la implementacion cp-zookeeper-5.0.0
zk-single-kafka-single
Se compone de un 1 Zookeeper y 1 Broker Kafka
- Objetivo: Escenario básico y más utilizado para pruebas rápidas y desarrollos de poca complejidad
Fichero docker-compose.yml utilizado
version: '3'
services:
zookeeper-1:
image: zookeeper:3.4.9
hostname: zookeeper-1
environment:
ZOO_MY_ID: 1
ZOO_PORT: 2181
ZOO_SERVERS: server.1=zookeeper-1:2888:3888
# ZOO_LOG4J_PROP: "INFO,CONSOLE,ROLLINGFILE" -- No Include
ports:
- "2181:2181"
volumes:
- ./zk-single-kafka-single/zookeeper-1/conf:/conf
- ./zk-single-kafka-single/zookeeper-1/logs:/logs
- ./zk-single-kafka-single/zookeeper-1/data:/data
- ./zk-single-kafka-single/zookeeper-1/datalog:/datalog
kafka-1:
image: confluentinc/cp-kafka:5.4.0
hostname: kafka-1
environment:
KAFKA_BROKER_ID: 1
KAFKA_ZOOKEEPER_CONNECT: "zookeeper-1:2181"
KAFKA_ADVERTISED_LISTENERS: LISTENER_DOCKER_INTERNAL://kafka-1:29092,LISTENER_DOCKER_EXTERNAL://${DOCKER_HOST_IP:-127.0.0.1}:9092
KAFKA_LISTENER_SECURITY_PROTOCOL_MAP: LISTENER_DOCKER_INTERNAL:PLAINTEXT,LISTENER_DOCKER_EXTERNAL:PLAINTEXT
KAFKA_INTER_BROKER_LISTENER_NAME: LISTENER_DOCKER_INTERNAL
KAFKA_LOG4J_ROOT_LOGLEVEL: INFO
# KAFKA_LOG4J_LOGGERS: "kafka.controller=INFO,kafka.producer.async.DefaultEventHandler=INFO,state.change.logger=INFO"
KAFKA_OFFSETS_TOPIC_REPLICATION_FACTOR: 1
ports:
- "9092:9092"
- "29092:29092"
volumes:
- ./zk-single-kafka-single/kafka-1/logs:/var/log/kafka
- ./zk-single-kafka-single/kafka-1/data:/var/lib/kafka/data
depends_on:
- zookeeper-1
Comando para arrancar el escenario:
docker-compose -f zk-single-kafka-single.yml up -d
- -f : Indica el fichero que ejecutará
- -d : Ejecuta los contenedores en modo background
Comando para parar el escenario:
docker-compose -f zk-single-kafka-single.yml down
Comando de ejecución para info-kafka-infrastructure-v1
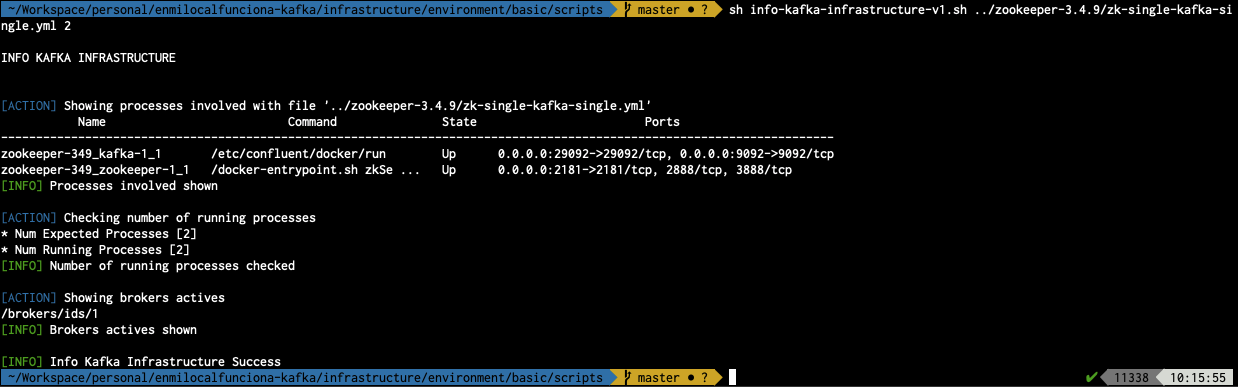
sh info-kafka-infrastructure-v1.sh ../zookeeper-3.4.9/zk-single-kafka-single.yml 2
- ../zookeeper-3.4.9/zk-single-kafka-single.yml : Fichero de configuración utilizado
