
AWS Lambda: Primeros pasos serverless
Publicado por Juan José del Campo el
El objetivo de este post es presentar las arquitecturas Serverless, el servicio AWS Lambda como ejemplo de las mismas y un ejemplo desde cero, que nos facilite comenzar con estos interesantes conceptos.

Precondiciones:
Cuenta en Amazon AWS con permisos suficientes (creación de roles, acceso a las funciones lambdas y creación de buckets):
Configuración del entorno de desarrollo
Las pruebas se han realizado bajo S.O. Linux (Ubuntu 16.04), con Python ya preinstalado en su versión V2.7.12. Es condición que la versión de Python sea superior a V2.6.5, o en caso de Python3, sea superior a v3.3.
Instalación del entorno de desarrollo en local:
1. Instalación y configuración de aws-cli:
En primer lugar instalaremos el cliente de línea de comandos de AWS utilizando la herramienta "python-pip":
$sudo apt-get install python-pip
...
$ python --version
Python 2.7.12
$ pip --version
pip 8.1.2 from /home/...s (python 2.7)
...
...
$ sudo pip install awscli
...
$ aws --version
aws-cli/1.10.50 Python/2.7.12 Linux/4.4.0-31-generic botocore/1.4.40
Configuración del aws-cli: Las claves de acceso son las credenciales que podemos descargar desde nuestra cuenta de AWS. La región y el formato de salida son configurables. Usamos para el ejemplo la región de Irlanda (eu-west-1) y el formato JSON.
$ aws configure --profile atprofile
AWS Access Key ID [None]: ************
AWS Secret Access Key [None]: ************
Default region name [None]: eu-west-1
Default output format [None]: json
2. Instalación de Node.js y npm
Es importante tener en cuenta las versiones del Runtime de las funciones lambdas, ya que en caso de aplicaciones con árboles de dependencias complejos, puede existir riesgo de incompatibilidad.
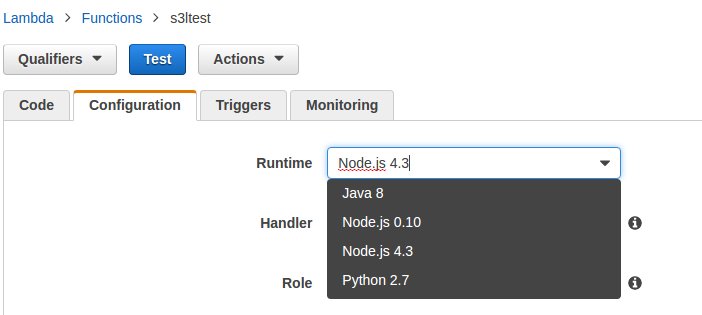
Para este ejemplo, dada la sencillez del mismo, no ha sido necesario y hemos empleado la última disponible. Sin embargo, para proyectos complejos, es un detalle a tener en cuenta:
$ curl -sL https://deb.nodesource.com/setup_6.x | sudo -E bash -
$ sudo apt-get install -y nodejs
$ node -v
v6.3.1
$ npm --version
3.10.3
3. Creación del proyecto "S3FileTransport"
El proyecto S3FileTransport va a contener el código de Node.js necesario para modificar y mover un fichero desde un bucket origen hasta otro destino. Se trata de un caso de uso aplicable, por ejemplo, a pipelines de ingestión y procesado de contenidos a través de ficheros.
