
Azure Cognitive Search, el buscador indexado con inteligencia artificial
Publicado por Marco Russo el
Arquitectura de SolucionesCognitive ServicesCognitive SearchAzure
En los próximos dos artículos se detallará el servicio de buscador de Azure, que además de indexar los documentos, productos o servicios de cualquier aplicación web, aprovechando las funcionalidades de inteligencia artificial y semántica, lograremos mejorar los resultados de búsqueda y el ranking.

Pero, ¿Qué es Azure Cognitive Search?
Azure Cognitive Search, también conocido como Azure Search, es un servicio de búsqueda en la nube que proporciona además de la infraestructura, colección de API y funcionalidades, sirve para crear un buscador sobre contenido privado tanto para aplicaciones web, móviles y sitios web empresariales.
Al igual que otras bases de datos con motor de búsqueda, SolR y ElasticSearch sus directos competidores, el creado por Azure permite englobar todas las aplicaciones desarrolladas en Azure bajo el mismo techo, además incluyendo todas las funcionalidades de Azure Cognitive Services, las opciones de análisis de texto, semántica, OCR y el resto de las mejoras propias de la inteligencia artificial basada en textos, imágenes y vídeos.
La búsqueda es fundamental para cualquier aplicación que muestre contenido de texto a los usuarios, con escenarios comunes que incluyen la búsqueda de catálogos o documentos, la venta de productos online o la exploración de datos. El poder crear un servicio de búsqueda, se trabajará con las siguientes capacidades:
- un motor de búsqueda con almacenamiento de contenido propiedad del usuario en un índice de búsqueda
- indexación enriquecida, con análisis de texto y enriquecimiento de IA opcional para extracción y transformación de contenido avanzado
- capacidades de consulta, incluida la sintaxis simple, la sintaxis completa del motor Lucene
- integración de Azure en la capa de datos, la capa de aprendizaje automático y los servicios mencionados de Cognitive Services
Este diagrama es la representación a nivel general de como funciona el servicio de buscador de Azure:

¿Qué es un buscador de indexación y cómo funciona un motor de búsqueda?
Para entender un motor de búsqueda como funciona, el ejemplo más simple viene de un comportamiento habitual que realizamos a diario, las consultas realizadas en el buscador más famoso, Google. ¿Te has preguntado porque siempre "clava" con la respuesta el buscador Google y no otro? Bueno no siempre es cierto, todos los motores de búsqueda tienen en su interior un catálogo o varios según sea de texto, vídeo, imágenes y de otra fuente de dato, categorizados al igual que una biblioteca, tomamos ejemplo de la misma Wikipedia, donde por cada cierta temática, tiene indexados ciertos resultados provenientes de miles y miles de páginas web. Por lo que es exponencial el resultado, con millones y millones de datos recogidos y catalogados.
El funcionamiento es muy fácil de entender, y lo resumiré en los siguientes pasos basándome en un blog de recetas de cocina. Suponiendo que a diario publico post de recetas nacionales e internacionales, por lo que tengo que estructurar mi web en categorías, o hasta incluyendo etiquetas, para su fácil compresión de la temática. Cuando un usuario está buscando en mi blog la receta para realizar una buena pizza napolitana, utilizará el buscador interno o bien por categoría platos italianos, o bien por etiquetas, ejemplo, pizza. Hasta aquí muy sencillo.
Qué ocurre a partir del momento que busca internamente del sitio web? Y cómo se indexan los elementos en Google o en el resto de los motores de búsqueda cómo Bing / Yahoo y el resto?
- Un rastreador pasará cada día en los cientos de páginas web para buscar nuevos contenidos de la temática "comida italiana", y categorizando más hacía un apartado muy específico "pizza".
- Diferenciará entre contenido tipo texto, imágenes, vídeos, etc. para añadirlo a su propio catálogo.
- Le asignará una puntuación, llamada "puntuación del ranking", que basada en un algoritmo que mide la correlación del término con el contenido, tendríamos un valor cercano al cero cuando no tiene relación alguna con el tema, y cercano al 1 cuando esta tenga una relación muy estricta al tema.
- Entre los miles de contenidos se asignará una otra puntuación, pero esto ya estará basado en las características de la optimización del buscador, lo que conocemos como SEO (Search Engine Optimization), donde un contenido, por lo que un enlace del elemento, a través de unos factores, más o menos alrededor de 150/200, tendrá una prevalencia respecto a otros resultados, para situarse en las paginaciones del motor de búsqueda. Aquí donde hay diferencias entre la primera página de un buscador versus otra página, ejemplo resultado 40 o 100.
- Mejora continua a través técnicas de difusión del contenido y viralizarlo.
Aunque esta última técnica, abordaría otro factor de popularidad del contenido, no tiene una correlación directa con el buscador, por el simple hecho que podrás difundir un contenido y no tiene nada que ver con un topic que ya está indexado por lo que carece de esta posibilidad de rankear el resultado nuevamente excepto por el conjunto de otros factores, que sí indirectamente afectarán al resultado de aparición en su buscador sea de Google y co.
Por indexación hay que entender el concepto de las métricas de distancias y similitudes que vienen de la estadística y que miden la semejanza entre dos objetos. Entre ellas tenemos diferentes, y especial manera para la búsqueda de información, se utiliza la similitud coseno para puntuar la semejanza de documentos en un espacio vectorial. Hablaré de este concepto con la creación de un recomendador en Python al estilo Spotify más adelante.
Finalmente, el documento una vez catalogado, está listo para ser rastreado por los buscadores, y nosotros podemos enriquecerlo con más elementos para destacar el mismo, ejemplo incluir metadatos; fomentar los comentarios y la interacción con los usuarios; aumentar el engagement y tiempo de visitas; darle la posibilidad de recomendar otros contenidos similares; etc..
¿Cuáles son las funcionalides de Cognitive Search ?
Una vez llegados a entender bien cómo funciona un buscador, mostraremos las funcionalidades de Cognitive Search para indexar nuestros documentos y productos explicando así los pasos necesarios para poder aprovechar al máximo esta tecnología.