- false : Parámetro que indica si tiene que eliminar de inicio los topics utilizados durante la prueba (En este caso al ser false NO lo debería hacer)
Comando de ejecución para test-kafka-infrastructure-v1:
sh test-kafka-infrastructure-v1.sh ../zookeeper-3.4.9/zk-single-kafka-single.yml false
- ../zookeeper-3.4.9/zk-single-kafka-single.yml: Fichero de configuración utilizado
- false: Parámetro que indica si tiene que eliminar de inicio los topics utilizados durante la prueba (En este caso al ser false NO lo debería hacer)
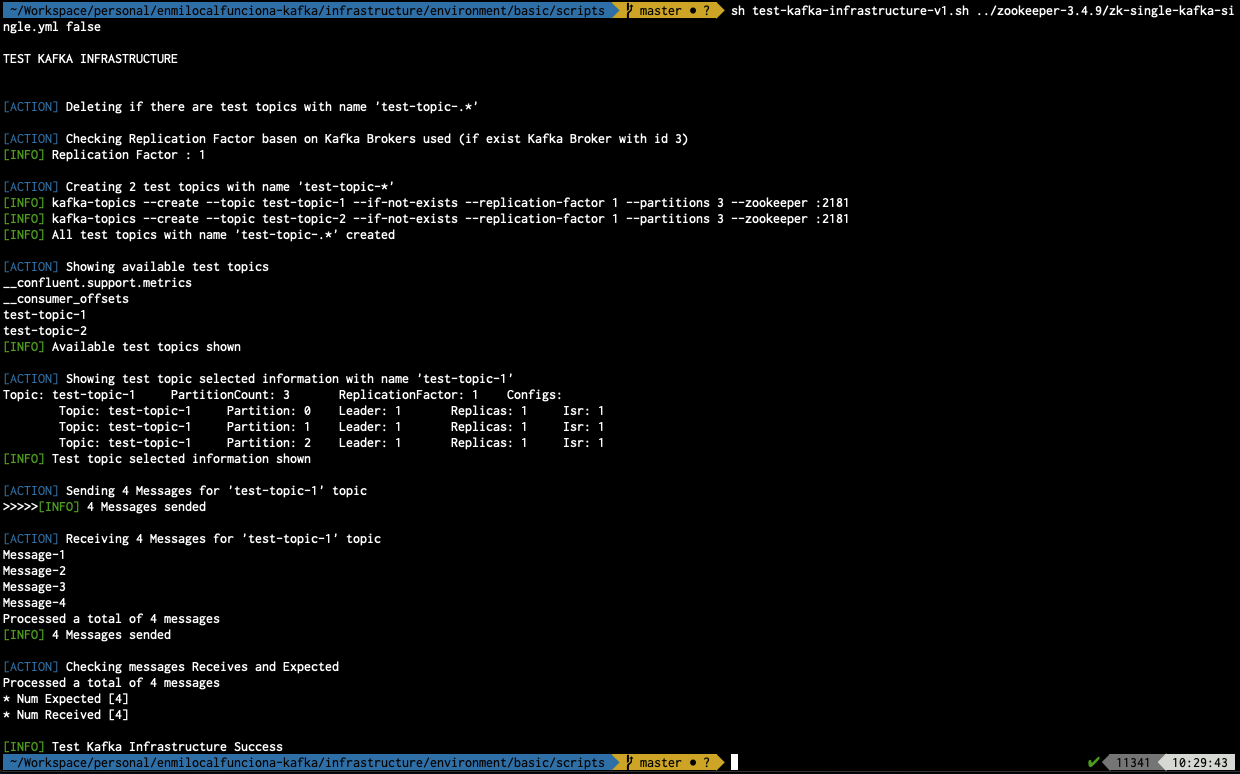
De esta forma queda comprobado el correcto funcionamiento del escenario.
zk-single-kafka-multiple
Se compone de un 1 Zookeeper y 3 Brokers Kafka:
- Objetivo: Escenario que al disponer de varios Brokers facilita desarrollar/probar aspectos relacionados con la replicación y la tolerancia a fallos
Fichero docker-compose.yml utilizado
version: '3'
services:
zookeeper-1:
image: zookeeper:3.4.9
hostname: zookeeper-1
environment:
ZOO_MY_ID: 1
ZOO_PORT: 2181
ZOO_SERVERS: server.1=zookeeper-1:2888:3888
# ZOO_LOG4J_PROP: "INFO,CONSOLE,ROLLINGFILE" -- No Include
ports:
- "2181:2181"
volumes:
- ./zk-single-kafka-multiple/zookeeper-1/conf:/conf
- ./zk-single-kafka-multiple/zookeeper-1/logs:/logs
- ./zk-single-kafka-multiple/zookeeper-1/data:/data
- ./zk-single-kafka-multiple/zookeeper-1/datalog:/datalog
kafka-1:
image: confluentinc/cp-kafka:5.4.0
hostname: kafka-1
environment:
KAFKA_BROKER_ID: 1
KAFKA_ZOOKEEPER_CONNECT: "zookeeper-1:2181"
KAFKA_ADVERTISED_LISTENERS: LISTENER_DOCKER_INTERNAL://kafka-1:29092,LISTENER_DOCKER_EXTERNAL://${DOCKER_HOST_IP:-127.0.0.1}:9092
KAFKA_LISTENER_SECURITY_PROTOCOL_MAP: LISTENER_DOCKER_INTERNAL:PLAINTEXT,LISTENER_DOCKER_EXTERNAL:PLAINTEXT
KAFKA_INTER_BROKER_LISTENER_NAME: LISTENER_DOCKER_INTERNAL
# KAFKA_LOG4J_LOGGERS: "kafka.controller=INFO,kafka.producer.async.DefaultEventHandler=INFO,state.change.logger=INFO"
KAFKA_OFFSETS_TOPIC_REPLICATION_FACTOR: 1
ports:
- "9092:9092"
- "29092:29092"
volumes:
- ./zk-single-kafka-multiple/kafka-1/logs:/var/log/kafka
