
Acelerando los desarrollos con contenedores : Infraestructura de Base de Datos para Testing
Publicado por Víctor Madrid el
Arquitectura de SolucionesAceleradores de DesarrolloBBDDmysqlPostgresql
En este artículo se va a mostrar como poder disponer de unos contenedores de diferentes bases de datos de forma rápida para utilizarlos para testing generando entornos de datos locales, desarrollo, integración y/o QA (en función de dónde y la forma en que se aplique).

Casi siempre necesitamos utilizar una base de datos para poder probar nuestros desarrollos en alguno de los entornos y casi siempre aparecen las mismas preguntas :
- ¿Estoy utilizando la misma versión de la base de datos con la que trabajare posteriormente en el entorno productivo?
- ¿Puedo asegurar que mi driver de base de datos es 100% compatible?
- ¿Tengo el mismo esquema de base de datos (tablas, procedimientos , etc) con el que trabajare?
- ¿Mis cambios en base de datos funcionarán correctamente cuando los apliquen en producción?
- ¿Mi juego de datos utilizado tiene una mínima calidad para poder cubrir casi todas las casuísticas que necesito?
- ¿La base de datos que utilizo para pruebas es tocada por todo el mundo y el día que yo haga la demo faltará la factura "1003" que es con la que siempre trabajo?
- ¿Si utilizo un "CI/CD de verdad" mi entorno se genera y destruye en cada intento de release candidate (RC)?
- ....
Como podéis ver son preguntas muy típicas que seguro alguna vez os habréis hecho.
El objetivo de este artículo es poder dar alguna "ayuda" o pista al enseñar a utilizar contenedores con bases de datos precargadas inicialmente con la estructura + datos con la que se trabajará, donde romper algo no afecta a casi nadie y si algo se rompe se vuelve a empezar construyendo otro contenedor :-)
Además, NO sólo se puede utilizar en local sino que con un poco de maña, algo de conocimiento y un proveedor Cloud se pueden hacer cosas muy chulas como crear instancias a partir de un contenedor, así que mirar la cantidad de posibilidades que tenemos a la hora de montar entornos :-)
Este artículo está dividido en 4 partes:
- 1. Introducción
- 2. Stack Tecnológico
- 3. Ejemplos de Uso
- 4. Conclusiones
1. Introducción
En este apartado se tratarán los siguientes puntos:
- 1.1. Introducción al uso de contenedores como aceleradores del desarrollo
- 1.2. ¿Qué necesidades tenemos para tener una "Infraestructura de Base de Datos para Testing" con contenedores?
1.1. Introducción al uso de contenedores como aceleradores del desarrollo
Para centralizar esta información en un único punto y así poder facilitar su consulta se ha diseñado un artículo específico
1.2. ¿Qué necesidades tenemos para requerir una "Infraestructura de Base de Datos para Testing" con contenedores?
Los motivos principales que me llevaron a tratar de investigar en tener una infraestructura de Base de datos para Testing dentro de un contenedor fueron los siguientes :
- Disponer de una instalación inmutable
- Replicar la instalación del producto del cliente en local (versionado , entorno, etc.)
- Minimizar en un entorno previo los posibles cambios de configuración que pudiéramos requerir -> Perdiendo el miedo a los cambios (en mi caso la base de datos estaba en Azure y a todo el equipo le daba miedo tocarla...jeje)
- Asegurarse de que a todo el mundo le funcionaba de primeras la base de datos
- Poder probar los cambios en algo más real que una base de datos en memoria
- Facilitar un entorno de testing inicial de los desarrollos
- Posibilidad de definir otros entornos de testing de base de datos
- Evitar tener muchas instalaciones de BBDD en tu máquina
2. Stack Tecnológico
Este es el stack tecnológico elegido para implementar la funcionalidad "Intraestructura de Base de Datos para Testing":
- Java 8
- Docker - Tecnología de Contenedores/Containers
- Docker Hub - Repositorio de Docker Público donde se ubican las imágenes oficiales
- MySQL - Base de Datos relacional (Versión 5.7)
- PostgreSQL - Base de Datos relacional (Versión 11)
3. Ejemplos de Uso
Para enseñar a utilizarlo y así practicar se ha habilitado un repositorio. Este repositorio se reutilizará para otros artículos de la serie "Acelerando los desarrollos con contenedores".