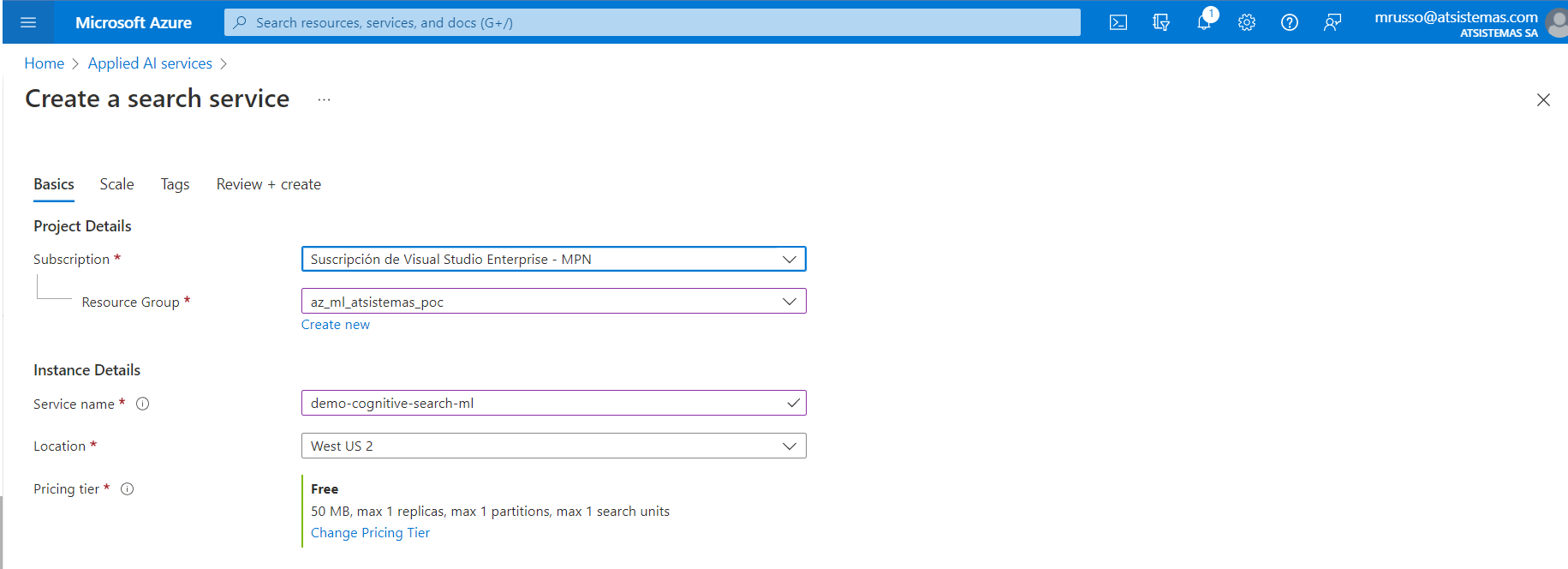
El primer paso a realizar es dar de alta al servicio escogiendo entre los diferentes planes, tal como explicados en la página web oficial. Al activar el servicio en el grupo de recursos que deseamos, este no tiene coste, así como el resto de entornos de los trabajos del resto de servicios de Azure. Pero sí es recomendable para un simple piloto ver la capacidad de cada "tier".

Si probamos el FREE tier, tiene solamente un máximo de 50MB de almacenamiento, respecto a 2GB del Basic. Respecto a los índices, es decir los catálogos a construir, por el momento con 1 es suficiente, teniendo en cuenta que la cuenta FREE el máximo son 3 y el Basic son 15. Para el resto de las opciones, límites, estarían detallados aquí: https://azure.microsoft.com/en-us/pricing/details/search/
El propio servicio de Cognitive Search tiene estos tres conceptos que es muy útil detallar:
- Data Source, la fuente de datos donde están almacenados los documentos, productos, etc. y donde indicaremos como punto de partida.
- Indexer, el rastreador y el corazón del motor de búsqueda, donde a través de unas configuraciones, aplicaremos los activadores, el mapeado sobre los datos, crear la caché así indicarle otras funcionalidades del rastreo.
- Index, el catálogo a crear según unas configuraciones de cómo tiene que ser el dato, su transformación a otro tipo, activar unos filtros etc.
Aquí una captura de la creación del servicio:
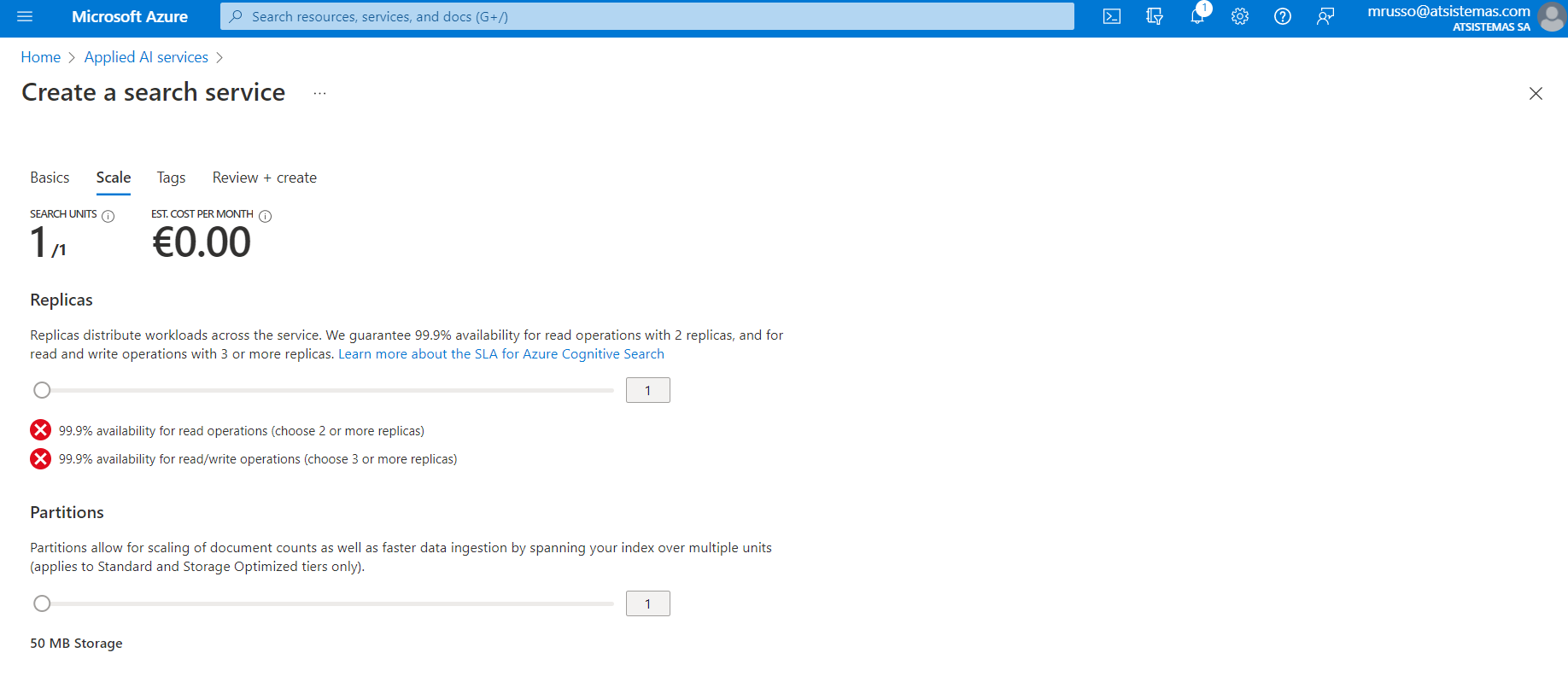
Muy interesante también el apartado de escalabilidad, y entender el concepto de particiones, puesto que generará unas cuantas dudas respecto a cómo se aplicará esta a los documentos indexados. Quizás sería útil profundizar con la lectura de este apartado:
Una vez activado el servicio, nos centraremos en estos 3 apartados para la creación del primer catálogo:
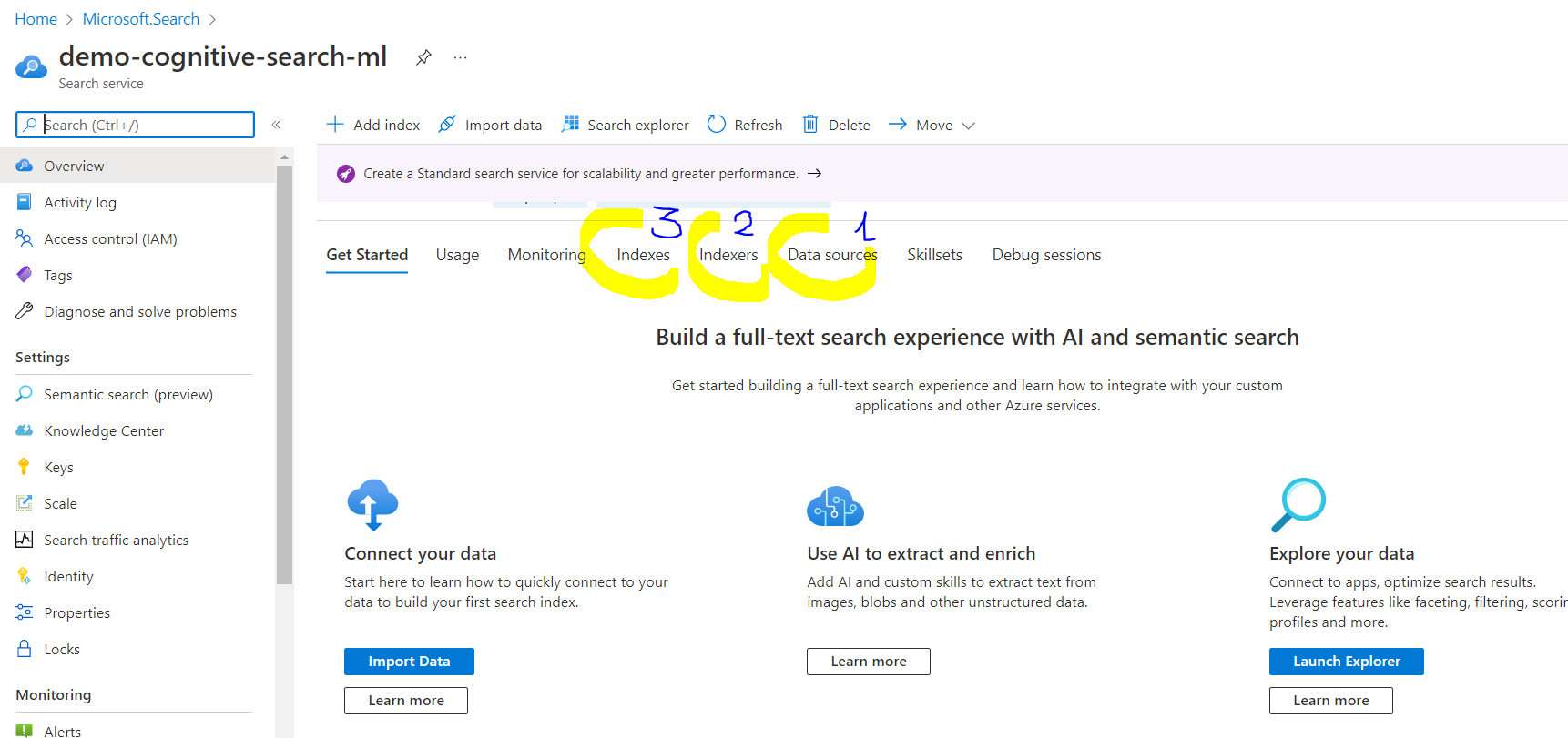