- ./zk-single-kafka-multiple/kafka-1/data:/var/lib/kafka/data
depends_on:
- zookeeper-1
kafka-2:
image: confluentinc/cp-kafka:5.4.0
hostname: kafka-2
environment:
KAFKA_BROKER_ID: 2
KAFKA_ZOOKEEPER_CONNECT: "zookeeper-1:2181"
KAFKA_ADVERTISED_LISTENERS: LISTENER_DOCKER_INTERNAL://kafka-2:29093,LISTENER_DOCKER_EXTERNAL://${DOCKER_HOST_IP:-127.0.0.1}:9093
KAFKA_LISTENER_SECURITY_PROTOCOL_MAP: LISTENER_DOCKER_INTERNAL:PLAINTEXT,LISTENER_DOCKER_EXTERNAL:PLAINTEXT
KAFKA_INTER_BROKER_LISTENER_NAME: LISTENER_DOCKER_INTERNAL
# KAFKA_LOG4J_LOGGERS: "kafka.controller=INFO,kafka.producer.async.DefaultEventHandler=INFO,state.change.logger=INFO"
KAFKA_OFFSETS_TOPIC_REPLICATION_FACTOR: 1
ports:
- "9093:9093"
- "29093:29093"
volumes:
- ./zk-single-kafka-multiple/kafka-2/logs:/var/log/kafka
- ./zk-single-kafka-multiple/kafka-2/data:/var/lib/kafka/data
depends_on:
- zookeeper-1
kafka-3:
image: confluentinc/cp-kafka:5.4.0
hostname: kafka-3
environment:
KAFKA_BROKER_ID: 3
KAFKA_ZOOKEEPER_CONNECT: "zookeeper-1:2181"
KAFKA_ADVERTISED_LISTENERS: LISTENER_DOCKER_INTERNAL://kafka-3:29094,LISTENER_DOCKER_EXTERNAL://${DOCKER_HOST_IP:-127.0.0.1}:9094
KAFKA_LISTENER_SECURITY_PROTOCOL_MAP: LISTENER_DOCKER_INTERNAL:PLAINTEXT,LISTENER_DOCKER_EXTERNAL:PLAINTEXT
KAFKA_INTER_BROKER_LISTENER_NAME: LISTENER_DOCKER_INTERNAL
# KAFKA_LOG4J_LOGGERS: "kafka.controller=INFO,kafka.producer.async.DefaultEventHandler=INFO,state.change.logger=INFO"
KAFKA_OFFSETS_TOPIC_REPLICATION_FACTOR: 1
ports:
- "9094:9094"
- "29094:29094"
volumes:
- ./zk-single-kafka-multiple/kafka-3/logs:/var/log/kafka
- ./zk-single-kafka-multiple/kafka-3/data:/var/lib/kafka/data
depends_on:
- zookeeper-1
Comando para arrancar el escenario
docker-compose -f zk-single-kafka-multiple.yml up -d
- -f : Indica el fichero que ejecutará
- -d : Ejecuta los contenedores en modo background
Comando para parar el escenario
docker-compose -f zk-single-kafka-multiple.yml down
Comando de ejecución para info-kafka-infrastructure-v1
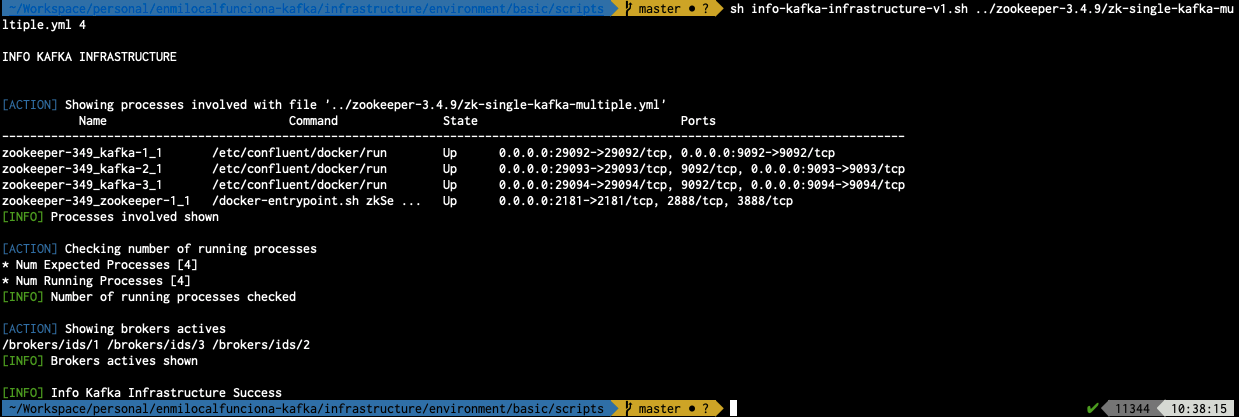
sh info-kafka-infrastructure-v1.sh ../zookeeper-3.4.9/zk-single-kafka-multiple.yml 4