La parte de que tiene que ver con este artículo se encuentra en los apartados:
IMPORTANTE: Cada uno tiene el detalle de su implementación y uso en su fichero README.
Según el enfoque que se quiera dar a los contenedores sería interesante activar los volúmenes :
- Volumen Activo / Descomentado: En cada arranque del contenedor se utiliza la información aquí almacenada por lo que se persistirán los cambios cada vez que se modifiquen. La primera vez que arranque se utilizarán los valores descritos a partir de aquí estos podrán ser modificados y persistidos con cada cambio
- Volumen Inactivo / Comentado: En cada arranque del contenedor se utilizará la configuración de datos, por lo tanto, no se persistirán los cambios entre arranques (ideal para probar una y otra vez)
3.1. Scripts de Soporte
En este caso no aplica.
3.2. Investigar lo que se usa
Cuando uno crea un contenedor basado en una imagen ya se han visto las consideraciones que se deben tener en cuenta para llegar a entender que es lo que hace.
Si tienes alguna duda vuelve a revisar el apartado "Soporte de Análisis de Contenedores" del artículo de introducción : Acelerando los desarrollos con contenedores: Introducción
Ejemplo de ejecución para mostrar la información del proceso ejecutado tras realizar un "up" del caso MySQL

Ejemplo de inspección sobre el contenedor creado para el caso MySQL
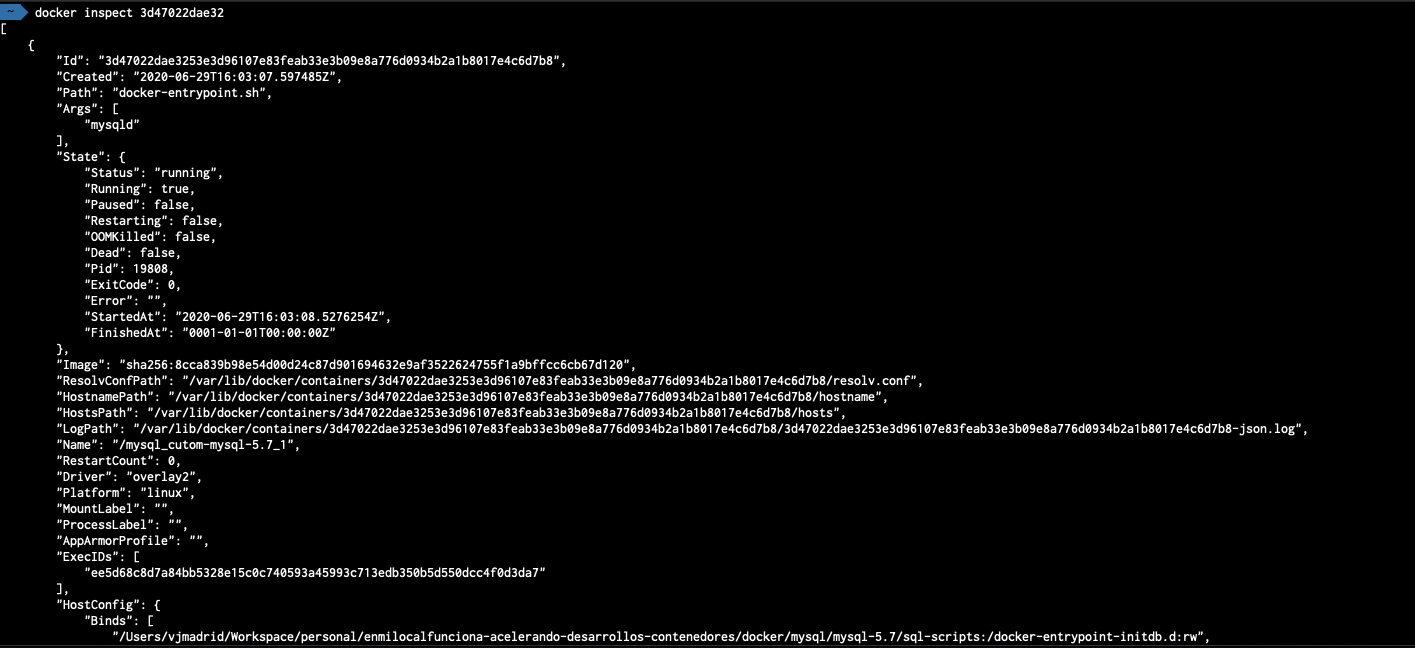
Ejemplo de investigación general dentro del contenedor del caso MySQL
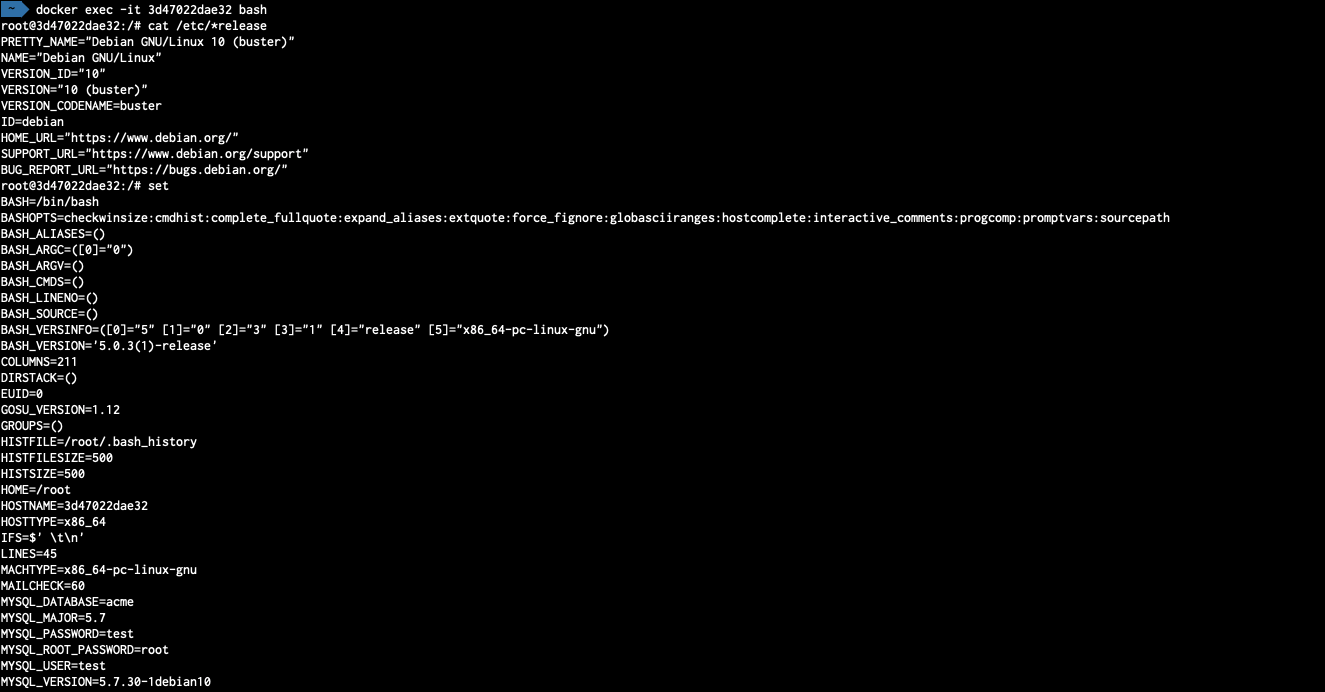
3.3. MySQL + Precarga de Datos
Este proyecto consta del siguiente elemento:
- Contenedor de MySQL
- Proporciona la instalación del producto en la versión establecida
- Establece una serie de variables de entorno que proporcionan diferentes aspectos de configuración