Se trata de una sencilla función, en un único fichero: s3ltest.js:
// Declaración de dependencias
// Cada dependencia se añade a través del comando "npm install"
var async = require('async');
// La dependencia aws-sdk es una excepción
// No se carga, se delega en el runtime Node.js de AWS-lambda
var AWS = require('aws-sdk');
// Variable que referencia a S3
var s3 = new AWS.S3();
exports.handler = function(event, context, callback) {
// Mostramos por consola el evento
console.log('Received event:', JSON.stringify(event, null, 2));
// Obtenemos los nombres del bucket origen y del fichero
// Estas variables se obtienen en cada ejecución, lo cual no es siempre óptimo
var srcBucket = event.Records[0].s3.bucket.name;
var srcKey =
decodeURIComponent(event.Records[0].s3.object.key.replace(/\+/g, " "));
// Definimos el nombre del fichero y bucket destino
// Bucket destino: <nombre-bucket-origen> + "-dest"
// Fichero destino: "moved-" + <nombre-fichero-origen
var dstBucket = srcBucket + "-dest";
var dstKey = "moved-" + srcKey;
// Proceso
async.waterfall([
// Descarga el fichero de S3
function download(next) {
s3.getObject({
Bucket: srcBucket,
Key: srcKey
},
next);
},
// Transforma el nombre del fichero
// Copia el fichero en el bucket destino
function upload(response, next) {
s3.putObject({
Bucket: dstBucket,
Key: dstKey,
Body: response.Body,
ContentType:response.ContentType
},
next);
}
], function (err) {
if (err) {
console.error(
'Unable to upload to ' + dstBucket + '/' + dstKey +
' due to an error: ' + err
);
} else {
console.log(
'Successfully uploaded to ' + dstBucket + '/' + dstKey
);
}
callback(null, "message");
}
);
};
Para subir una función lambda hay primero que construir y empaquetar el proyecto. Creamos el directorio node_modules donde irán las dependencias instaladas y luego generamos un fichero zip con la estructura:
#Instalación de dependencias, en este caso sólo async