Data Source
Respecto a la fuente de datos, actualmente está limitado solo y exclusivamente a almacén de datos de Azure, por lo que en caso de tener on-premises u otro cloud, sería by-pasar la información en Azure (ejemplo en Data Factory o Synapse para realizar una ETL). Por lo que actualmente contamos con los siguientes:
- contenedor Blob storage
- Data Lake storage
- SQL Database
- Table storage
- Cosmos DB
Se configuran las definiciones, y listo.
Indexer
Una vez creado la fuente de datos, nos sugiere el sistema de seguir con la creación del indexer (indexador o rastreador) y su índice. Este paso es preferible realizarlo de una toma, puesto que crear el índice fuera de este, resulta algo complejo bajo mi punto de vista y no tiene en cuenta los factores del indexer, punto de mejora a futuro.
El indexer ha de crearse indicando el nombre, la fuente de datos hacía donde recoger los datos, cada cuanto actualizar el catálogo, y unas funcionalidades extra. Prestad atención siempre a los límites que incluye el tier seleccionado a principio, puesto que podrá afectar la creación del catálogo. Aquí el enlace de lo que concierne el indexer: https://docs.microsoft.com/en-us/azure/search/search-limits-quotas-capacity#indexer-limits
Index
Para el índice son necesarios unos pasos previos para configurar el tipo de campo a incluir, si este tendrá que ser rastreado, filtrado, analizado, así como incluido en su buscador. Además, podemos incluir el auto-suggester, gracias al motor Lucene que este incluye, e idioma, así permitiendo incluir la semántica al propio buscador.
Demo con Cognitive Search
Realizaremos ahora una pequeña demostración de las funcionalidades creando el catálogo de Airbnb y obteniendo el resultado en una web-app. También es posible recoger unas informaciones y enviarla a una herramienta de visualización, ejemplo Power BI, así valorar otros aspectos.
