
Elevando la Precisión de Sistemas Multi-Agente
Publicado por Omar N. Muñoz Mejía el
RAG como Generador de Contexto Dinámico en LangGraph Workflows
El Problema de la Falta de Contexto
Los modelos de IA han alcanzado niveles impresionantes de generación de respuestas y aplicabilidad, pero pesar de ello, existe un obstáculo importante: la falta de contexto. No importa cuán avanzado sea un sistema si toma decisiones basadas en información incompleta, desactualizada o irrelevante.
Imaginemos un sistema que no solo genera respuestas, sino que entiende la usabilidad del contexto con el que trabajan sus componentes, conectando datos en tiempo real, documentación técnica y conocimiento especializado. Esto es posible gracias a arquitecturas multi-agente donde RAG (Retrieval-Augmented Generation) trabaja como un cerebro contextual y todo orquestado con LangGraph.
En este artículo, veremos cómo LangGraph nos permite crear soluciones Agentics que entienden su contexto y toman decisiones más inteligentes, evitando los errores costosos de los modelos tradicionales.
Contexto Dinámico con RAG en Sistemas Multi-Agentes
Los sistemas multi-agente son como un equipo de expertos trabajando juntos. Pensemos en una sala de emergencias: tienes médicos, enfermeros y técnicos, cada uno con un rol específico. Pero sin un contexto compartido y actualizado del estado del paciente, sus decisiones pueden volverse erráticas, incluso peligrosas. Este mismo principio se aplica a nuestros sistemas de IA. Y aquí es donde RAG (Retrieval-Augmented Generation) es de gran ayuda, en lugar de depender únicamente de un modelo de lenguaje para generar las respuestas, RAG primero busca información relevante en una base de datos de conocimiento, y luego utiliza esa información para generar una respuesta más precisa y contextualizada.
En el contexto de los sistemas multi-agente, donde varios agentes colaboran para resolver problemas complejos, RAG actúa como un generador de contexto dinámico. Cada agente puede acceder a información específica y relevante en tiempo real, lo que mejora significativamente la calidad de las respuestas y la toma de decisiones.
Arquitectura de una Solución Basada en LangGraph
A continuación, analizaremos una pequeña implementación que utiliza LangGraph para crear un workflow de agentes con contexto dinámico y que nos servirá entender cómo podemos emplear estas herramientas y conceptos.
Si queremos descargar y probar la solución, en el siguiente enlace encontrarás el código y las instrucciones de configuración y ejecución.
A través de ejemplos prácticos y análisis técnicos desglosaremos sus principales componentes y las estrategias utilizadas durante la implementación para lograr obtener una solución que combina precisión y adaptabilidad en sistemas multi-agente.
Componentes Principales
La solución construida consta de varios componentes importantes:
app.py: La interfaz de usuario construida con Streamlit, donde los usuarios pueden hacer preguntas y recibir respuestas contextualizadas.document_processor.py: Módulo encargado de procesar documentos, dividirlos en fragmentos semánticos y almacenarlos en un vectorstore para su posterior recuperación.workflow.py: El orquestador principal de la solución, donde se define el flujo de trabajo de los agentes utilizando LangGraph.workflow_manager.py: Módulo que coordina la ejecución del flujo de trabajo y formatea las respuestas para su presentación.
Definición Grafo LangGraph
En el modulo workflow.py se define el grafo utilizando LangGraph:
# Inicialización del grafo
workflow = Graph()
# Nodos del grafo
workflow.add_node("optimize_query", optimize_query_node)
workflow.add_node("load_documents", document_loader_node)
workflow.add_node("grade_documents", grade_documents_node)
workflow.add_node("search", web_search_agent)
workflow.add_node("rag", process_similarity_web_search)
workflow.add_node("process", process_agent)
# Conexión de los nodos
workflow.set_entry_point("optimize_query")
workflow.add_edge("optimize_query", "load_documents")
workflow.add_edge("load_documents", "grade_documents")
workflow.add_conditional_edges(
"grade_documents",
decide_to_generate,
{"search_web": "search", "generate_answer": "process"},
)
workflow.add_edge("search", "rag")
workflow.add_edge("rag", "process")
workflow.add_edge("process", END)
En este flujo de trabajo, cada nodo representa una etapa del proceso y cada uno de ellos es un agente especializado con una tarea específica, desde la optimización de la consulta hasta la generación de la respuesta final. La clave está en cómo estos agentes comparten, ajustan y enriquecen el contexto dinámicamente.