#La dependencia la provee el runtime de amazon
$npm install async
..
└── async@2.1.2
...
$zip -r s3ltest.zip *
4. Creación de la función lambda
La función se puede dar de alta desde la consola de administración de Amazon AWS, una vez se accede al servicio AWS Lambda.
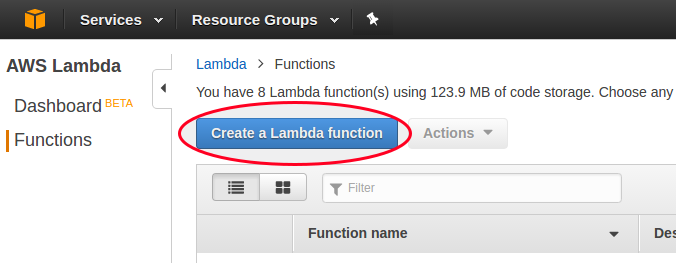
Para nuestra prueba usaremos sin embargo el aws-cli:
$aws lambda create-function \
--region eu-west-1 \
--function-name s3ltest \
--zip-file fileb:///<ruta-del-proyecto-empaquetado>/s3ltest.zip \
--role arn:aws:iam::1234567891234:role/nombre-del-rol \
--handler s3ltest.handler \
--runtime nodejs4.3 \
--profile atprofile \
--timeout 10 \
--memory-size 1024
{
"CodeSha256": "3ttFShUqSaLXXXXXXXXXXXXXnDJosq1TJMHKegD+k=",
"FunctionName": "s3ltest",
"CodeSize": 823040,
"MemorySize": 1024,
"FunctionArn": "arn:aws:lambda:eu-west-1:1234567899876:function:s3ltest",
"Version": "$LATEST",
"Role": "arn:aws:iam::1234567891234:role/nombre-del-rol",