Para ello, nos iremos a Import Data y utilizaremos la muestra de datos a elegir entre SQL Database o Cosmos DB, en este caso rental-houses:
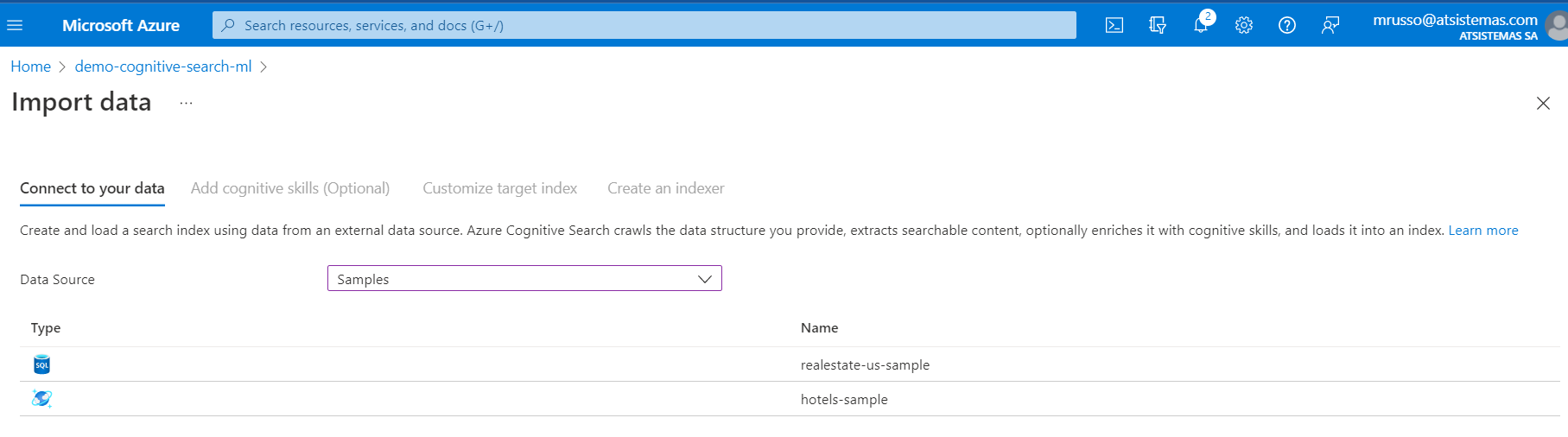
El siguiente paso, de forma opcional, es incluir unos de los skillset, opciones muy útiles de inteligencia artificial que hablaremos en el post sucesivo, para mejorar la experiencia de usuario y la performance del propio buscador.
En el apartado del índice, personalizaríamos los campos descritos en la sección Index, y siendo una demostración, dejaremos las opciones por defecto:
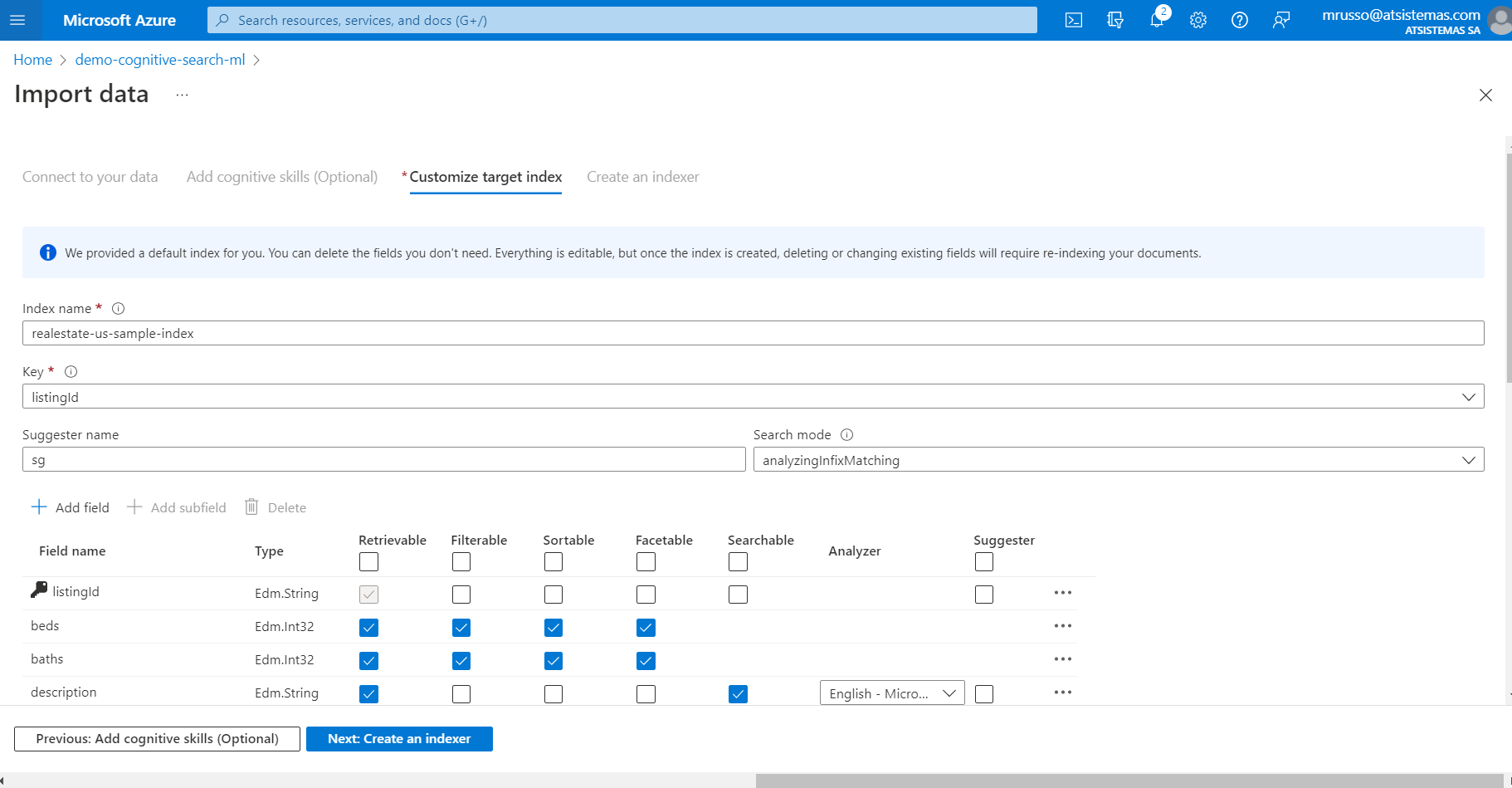
Finalmente creamos el índice y esperamos que todos los documentos hayan sido indexados, y observar el resultado.