- ../zookeeper-3.4.9/zk-single-kafka-multiple.yml : Fichero de configuración utilizado
- 4 : Parámetro que indica el número de procesos arrancados (uno por componente)
Comando de ejecución para test-kafka-infrastructure-v1
sh test-kafka-infrastructure-v1.sh ../zookeeper-3.4.9/zk-single-kafka-multiple.yml false
- ../zookeeper-3.4.9/zk-single-kafka-multiple.yml : Fichero de configuración utilizado
- false : Parámetro que indica el número de procesos arrancados (uno por componente)
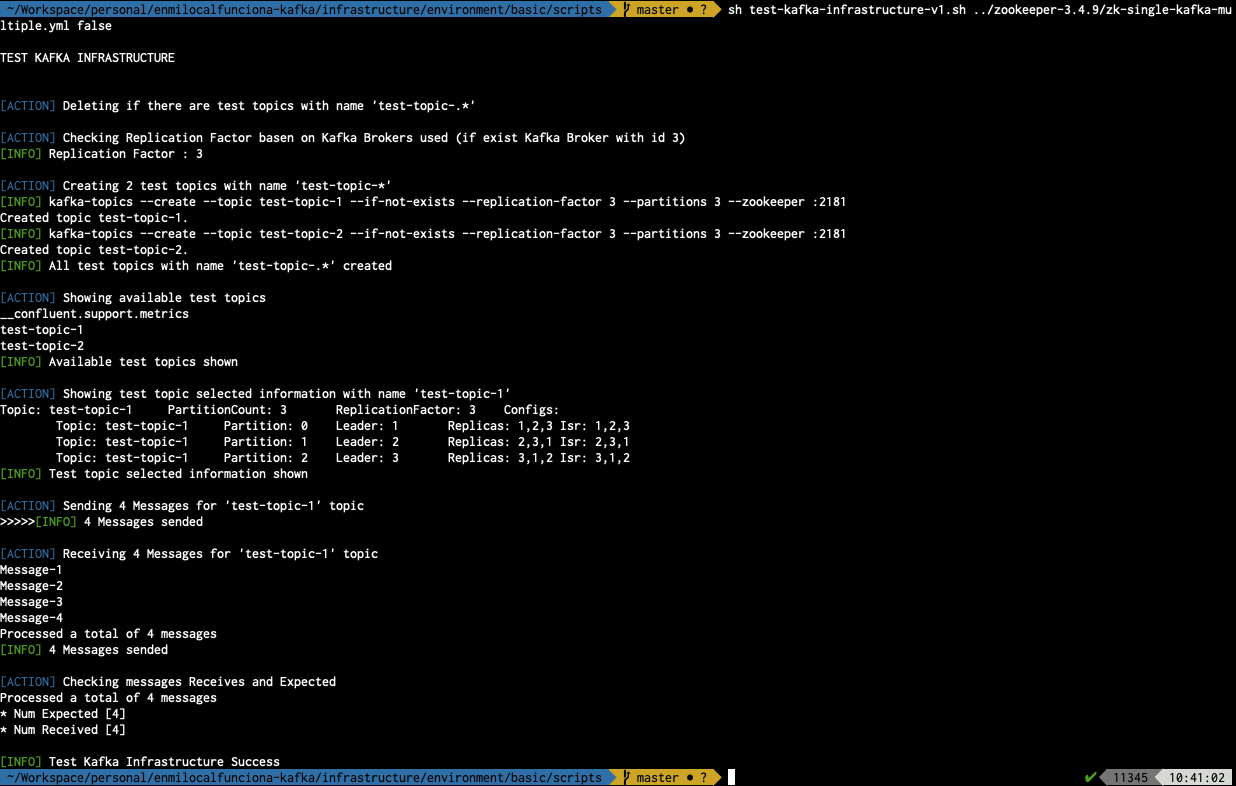
De esta forma queda comprobado el correcto funcionamiento del escenario
zk-multiple-kafka-single
Se compone de 3 Zookeepers y 1 Broker Kafka:
- Objetivo : Escenario que al disponer de varios Zookeepers facilita desarrollar/probar aspectos relacionados su tolerancia a fallos
Fichero docker-compose.yml utilizado
version: '3'
services:
zookeeper-1:
image: zookeeper:3.4.9
hostname: zookeeper-1
environment:
ZOO_MY_ID: 1
ZOO_PORT: 2181
ZOO_SERVERS: server.1=zookeeper-1:2888:3888 server.2=zookeeper-2:2888:3888 server.3=zookeeper-3:2888:3888
# ZOO_LOG4J_PROP: "INFO,CONSOLE,ROLLINGFILE" -- No Include
ports:
- "2181:2181"
volumes:
- ./zk-multiple-kafka-single/zookeeper-1/conf:/conf
- ./zk-multiple-kafka-single/zookeeper-1/logs:/logs
- ./zk-multiple-kafka-single/zookeeper-1/data:/data
- ./zk-multiple-kafka-single/zookeeper-1/datalog:/datalog
zookeeper-2:
image: zookeeper:3.4.9
hostname: zookeeper-2
environment:
ZOO_MY_ID: 2
ZOO_PORT: 2182
ZOO_SERVERS: server.1=zookeeper-1:2888:3888 server.2=zookeeper-2:2888:3888 server.3=zookeeper-3:2888:3888
# ZOO_LOG4J_PROP: "INFO,CONSOLE,ROLLINGFILE" -- No Include
ports:
- "2182:2182"
volumes:
- ./zk-multiple-kafka-single/zookeeper-2/conf:/conf
- ./zk-multiple-kafka-single/zookeeper-2/logs:/logs
- ./zk-multiple-kafka-single/zookeeper-2/data:/data
- ./zk-multiple-kafka-single/zookeeper-2/datalog:/datalog
zookeeper-3:
image: zookeeper:3.4.9
hostname: zookeeper-3
ports:
- "2183:2183"
environment:
ZOO_MY_ID: 3
ZOO_PORT: 2183