La siguiente imagen muestra de manera clara cómo se ejecutan los diferentes pasos del workflow:
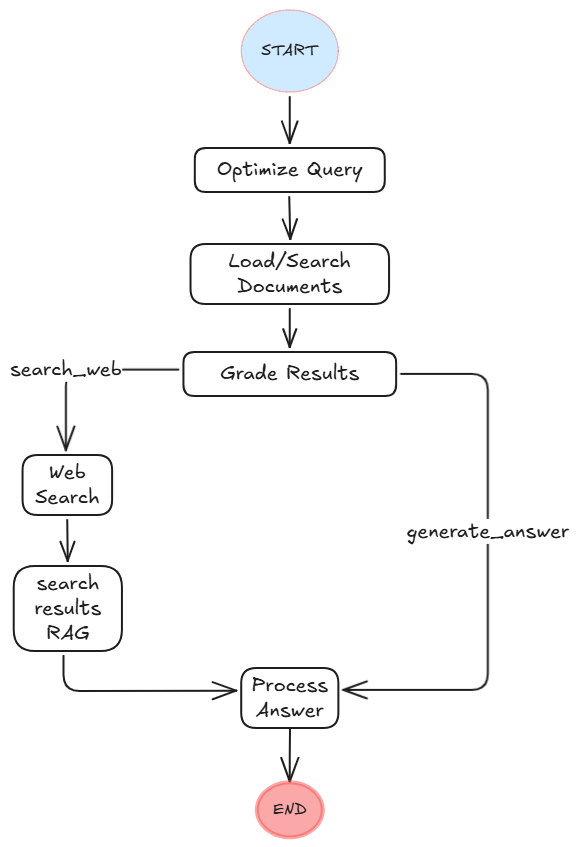
El flujo de trabajo de la imagen comienza con la optimización de la consulta del usuario, donde se reformula la pregunta del usuario para mejorar su eficacia en búsquedas vectoriales. Luego, el sistema carga, procesa y busca en documentos en la base de datos vectorial, a partir chunks semánticos y enriquecidos con metadatos contextuales. A continuación, el grafo evalúa la relevancia de los documentos encontrados mediante un modelo de grading, decidiendo si la información es suficiente o si se requiere una búsqueda en la web (usando Tavily) para alimentar el contexto. Si se necesita búsqueda web, los resultados se integran en un vectorstore temporal para realizar una búsqueda de similitud y extraer el contexto más relevante. Finalmente, el sistema procesa y genera una respuesta basada en el contexto acumulado, ya sea de la base de conocimiento local o de la web, asegurando una respuesta precisa y bien fundamentada.
Estrategias de la Solución
1. Procesamiento de Documentos con Contexto Semántico
Imagina que estás leyendo un libro y alguien recorta páginas individuales. Aunque cada página contiene información, pierdes el flujo narrativo, las referencias cruzadas y el contexto más amplio. Esto lo podemos resolver aplicando el siguiente procesamiento:
- Análisis de Límites Semánticos: Identificamos dónde termina realmente una idea completa, no solo dónde hay un punto o un salto de línea.
- Preservación de Contexto: Mantenemos un "context window" que captura el contexto antes y después de cada fragmento.
- Enriquecimiento de Metadata: Cada chunck de información se etiqueta con información estructural que ayuda a reconstruir el contexto original.
def create_semantic_chunks(self, documents: List[Document]) -> List[Document]:
processed_docs = []
for doc in documents:
clean_text = self.preprocess_text(doc.page_content)
initial_chunks = self.text_splitter.split_text(clean_text)
# Procesamiento semántico avanzado
for i, chunk in enumerate(merged_chunks):
context_window = self._get_context_window(merged_chunks, i)
semantic_info = self._identify_semantic_boundaries(chunk)
enhanced_content = f"{chunk}\n\nContexto expandido:\n{context_window}"
processed_docs.append(Document(
page_content=enhanced_content,
metadata=self._create_enhanced_metadata(doc, semantic_info, i)
))
-
Chunks: Dinámicos que se ajustan manteniendo una coherencia semántica.