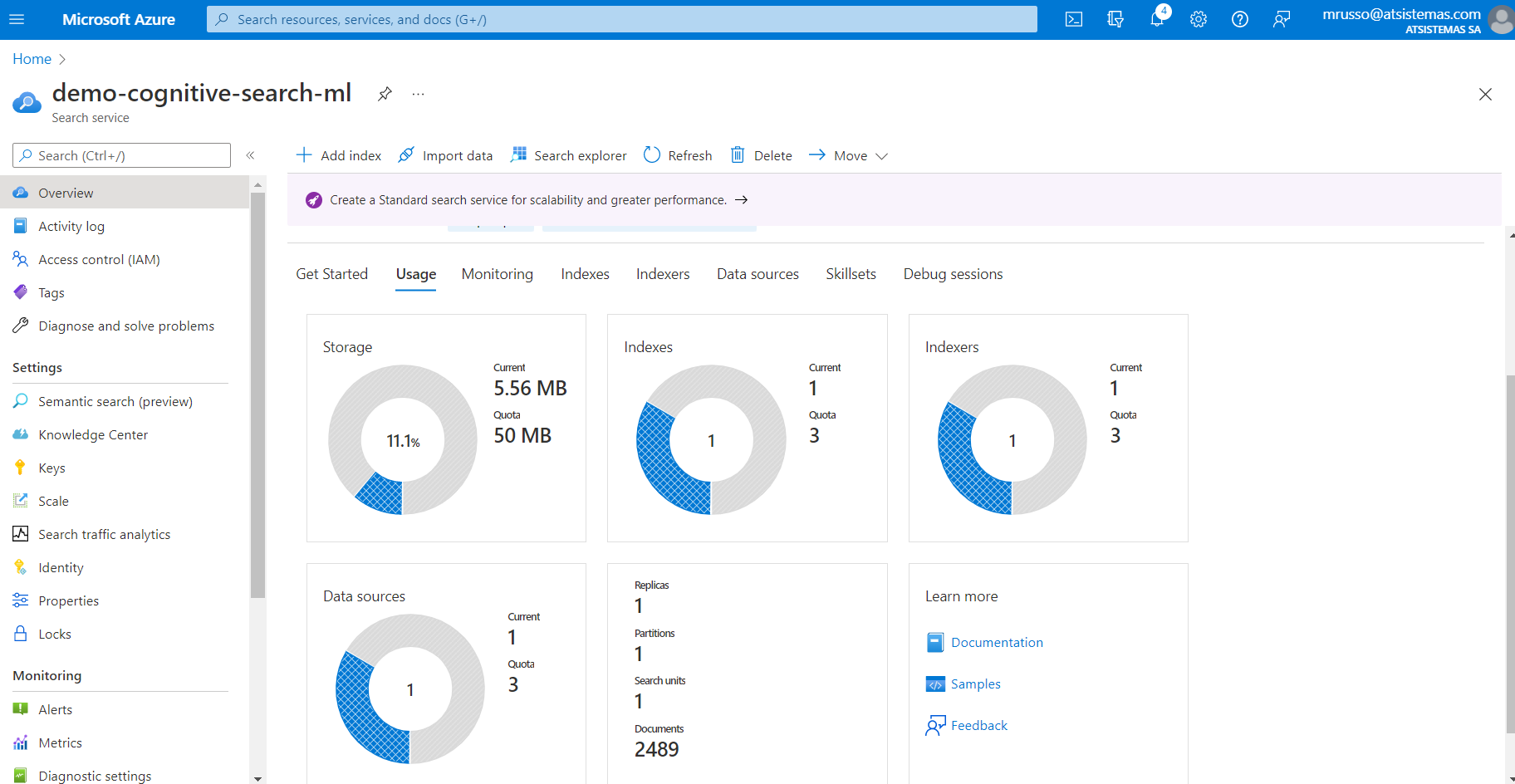
En la pestaña Usage podemos observar los datos ingestados y el índice creado, así como el resto de estadísticas de uso de esta herramienta:
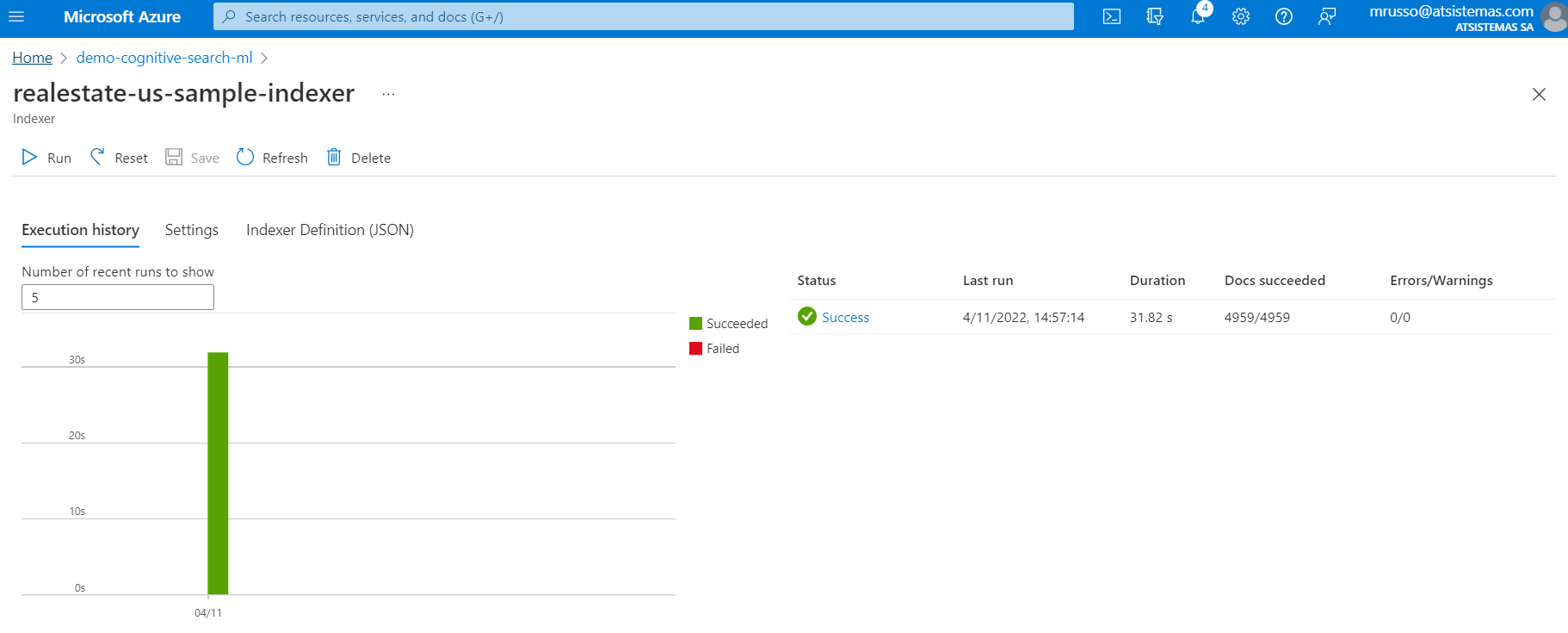
En la pestaña Indexer, siempre y cuando no hayamos creado un activador cada n tiempo de reset / ejecución , podemos observar cuántos datos se han catalogados, así los eventuales errores:
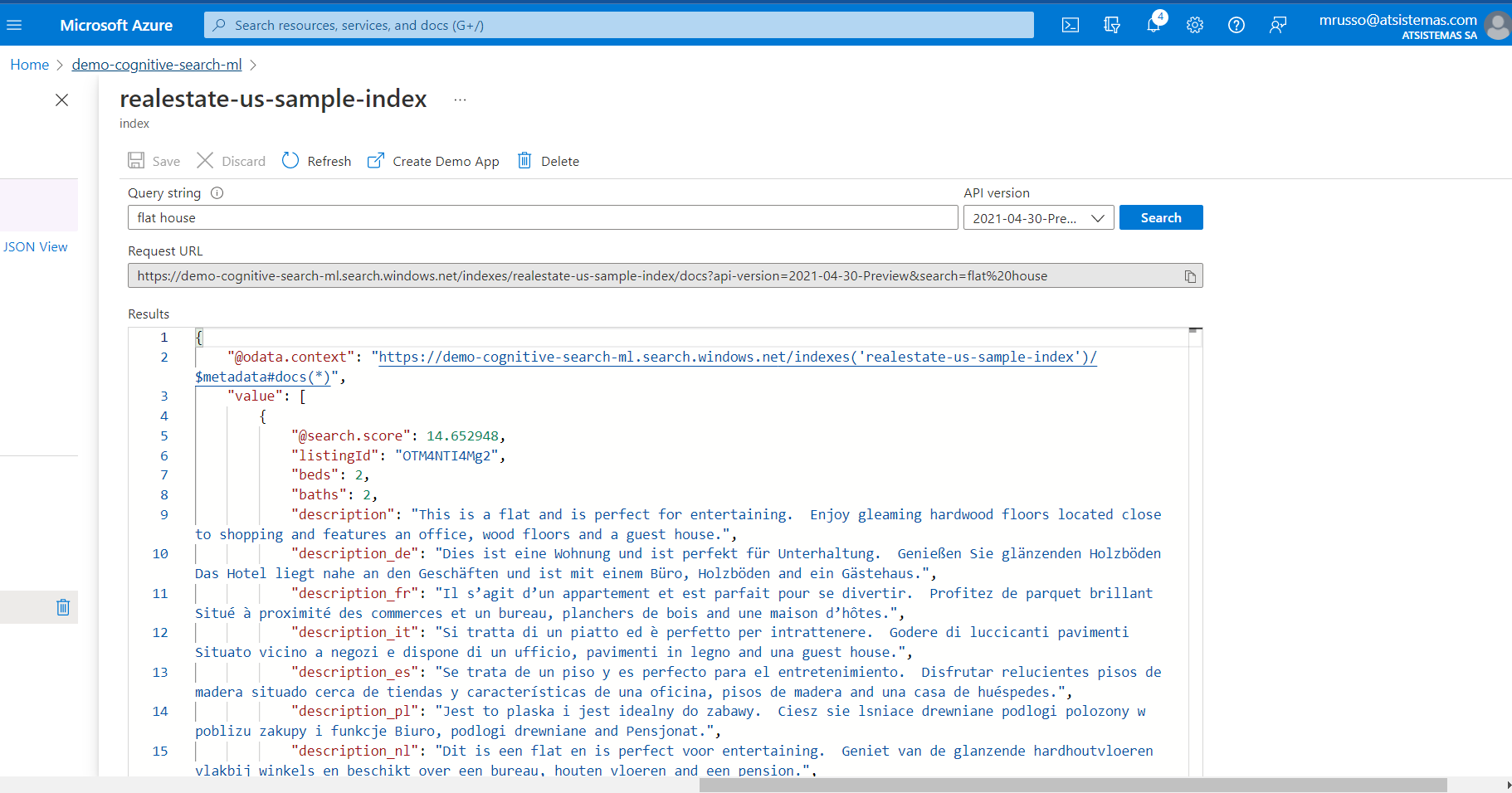
Finalmente simularemos bien con la propia API de Cognitive Search, bien vía interfaz cómo también Postman, esta última requiere la primary key que obtendríamos desde la interfaz del servicio, obtendríamos los resultados del buscador:
La última parte de esta demo es crear una demo app, habilitando el control de acceso CORS