ZOO_SERVERS: server.1=zookeeper-1:2888:3888 server.2=zookeeper-2:2888:3888 server.3=zookeeper-3:2888:3888
# ZOO_LOG4J_PROP: "INFO,CONSOLE,ROLLINGFILE" -- No Include
volumes:
- ./zk-multiple-kafka-single/zookeeper-3/conf:/conf
- ./zk-multiple-kafka-single/zookeeper-3/logs:/logs
- ./zk-multiple-kafka-single/zookeeper-3/data:/data
- ./zk-multiple-kafka-single/zookeeper-3/datalog:/datalog
kafka-1:
image: confluentinc/cp-kafka:5.4.0
hostname: kafka-1
environment:
KAFKA_BROKER_ID: 1
KAFKA_ZOOKEEPER_CONNECT: "zookeeper-1:2181,zookeeper-2:2182,zookeeper-3:2183"
KAFKA_ADVERTISED_LISTENERS: LISTENER_DOCKER_INTERNAL://kafka-1:29092,LISTENER_DOCKER_EXTERNAL://${DOCKER_HOST_IP:-127.0.0.1}:9092
KAFKA_LISTENER_SECURITY_PROTOCOL_MAP: LISTENER_DOCKER_INTERNAL:PLAINTEXT,LISTENER_DOCKER_EXTERNAL:PLAINTEXT
KAFKA_INTER_BROKER_LISTENER_NAME: LISTENER_DOCKER_INTERNAL
# KAFKA_LOG4J_LOGGERS: "kafka.controller=INFO,kafka.producer.async.DefaultEventHandler=INFO,state.change.logger=INFO"
KAFKA_OFFSETS_TOPIC_REPLICATION_FACTOR: 1
ports:
- "9092:9092"
- "29092:29092"
volumes:
- ./zk-multiple-kafka-single/kafka-1/logs:/var/log/kafka
- ./zk-multiple-kafka-single/kafka-1/data:/var/lib/kafka/data
depends_on:
- zookeeper-1
- zookeeper-2
- zookeeper-3
Comando para arrancar el escenario:
docker-compose -f zk-multiple-kafka-single.yml up -d
- -f : Indica el fichero que ejecutara
- -d : Ejecuta los contenedores en modo background
Comando para parar el escenario:
docker-compose -f zk-multiple-kafka-single.yml down
Comando de ejecución para info-kafka-infrastructure-v1:
sh info-kafka-infrastructure-v1.sh ../zookeeper-3.4.9/zk-multiple-kafka-single.yml 4
- ../zookeeper-3.4.9/zk-multiple-kafka-single.yml : Fichero de configuración utilizado
- 4 : Parámetro que indica el número de procesos arrancados (uno por componente)
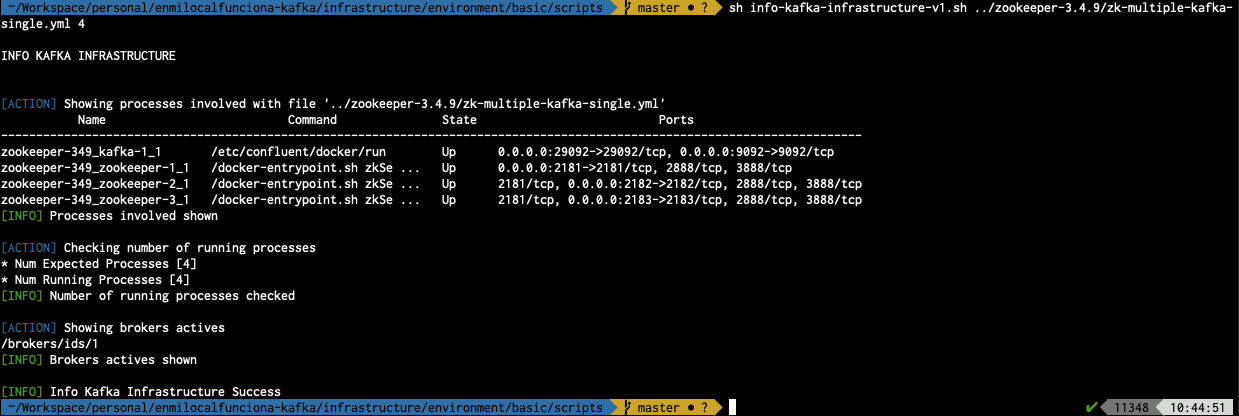
Comando de ejecución para test-kafka-infrastructure-v1
sh test-kafka-infrastructure-v1.sh ../zookeeper-3.4.9/zk-multiple-kafka-single.yml false
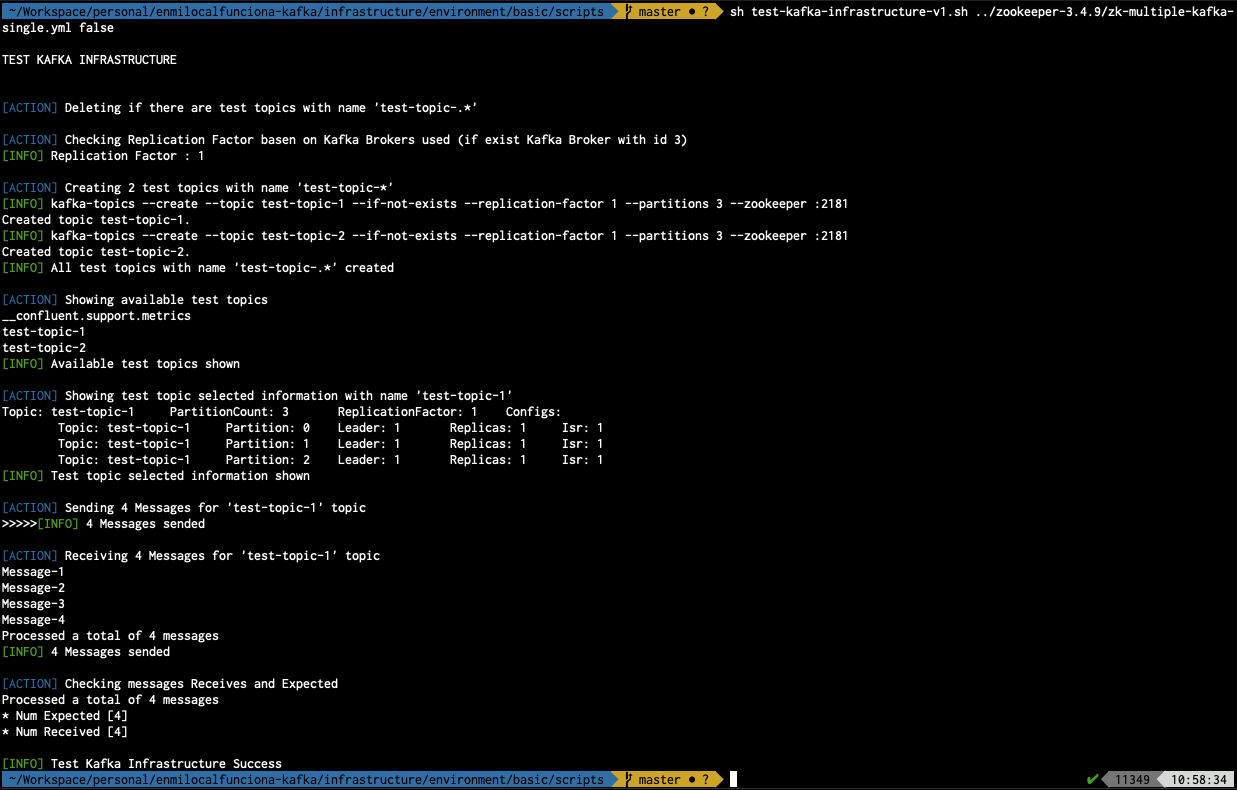
De esta forma queda comprobado el correcto funcionamiento del escenario.