- Define una serie de volúmenes para determinar la persistencia de la configuración y de la precarga de datos (ya que obtiene el script de datos de forma local)
- La inyección del fichero SQL con estructura y datos se realiza desde el Dockerfile
- Establece el puerto de publicación (el usado por defecto)
Ejemplo de fichero "docker-compose.yaml"
# Use Case: Basic Installation
services:
# Project URL: https://github.com/mysql
# Docs URL: https://dev.mysql.com/doc/
custom-mysql-5.7:
build: ./mysql-5.7
container_name: custom-mysql-5.7
environment:
MYSQL_ROOT_PASSWORD: root
MYSQL_DATABASE: acme
MYSQL_USER: test
MYSQL_PASSWORD: test
volumes:
# *** MySQL configuration ***
- ./custom-mysql-5.7/config/my.cnf:/etc/mysql/conf.d/my.cnf
- ./mysql-5.7/sql-scripts:/docker-entrypoint-initdb.d
ports:
- 3306:3306
Para ejecutarlo ver el fichero README dentro del proyecto
Ejemplo de ejecución del contenedor : docker compose up --build
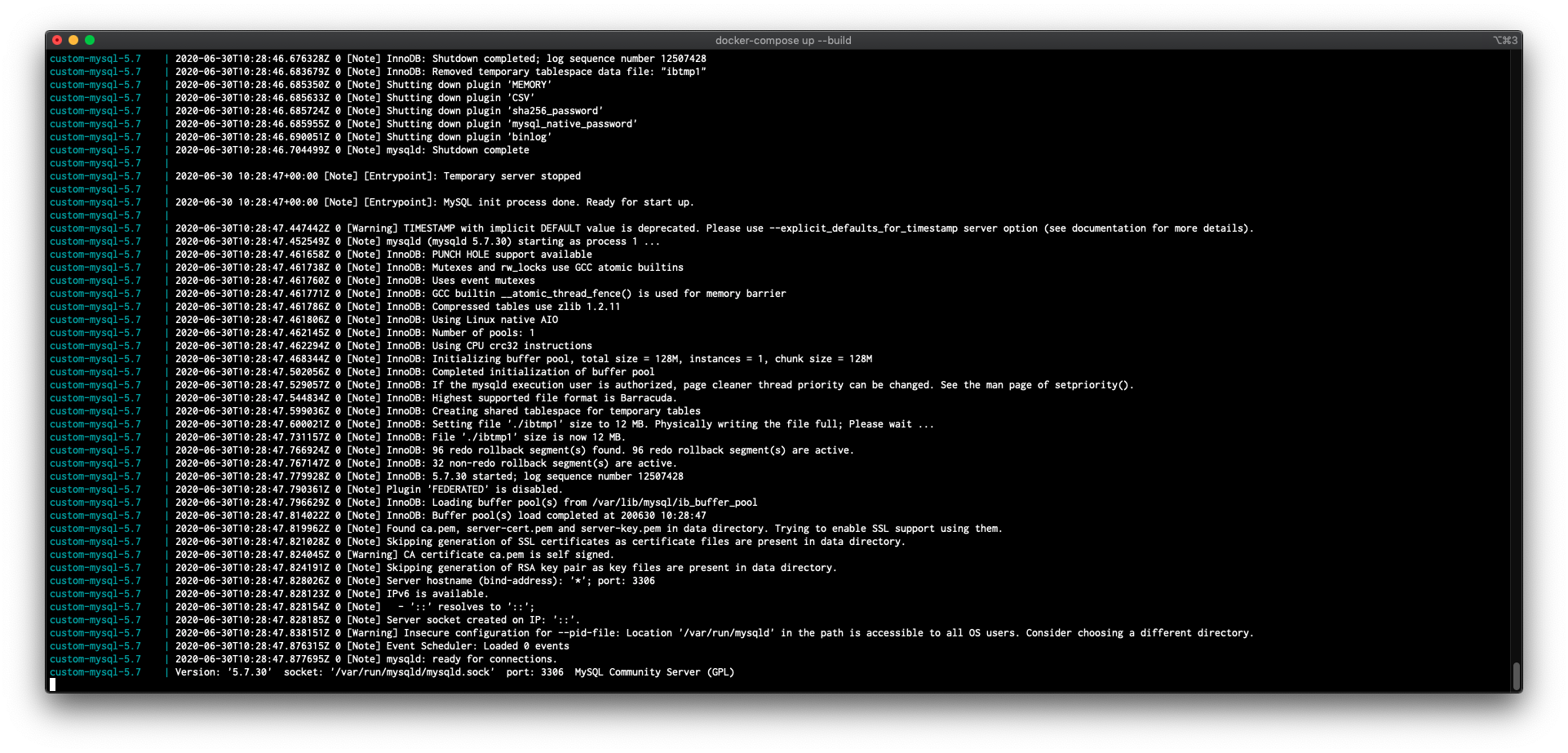
3.4. PostgreSQL + Precarga de Datos
Este proyecto consta del siguiente elemento:
- Contenedor de PostgreSQL
- Proporciona la instalación del producto en la versión establecida
- Establece una serie de variables de entorno que proporcionan diferentes aspectos de configuración
- La inyección del fichero SQL con estructura y datos se realiza desde el Dockerfile
- Establece el puerto de publicación (el usado por defecto)
La opción de volumen es opcional para gestionar su datos internos
Ejemplo de fichero "docker-compose.yaml"
# Use Case: Basic Installation
services:
# Project URL: https://github.com/postgres/postgres
# Docs URL: https://www.postgresql.org/docs/
custom-postgres-11:
build: ./postgres-11