y tendríamos el resultado final, un fichero en formato html con los resultados indexados:
El primer punto que observamos son las auto-sugerencias del buscador:
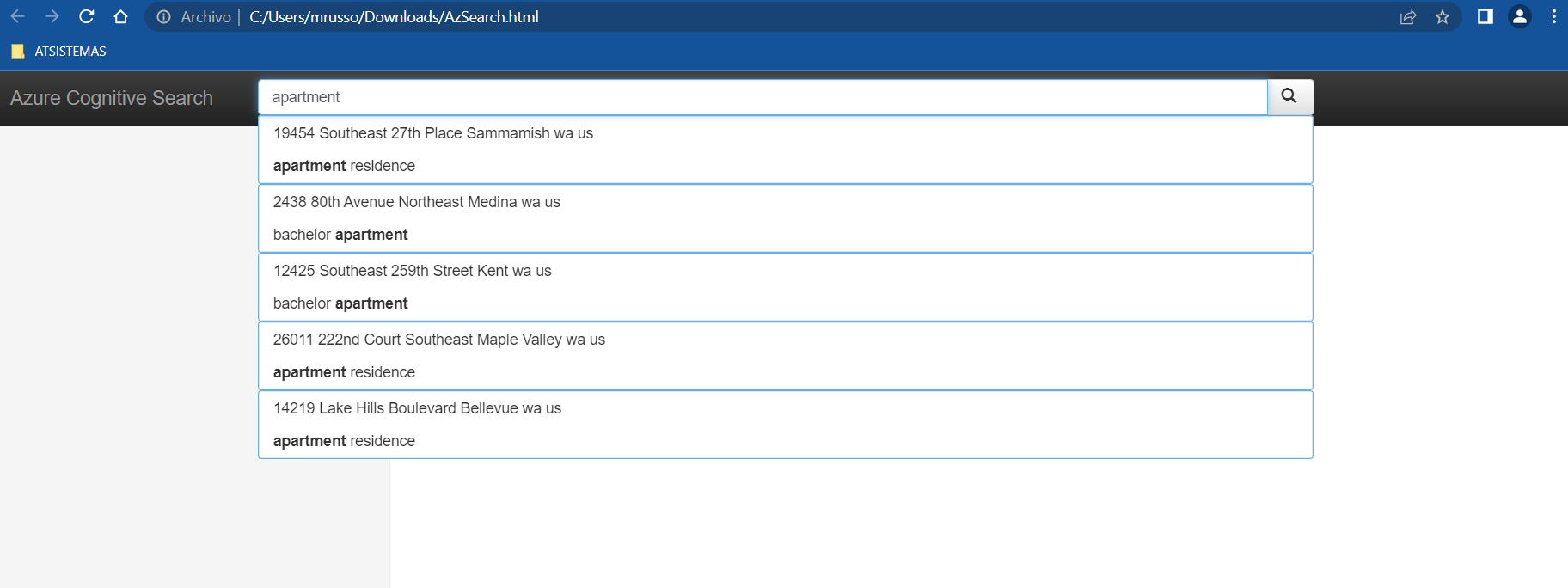
y finalmente los resultados últimos con los filtros aplicados según la búsqueda realizada:
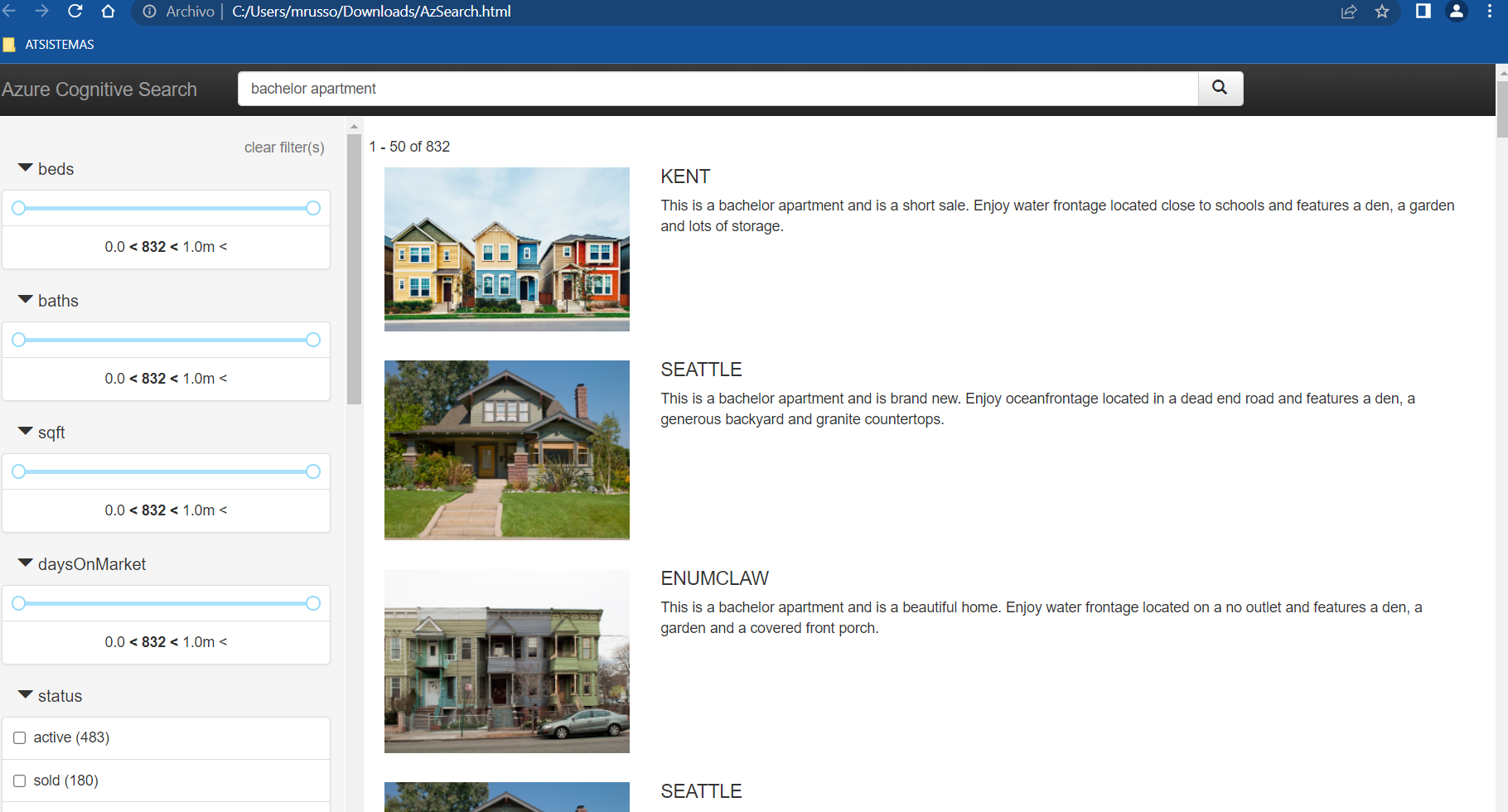
¿Y dónde se encuentra nuestra puntuación de ranking?