"Timeout": 10,
"LastModified": "2016-10-19T09:45:42.983+0000",
"Handler": "s3ltest.handler",
"Runtime": "nodejs4.3",
"Description": ""
}
Es interesante destacar el parámetro --role, que define los permisos de acceso de nuestra aplicación. Necesitamos que tenga, al menos, permisos de ejecución de AWS-Lambdas (AWSLambdaBasicExecutionRole). En caso de necesitar más detalle: http://docs.aws.amazon.com/lambda/latest/dg/intro-permission-model.html
Una vez subida, la función aparecerá en la consola de administración de AWS. Podemos acceder a ella y editar el código dentro de la consola:
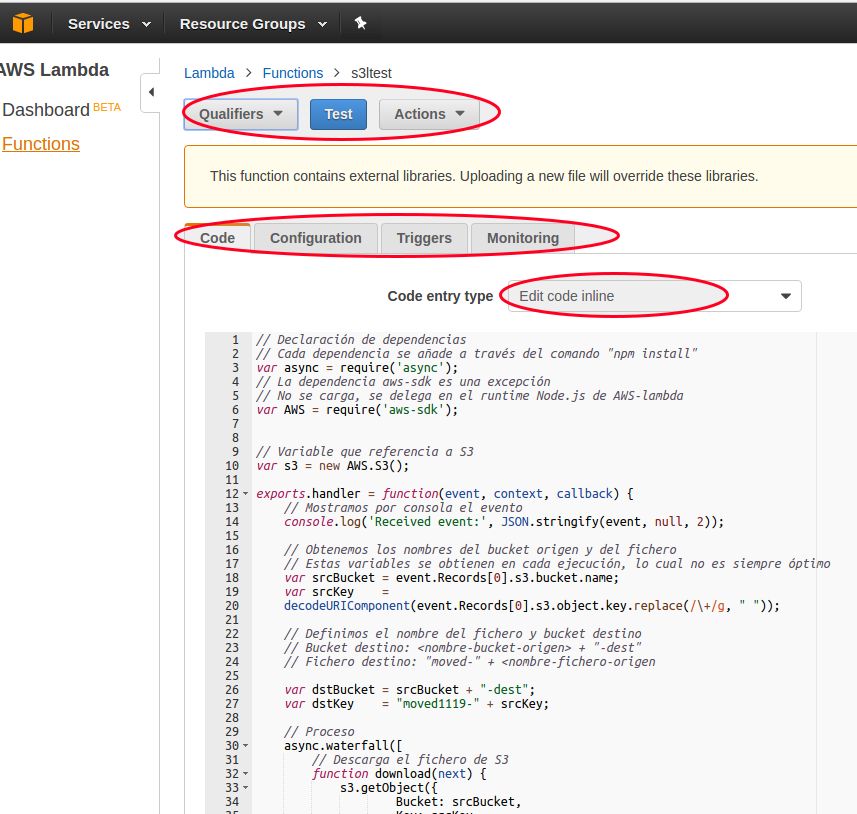
6. Creación de los buckets
Para que la función subida realice su tarea, queda configurar los buckets. En el caso de este ejemplo los hemos llamado ats-lambda-test y ats-lambda-test-dest:
Es importante que el usuario tenga permisos sobre el bucket:
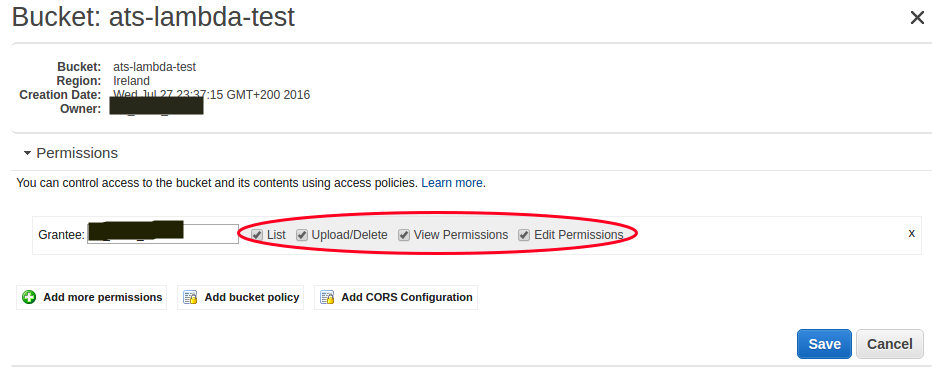
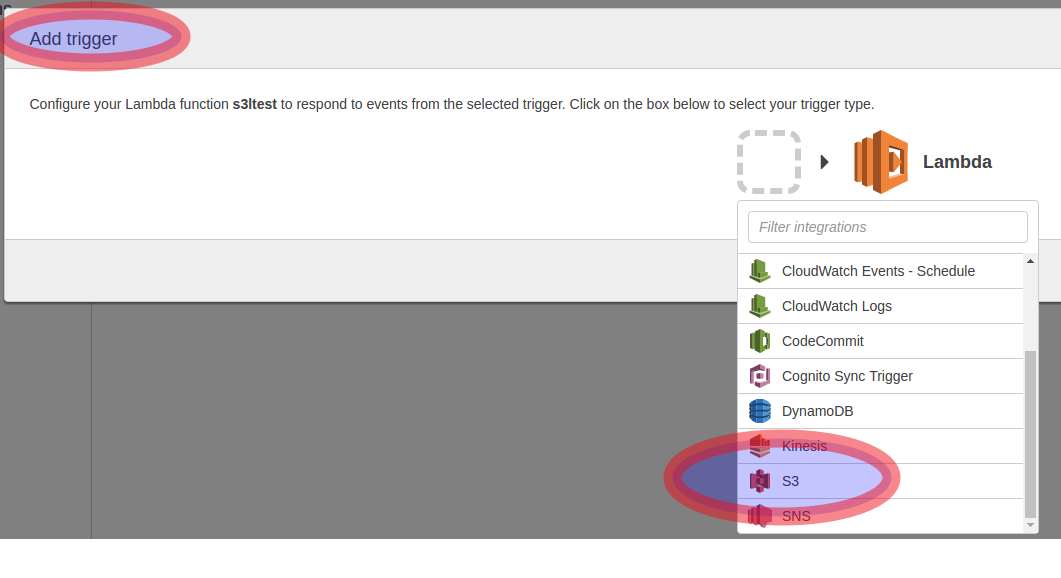