container_name: custom-postgres-11
environment:
POSTGRES_USER: test
POSTGRES_PASSWORD: test
POSTGRES_DB: acme
#volumes:
# - ./custom-postgres-11/data/:/var/lib/postgresql/data/
ports:
- 5432:5432
Para ejecutarlo ver el fichero README dentro del proyecto
Ejemplo de ejecución del contenedor : docker compose up --build
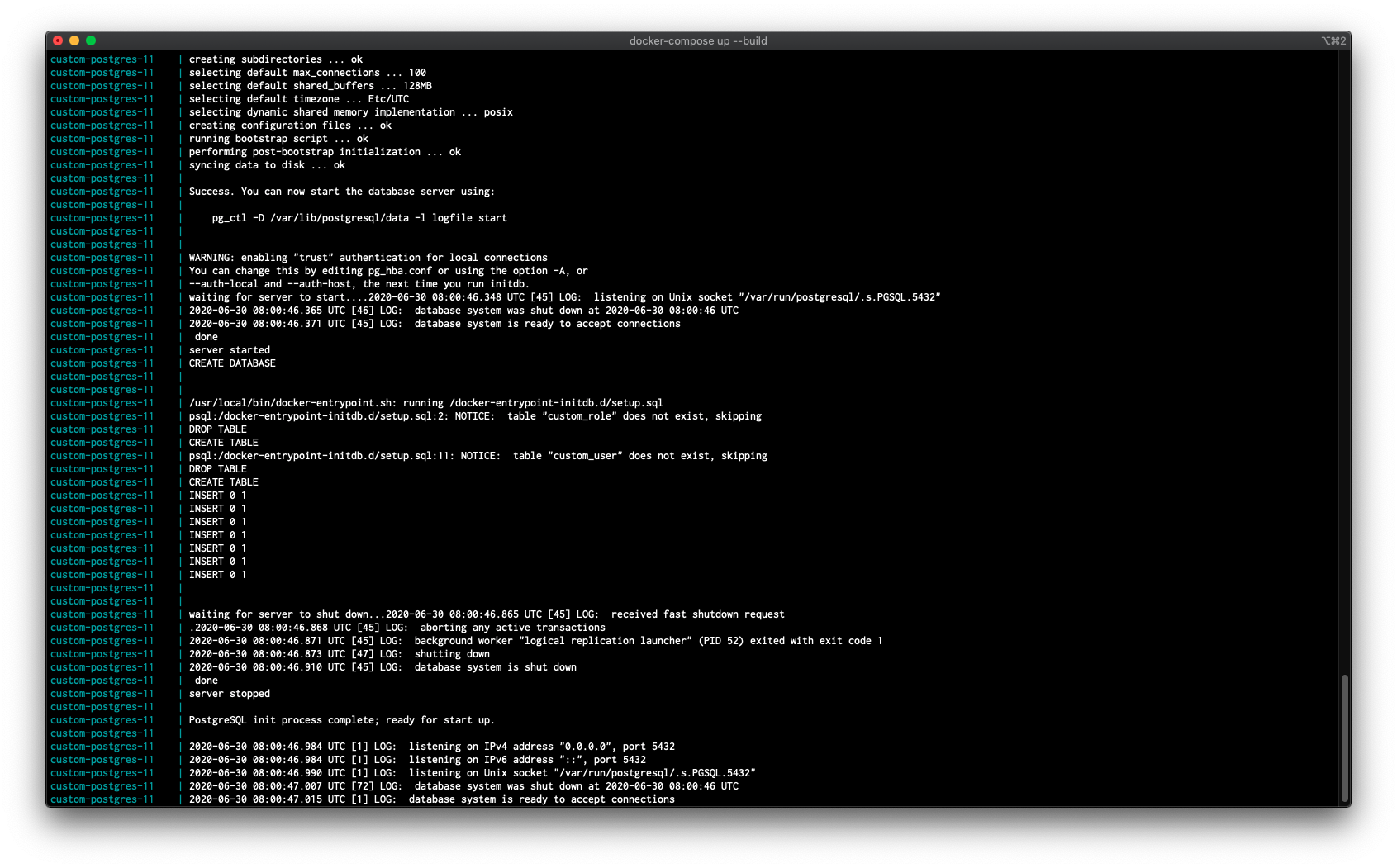
3.5. Verificar resultados
Tras la ejecución de lo anterior y si todo hay ido bien se arrancarán las bases de datos con los datos precargados.
Por lo tanto, se podrá acceder mediante el cliente por consola facilitado por la BBDD utilizada o bien mediante usando alguna herramienta de conexión a BBDD.
Ejemplo de pruebas de conexión y carga de datos de MySQL con Dbeaver:
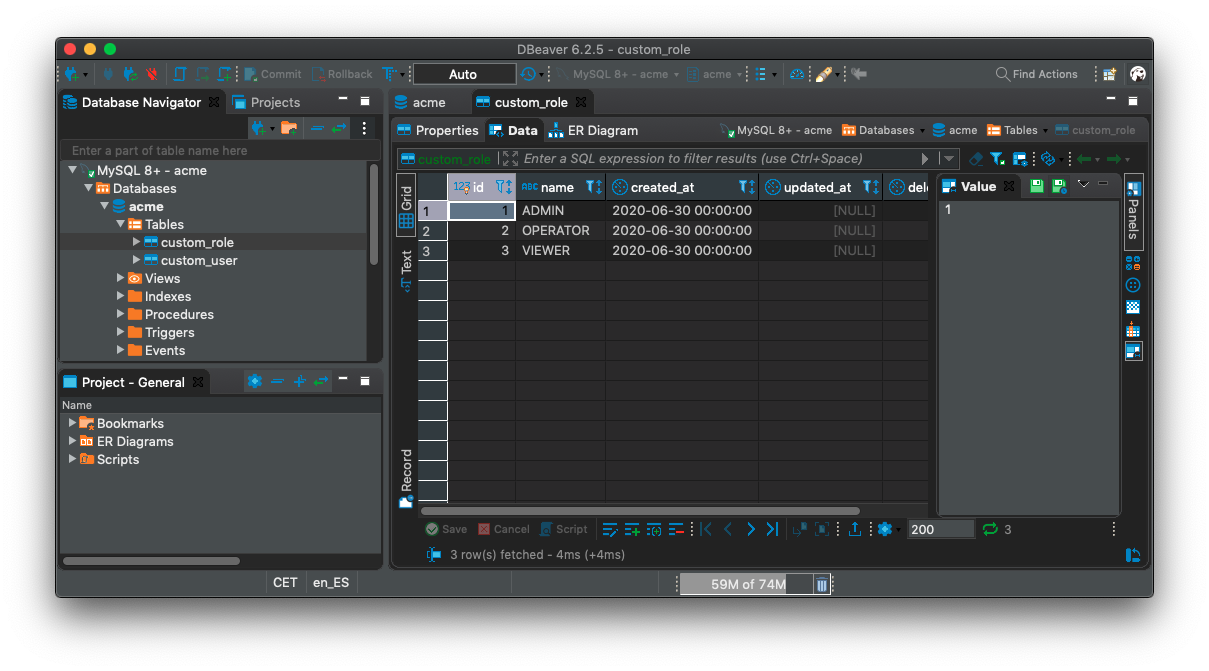
Ejemplo de pruebas de conexión y carga de datos de Postgres con Dbeaver:
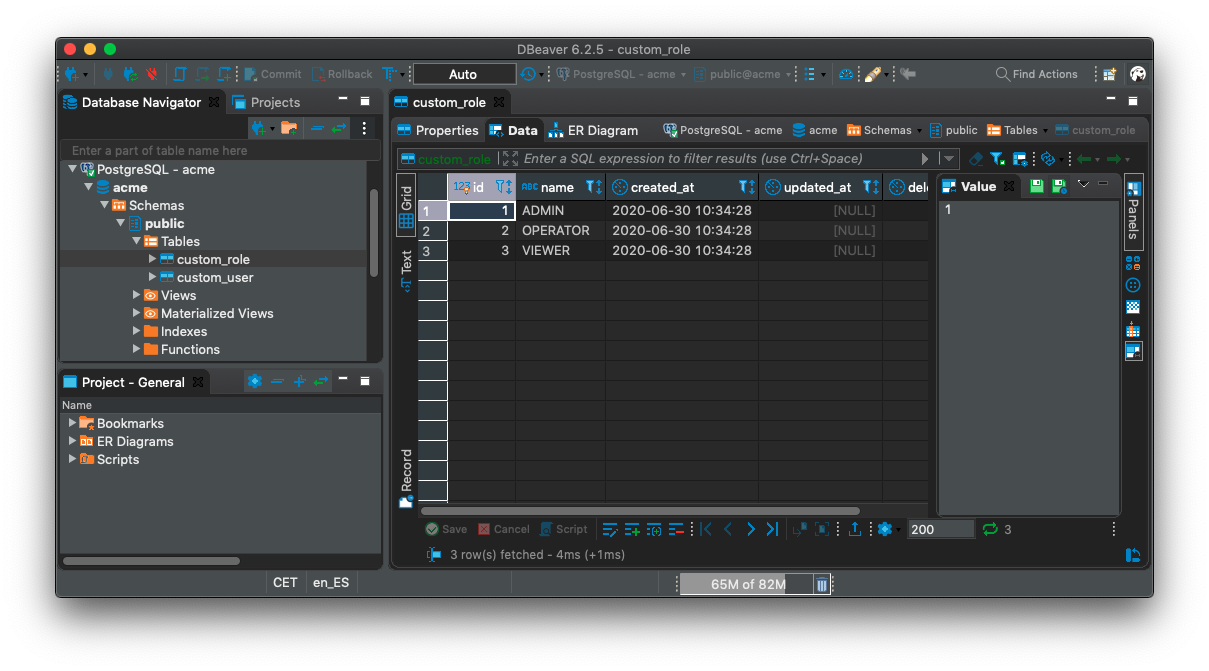
Si las conexiones se pueden establecer significa que podrán ser configurables sobre las aplicaciones :-)
4. Conclusiones
Pues con esto ya tenemos el objetivo del artículo cubierto, dispondremos de bases de datos con datos precargados dentro de un contenedor para que las usemos como queramos:
- Probar cambios de versión de BBDD
- Probar cambios sobre DML Y DDL -> y poder valorar si son viables los cambios
- Generar profiling de uso sobre las aplicaciones para que pueda existir su uso como entorno ,etc
- Posibilidad de montar entornos efímeros de forma rápida, estable y con juegos de datos acordes
- ...
Creo que este tipo de piezas son de las más utilizadas y sobre todo de las más agradecidas de tener.
Así que os animo a que empecéis a probar, seguro que encontráis otros usos :-)
Si te ha gustado, ¡síguenos en Twitter para estar al día de nuevas entregas!