Realizando los mismos pasos en la solicitud de la API, observaremos los resultados ordenados de forma descendiente según ranking, en este caso por el término "bachelor apartment":
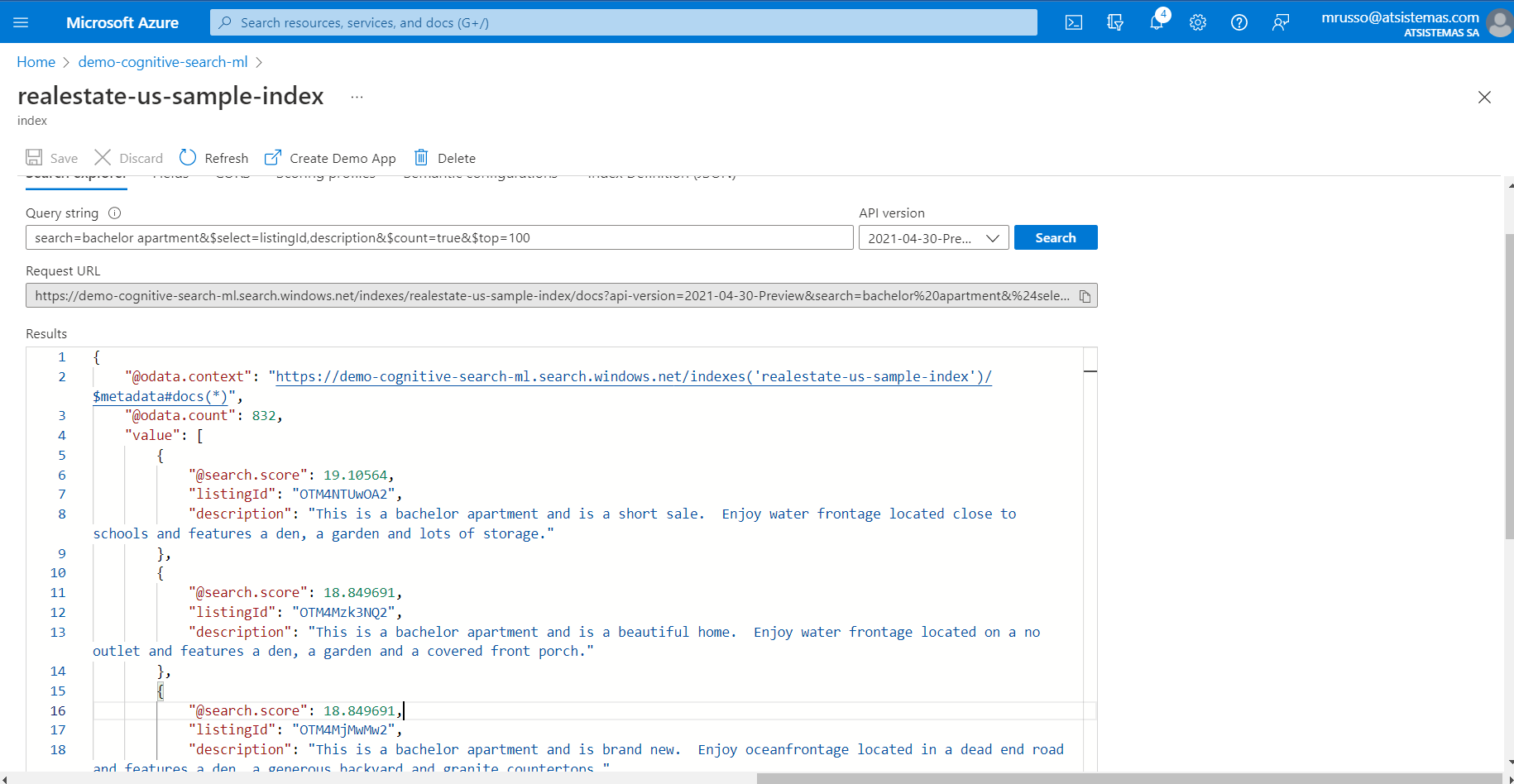
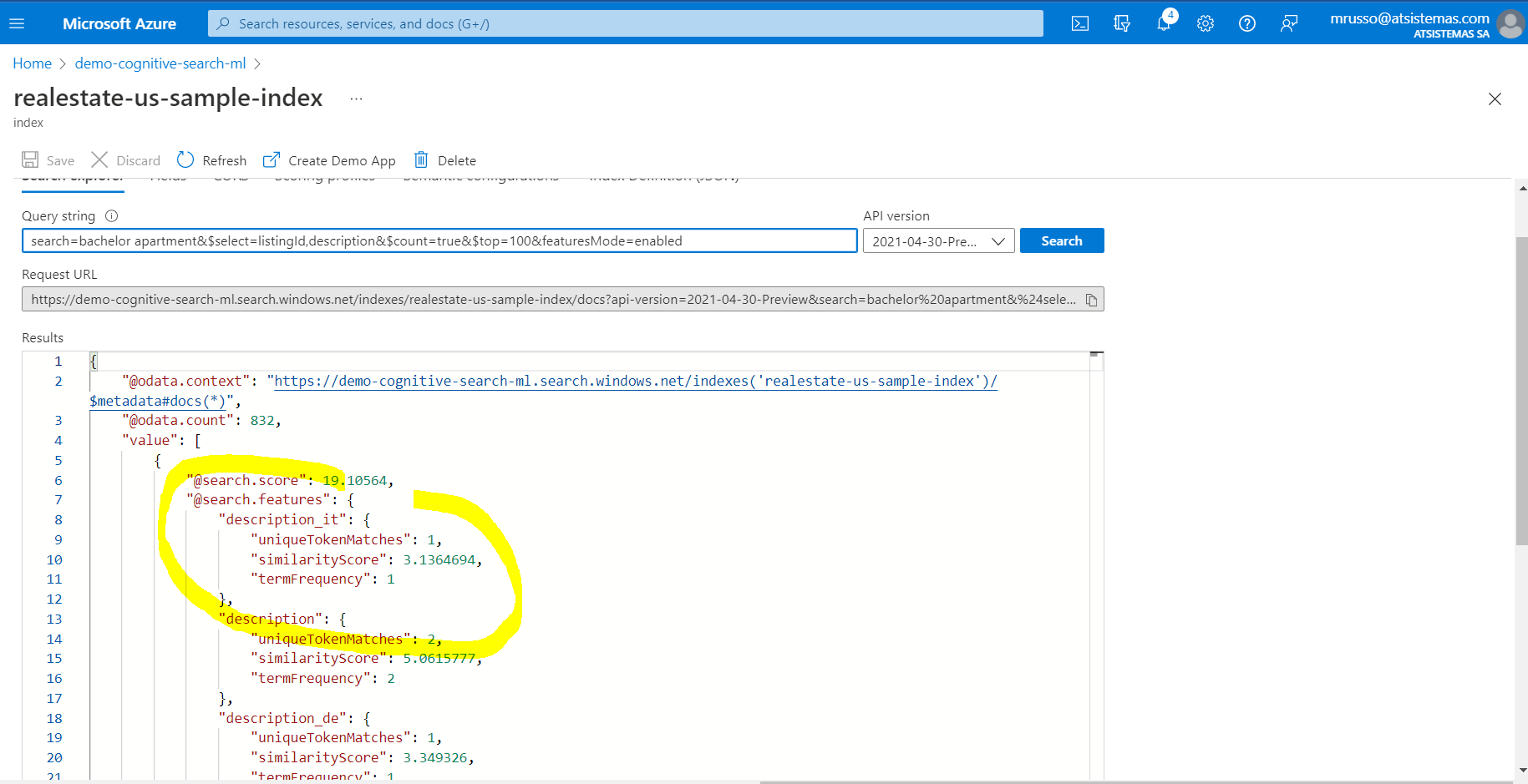
Esta puntuación, search_score, será la puntuación calculada que mejoraremos en la próxima entrega a través de un modelo de machine learning y que mejoraría el actual método calculado a través del BM25 y Cosine Similarity scoring. Ambos son utilizados por Microsoft para calcular la distancia entre las palabras importantes de estos textos y que sirva para crear el ranking, el parámetro y valor featuresMode=enabled nos indicarán estas métricas:
Conclusiones
Con este post hemos visto una visión general de la herramienta para crear un buscador muy sólido y válido para cualquier uso en nuestras aplicaciones web, por su simplicidad de utilizo y muy rápido de configurar e implementar.
¿Qué te ha aparecido este servicio? Comenta aquí si te ha gustado y si quieres conocer más sobre este servicio. Nos vemos en la próxima entrega de mejora de performance del buscador Cognitive Search de Microsoft Azure.