7. Creación del trigger
Volvemos a la administración de la función lambda en la consola y creamos el trigger que escuchará el evento de S3 (Creación de ficheros en el bucket):
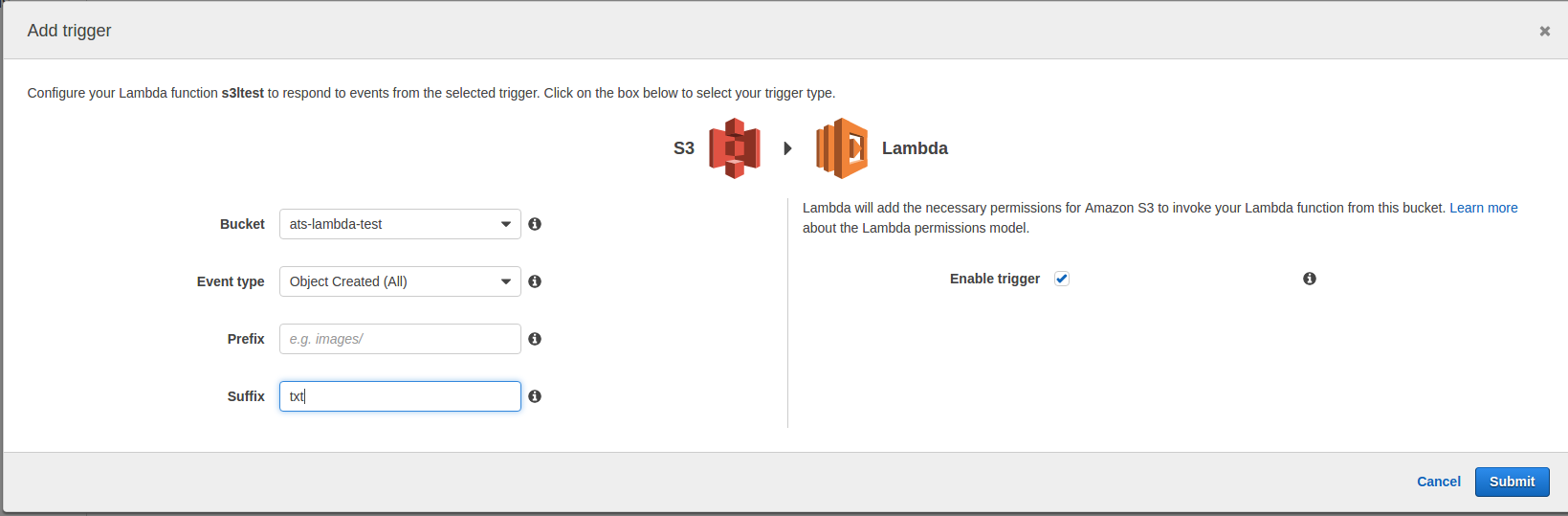
El trigger permite algunas opciones de filtrado:
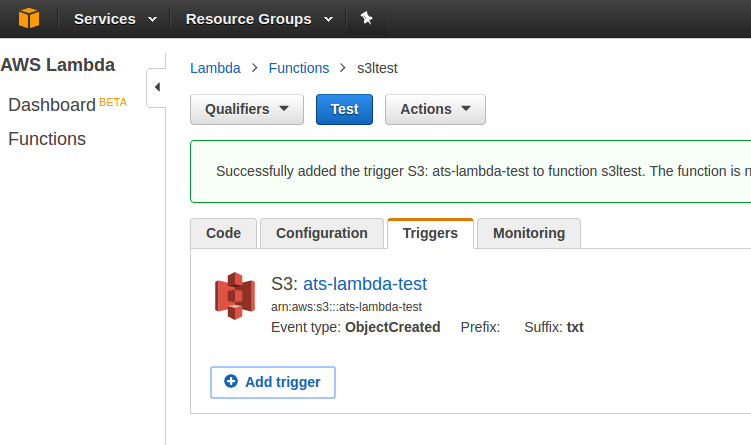
Una vez creado, se muestran los detalles del mismo:
8. ¡A jugar!
Finalmente, para completar la prueba, desde la pantalla del bucket origen lanzamos nuestra prumera prueba:
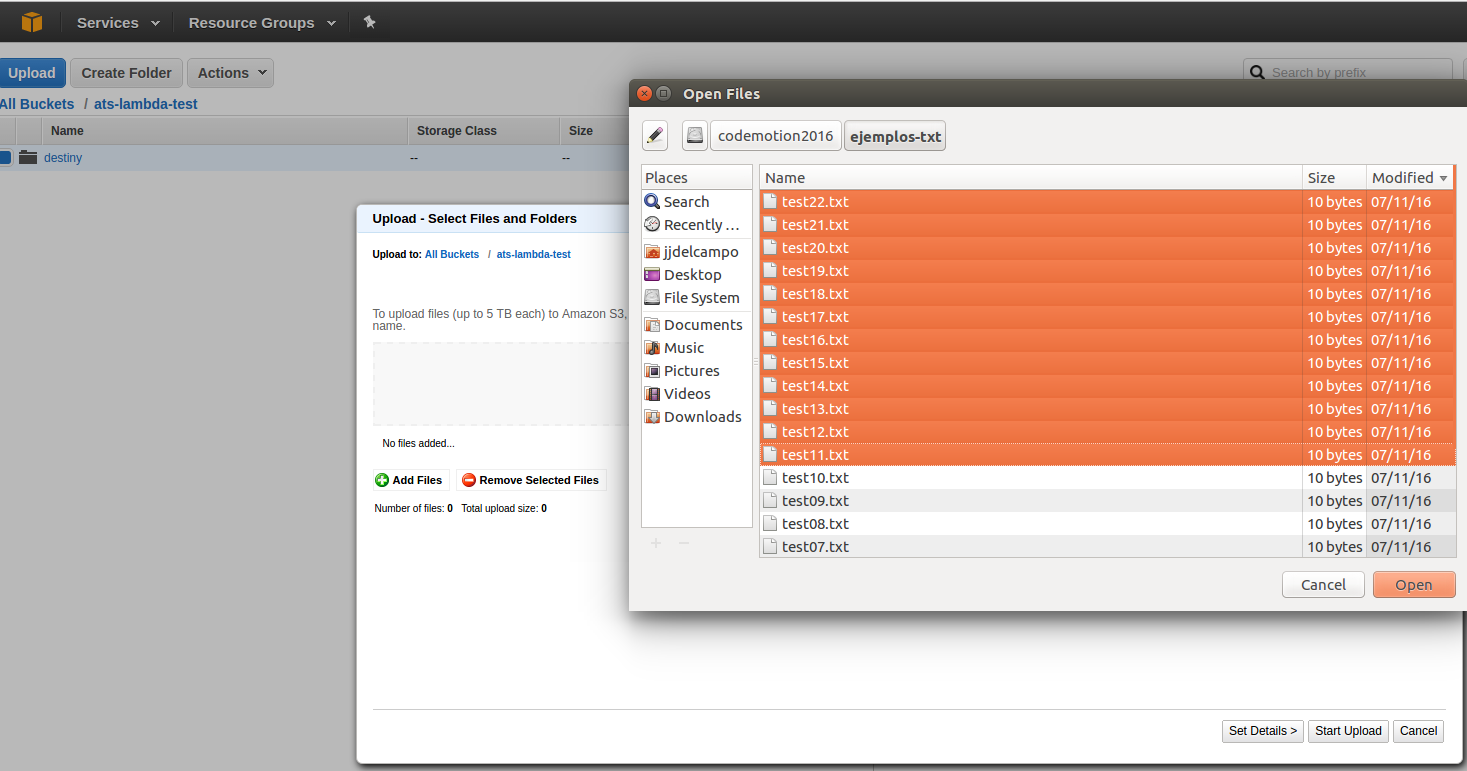
Comprobamos que aparecen, renombrados, en el bucket destino:
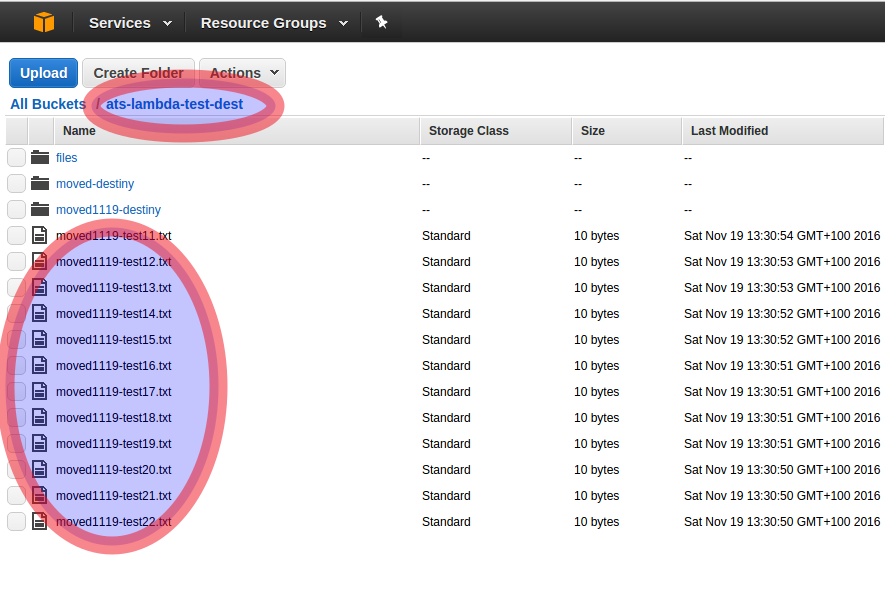
9. ¿Y ahora qué?
Una vez hemos hecho funcionar nuestra función merece la pena jugar con ella. Por ejemplo:
- Editar la función
- Probarla
- Versionarla
- Visalizar los logs
- Consultar o configurar alarmas
- Configurar parámetros de servicio
Y contarnos qué habéis encontrado, qué os gusta, o qué encontráis mejorable (que lo hay ;) )