zk-multiple-kafka-multiple
Se compone de 3 Zookeepers y 3 Brokers Kafka:
- Objetivo: Escenario que al disponer de varios de todo puede parecerse más a lo utilizado en un entorno de producción
Fichero docker-compose.yml utilizado
version: '3'
services:
zookeeper-1:
image: zookeeper:3.4.9
hostname: zookeeper-1
environment:
ZOO_MY_ID: 1
ZOO_PORT: 2181
ZOO_SERVERS: server.1=zookeeper-1:2888:3888 server.2=zookeeper-2:2888:3888 server.3=zookeeper-3:2888:3888
# ZOO_LOG4J_PROP: "INFO,CONSOLE,ROLLINGFILE" -- No Include
ports:
- "2181:2181"
volumes:
- ./zk-multiple-kafka-multiple/zookeeper-1/conf:/conf
- ./zk-multiple-kafka-multiple/zookeeper-1/logs:/logs
- ./zk-multiple-kafka-multiple/zookeeper-1/data:/data
- ./zk-multiple-kafka-multiple/zookeeper-1/datalog:/datalog
zookeeper-2:
image: zookeeper:3.4.9
hostname: zookeeper-2
environment:
ZOO_MY_ID: 2
ZOO_PORT: 2182
ZOO_SERVERS: server.1=zookeeper-1:2888:3888 server.2=zookeeper-2:2888:3888 server.3=zookeeper-3:2888:3888
# ZOO_LOG4J_PROP: "INFO,CONSOLE,ROLLINGFILE" -- No Include
ports:
- "2182:2182"
volumes:
- ./zk-multiple-kafka-multiple/zookeeper-2/conf:/conf
- ./zk-multiple-kafka-multiple/zookeeper-2/logs:/logs
- ./zk-multiple-kafka-multiple/zookeeper-2/data:/data
- ./zk-multiple-kafka-multiple/zookeeper-2/datalog:/datalog
zookeeper-3:
image: zookeeper:3.4.9
hostname: zookeeper-3
ports:
- "2183:2183"
environment:
ZOO_MY_ID: 3
ZOO_PORT: 2183
ZOO_SERVERS: server.1=zookeeper-1:2888:3888 server.2=zookeeper-2:2888:3888 server.3=zookeeper-3:2888:3888
# ZOO_LOG4J_PROP: "INFO,CONSOLE,ROLLINGFILE" -- No Include
volumes:
- ./zk-multiple-kafka-multiple/zookeeper-3/conf:/conf
- ./zk-multiple-kafka-multiple/zookeeper-3/logs:/logs
- ./zk-multiple-kafka-multiple/zookeeper-3/data:/data
- ./zk-multiple-kafka-multiple/zookeeper-3/datalog:/datalog
kafka-1:
image: confluentinc/cp-kafka:5.4.0
hostname: kafka-1
environment:
KAFKA_BROKER_ID: 1
KAFKA_ZOOKEEPER_CONNECT: "zookeeper-1:2181,zookeeper-2:2182,zookeeper-3:2183"
KAFKA_ADVERTISED_LISTENERS: LISTENER_DOCKER_INTERNAL://kafka-1:29092,LISTENER_DOCKER_EXTERNAL://${DOCKER_HOST_IP:-127.0.0.1}:9092
KAFKA_LISTENER_SECURITY_PROTOCOL_MAP: LISTENER_DOCKER_INTERNAL:PLAINTEXT,LISTENER_DOCKER_EXTERNAL:PLAINTEXT
KAFKA_INTER_BROKER_LISTENER_NAME: LISTENER_DOCKER_INTERNAL
# KAFKA_LOG4J_LOGGERS: "kafka.controller=INFO,kafka.producer.async.DefaultEventHandler=INFO,state.change.logger=INFO"
KAFKA_OFFSETS_TOPIC_REPLICATION_FACTOR: 1
ports:
- "9092:9092"
- "29092:29092"
volumes:
- ./zk-multiple-kafka-multiple/kafka-1/logs:/var/log/kafka
- ./zk-multiple-kafka-multiple/kafka-1/data:/var/lib/kafka/data
depends_on:
- zookeeper-1
- zookeeper-2
- zookeeper-3
kafka-2:
image: confluentinc/cp-kafka:5.4.0
hostname: kafka-2
environment:
KAFKA_BROKER_ID: 2
KAFKA_ZOOKEEPER_CONNECT: "zookeeper-1:2181,zookeeper-2:2182,zookeeper-3:2183"
KAFKA_ADVERTISED_LISTENERS: LISTENER_DOCKER_INTERNAL://kafka-2:29093,LISTENER_DOCKER_EXTERNAL://${DOCKER_HOST_IP:-127.0.0.1}:9093
KAFKA_LISTENER_SECURITY_PROTOCOL_MAP: LISTENER_DOCKER_INTERNAL:PLAINTEXT,LISTENER_DOCKER_EXTERNAL:PLAINTEXT
KAFKA_INTER_BROKER_LISTENER_NAME: LISTENER_DOCKER_INTERNAL
# KAFKA_LOG4J_LOGGERS: "kafka.controller=INFO,kafka.producer.async.DefaultEventHandler=INFO,state.change.logger=INFO"
KAFKA_OFFSETS_TOPIC_REPLICATION_FACTOR: 1
ports:
- "9093:9093"
- "29093:29093"
volumes:
- ./zk-multiple-kafka-multiple/kafka-2/logs:/var/log/kafka
- ./zk-multiple-kafka-multiple/kafka-2/data:/var/lib/kafka/data
depends_on:
- zookeeper-1
- zookeeper-2
- zookeeper-3
kafka-3:
image: confluentinc/cp-kafka:5.4.0
hostname: kafka-3
environment:
KAFKA_BROKER_ID: 3
KAFKA_ZOOKEEPER_CONNECT: "zookeeper-1:2181,zookeeper-2:2182,zookeeper-3:2183"
KAFKA_ADVERTISED_LISTENERS: LISTENER_DOCKER_INTERNAL://kafka-3:29094,LISTENER_DOCKER_EXTERNAL://${DOCKER_HOST_IP:-127.0.0.1}:9094
KAFKA_LISTENER_SECURITY_PROTOCOL_MAP: LISTENER_DOCKER_INTERNAL:PLAINTEXT,LISTENER_DOCKER_EXTERNAL:PLAINTEXT
KAFKA_INTER_BROKER_LISTENER_NAME: LISTENER_DOCKER_INTERNAL
# KAFKA_LOG4J_LOGGERS: "kafka.controller=INFO,kafka.producer.async.DefaultEventHandler=INFO,state.change.logger=INFO"
KAFKA_OFFSETS_TOPIC_REPLICATION_FACTOR: 1
ports:
- "9094:9094"
- "29094:29094"
volumes:
- ./zk-multiple-kafka-multiple/kafka-3/logs:/var/log/kafka
- ./zk-multiple-kafka-multiple/kafka-3/data:/var/lib/kafka/data
depends_on:
- zookeeper-1
- zookeeper-2
- zookeeper-3
Comando para arrancar el escenario:
docker-compose -f zk-multiple-kafka-multiple.yml up -d
- -f : Indica el fichero que ejecutara
- -d : Ejecuta los contenedores en modo background
Comando para parar el escenario:
docker-compose -f zk-multiple-kafka-multiple.yml down
Comando de ejecución para info-kafka-infrastructure-v1:
sh info-kafka-infrastructure-v1.sh ../zookeeper-3.4.9/zk-multiple-kafka-multiple.yml 6
- ../zookeeper-3.4.9/zk-multiple-kafka-multiple.yml : Fichero de configuración utilizado
- 6 : Parámetro que indica el número de procesos arrancados (uno por componente)
Comando de ejecución para test-kafka-infrastructure-v1
sh test-kafka-infrastructure-v1.sh ../zookeeper-3.4.9/zk-multiple-kafka-multiple.yml false
De esta forma queda comprobado el correcto funcionamiento del escenario.
3.4. El problema de los volúmenes
Todas las configuraciones de los escenarios realizadas aquí hacen uso de volúmenes de persistencia, de esta forma se permite que la infraestructura mantenga todo aquello que tenía en uso tras caídas inesperadas o provocadas.
Es importante tener en cuanta que cada contenedor utilizado puede hacer uso de algunos volúmenes particulares según lo que se necesite.
¿Qué es volumen en Docker ?
Un volumen en Docker es un objeto específico que define un directorio o un fichero en el Docker Engine y que se monta directamente en el contenedor
En este caso se utiliza para mapear un directorio del contenedor con un directorio de la máquina local.
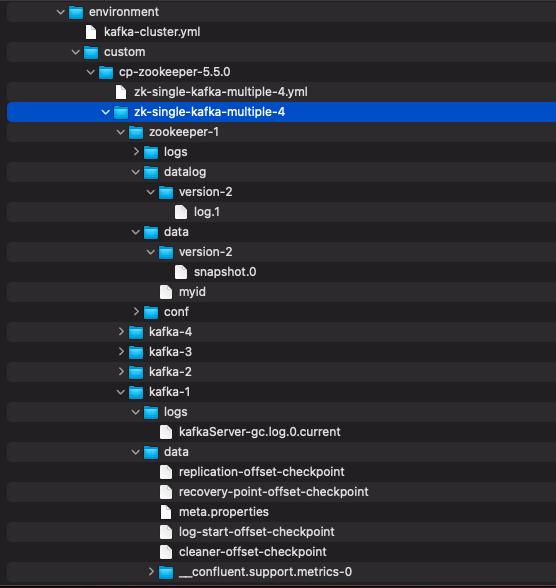
Prácticas utilizadas en los escenarios definidos
En cada escenario se ha establecido que los contenedores registren sus volúmenes mapeados a un mismo directorio local principal.
Este directorio tendrá el nombre del fichero de docker-compose con lo lanza. Por ejemplo : "./zk-single-kafka-multiple/".
Esta decisión proporciona las siguientes características :
- Facilita la centralización -> Todo lo que se genere estará en el mismo sitio
- Facilita la identificación -> Puedo diferenciar este volumen de otros volúmenes de contenedores u otros directorios
- Facilita la ubicación -> Se encuentra próximo al fichero docker-compose gracias a la característica de "./"
Cada uno de los contenedores utilizados y que lo requieran, tendrán sus volúmenes particulares mapeados al anterior directorio principal y a un subdirectorio con el nombre del contenedor. Por ejemplo el broker "kafka-3" del escenario "zk-single-kafka-multiple" registrará sus cosas en "./zk-single-kafka-multiple/kafka-3".
Puede ser que cada contenedor tenga subvolúmenes asociados según aquello que se quiera tener controlado (datos, logs, configuración, etc.). Por ejemplo "./zk-multiple-kafka-multiple/kafka-3/logs"
Se pueden utilizar otros criterios de definición de volúmenes, recordar que los datos aquí contenidos afectan al comportamiento de la infraestructura por lo que es importante tener cuidado.
IMPORTANTE
Recordar eliminar los volúmenes si se quiere resetear toda la instalación y/o configuración.
Ejemplo de mapeo de volúmenes
...
volumes:
- ./zk-multiple-kafka-multiple/kafka-3/logs:/var/log/kafka
- ./zk-multiple-kafka-multiple/kafka-3/data:/var/lib/kafka/data
...
Se mapean unos directorios concretos de dentro del contenedor con unos directorios ubicados en la máquina local que siguen lo que se ha explicado antes.
4. Mejoras
Apartado donde se establecerán posibles mejoras sobre el artículo :
- 4.1. Mejora 1 : Utilizar el productor / consumidor proporcionado por la plataforma
- 4.2. Mejora 2 : Plataforma Web para la gestión de la infraestructura
4.1. Mejora 1 : Utilizar el productor / consumidor proporcionado por la plataforma
Cuando se instala Kafka normalmente se proporciona un directorio con scripts que facilitan la gestión de la infraestructura, de los topics, etc.
Normalmente se ubica en : KAFKA_HOME/bin
- Suelen depender del entorno sobre el que se vaya a utilizar
De entre todos los scripts destacan 2 que pueden ayudar a realizar pruebas rápidas sobre la infraestructura :
- kafka-console-consumer : Consumidor por consola de Kafka
- kafka-console-producer : Productor por consola de Kafka
4.1.1. Arrancar el consumidor por consola (kafka-console-consumer)
//Desde comando si se tiene kafka accesible desde consola (cualquier sistema)
kafka-console-consumer --bootstrap-server localhost:9092 --topic topic-1 --property print.key=true --from-beginning
//Desde script Linux / Mac
sh kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic topic-1 --property print.key=true --from-beginning
./kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic topic-1 --property print.key=true --from-beginning
Los parámetros utilizados son :
- --bootstrap-server : Establece la dirección de los Brokers con los que trabajara
- Se le ha indicado que trabaje con el broker con puertos 9092
- --topic : Establece el nombre del topic con el que trabajará
- --property print.key=true : Mostrará el valor de la key
- --from-beginning : Mostrará el contenido del topic desde el inicio
La consola se quedará "parada" esperando a que se empiece a recibir mensajes.
4.1.2. Arrancar el productor por consola (kafka-console-producer)
//Desde comando si se tiene kafka accesible desde consola (cualquier sistema)
kafka-console-producer --broker-list localhost:9092 --topic topic-1
//Desde script Linux / Mac
sh kafka-console-producer.sh --broker-list localhost:9092 --topic topic-1
./kafka-console-producer.sh --broker-list localhost:9092 --topic topic-1
Los parámetros utilizados son :
- --bootstrap-server : Establece la dirección de los Brokers con los que trabajará
- Se le ha indicado que trabaje con el broker con puertos 9092
- --topic : Establece el nombre del topic con el que trabajará
La consola se quedará "parada" esperando a que se empiece a escribir mensajes.
4.2. Mejora 2 : Plataforma Web para la gestión de la infraestructura
Existen muchas plataformas para la gestión visual de la infraestructura Kafka y aprovechando que tenemos toda la infraestructura montada con contenedores, nos puede resultar relativamente sencillo añadir este componente.
NO es obligatorio su uso pero puede facilitar mucho la vida.
4.2.1. Kafka-Manager
Referencia Docker Hub sheepkiller/kafka-manager
manager:
image: sheepkiller/kafka-manager
ports:
- "9000:9000"
environment:
ZK_HOSTS: zookeeper-1:2181
depends_on:
- zookeeper-1
En nuestro caso utilizaremos otro contenedor con la configuración establecida para apuntar a nuestro Zookeeeper: zookeeper-1:2181
Se habilitará una URL : http://localhost:9000/
Pulsar sobre Cluster -> Add Cluster
- Establecer un nombre
- Establecer la dirección del zookeeper : zookeeper-1:2181
- Utilizar el resto de configuraciones por defecto
Acceder al listado de clústeres
Seleccionar el clúster que hemos creado
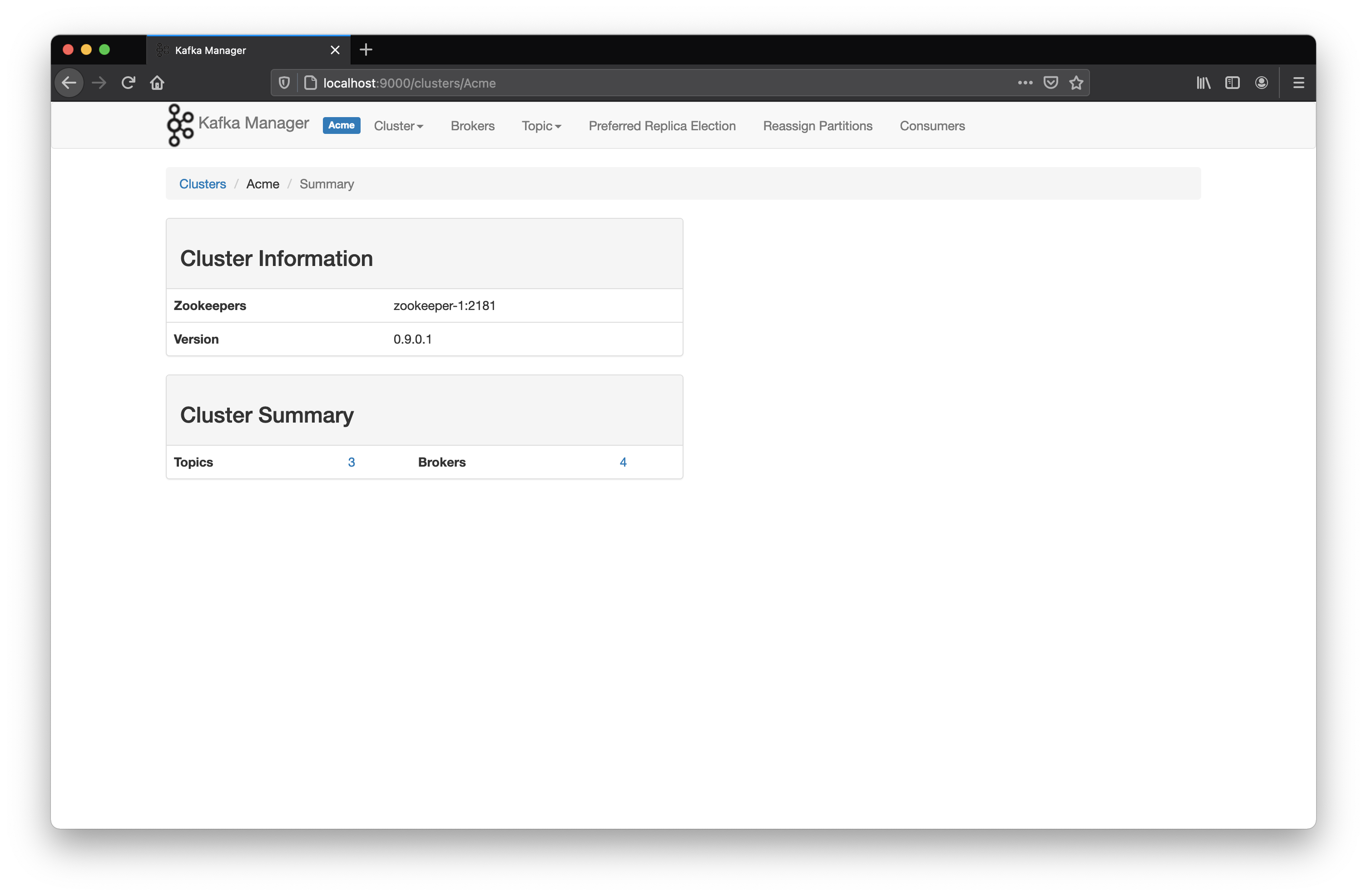
A partir de este punto ya podemos acceder a la funcionalidad proporcionada por la plataforma : gestión de nodos, topics, etc.
5. Conclusiones
Con lo que se ha enseñado en este artículo podremos además de solventar algunos de los problemas que se detallaban al inicio, realizar pruebas rápidas con diferentes escenarios y con diferentes configuraciones internas para que el desarrollo sea más efectivo y por lo tanto la infraestructura utilizada NO sea un problema. Mejoramos al no tener que dedicar a instalarlo una y otra vez, asegurando que funciona de inicio al pasar esos scripts de soporte y con la seguridad de que si rompemos algo, lo podremos volver a recrear hasta el punto antes en el que nos lo cargamos.
Seguro que te han entrado ganas de usar Apache Kafka así... :-)
Si te ha gustado, ¡síguenos en Twitter para estar al día de próximos posts!