-
Custom Metadata: Registran la posición en el documento, conteo de oraciones, y hasta el contexto adyacente.
2. Optimización de Consultas
def optimize_query(query: str) -> str:
prompt = PromptTemplate(
input_variables=["query"],
template=(
"Dado que la búsqueda se realizará en una base de datos vectorial que "
"almacena representaciones de texto en forma de embeddings, reformula esta consulta para hacerla: "
"1. Más breve. "
"2. Directa al punto. "
"3. Usando palabras clave específicas relevantes."
)
)
return model.invoke([HumanMessage(content=prompt.format(query=query))]).content.strip()
Este método consiste en trasformar la consulta del usuario en una consulta optimizada al motor de búsqueda de los textos en la base de datos de conocimientos para obtener resultados realmente relevantes.
Ejemplo:
Consulta: "¿Cómo manejar errores en Python?"
Consulta optimizada: "Manejo errores Python: try/except, tracebacks, logging"
3. Evaluación Relevancia Contextual
def grade_documents_node(state: AgentState) -> AgentState:
"""
Evalúa la relevancia de los documentos en base a la consulta del usuario.
"""
grading_prompt = f"""
Tarea: Evalúa la relevancia de los siguientes fragmentos de documentos en relación con la consulta del usuario.
Consulta del usuario: {query}
Contexto de los documentos:
{context}
Instrucciones:
1. Analiza cada fragmento individualmente.
2. Considera un fragmento relevante si contiene información que ayuda a responder la consulta, aunque sea parcialmente.
3. Ignora la repetición de información entre fragmentos; cada uno debe evaluarse por separado.
4. No descartes un fragmento solo porque parte de su contenido no sea relevante.
Si ningún contenido de los documentos es relevante o no hay contenido en los documentos contextuales, responde \"No\".
De lo contrario, responde \"Yes\".
"""
Esta técnica consiste en delegar un agente una evaluación de la información contextual y decidir si la respuesta del usuario se encuentra en el contexto obtenido de la base de datos de conocimiento son relevantes para construir una respuesta final.
Los criterios de evaluación del agente definen:
- Coincidencia semántica.
- Densidad informativa.
- Coherencia contextual.
4. Combinación Conocimiento Base/Web Results
def web_search_agent(state: AgentState) -> AgentState:
"""
Search for relevant documents on the Internet using web search tools.
Args:
state (dict): The current graph state
Returns:
state (dict): The updated graph state
"""
query = state["messages"][0]
# Realizar la búsqueda en Internet
search_result = search_internet.invoke({"query": query})
@tool
def search_internet(query: str) -> str:
"""Busca información en internet usando Tavily"""
results = tavily_search.run(query)
if isinstance(results, list):
return process_tavily_results(results)
return str(results)
# tool executor creation
tools = [search_internet]
tool_executor = ToolNode(tools)
Al determinar que la base de conocimientos no es suficiente para responder al usuario a través del nodo de grade results, el workflow utiliza herramientas de LangGraph, como Tavily, que se han configurado para este propósito. Tavily se encarga de obtener resultados de la consulta del usuario en internet. Luego, se aplica un proceso de RAG simplificado en memoria con FAISS para filtrar y seleccionar los resultados más relevantes para construir una respuesta final al usuario.
La ventaja de esta técnica son respuestas actualizadas con:
-
Documentación interna (PDFs, manuales).
-
Últimas investigaciones académicas y novedades.
-
Tendencias de la industria en tiempo real.
Conclusiones
La combinación de RAG y LangGraph está generando nuevas opciones en el desarrollo de sistemas multi-agente. Al proporcionar un contexto dinámico y relevante, se eleva la precisión y la eficiencia de los agentes de IA produciendo respuestas más acertadas y mitigando el problema de las alucinaciones en los modelos de lenguaje.
LangGraph, con su capacidad para orquestar flujos condicionales y dinámicos, permite a los agentes tomar decisiones más informadas y adaptativas en tiempo real. Los agentes pueden gestionar múltiples fuentes de información, filtrar lo irrelevante y centrarse en los datos que realmente importan.
RAG permite a los agentes acceder a información actualizada y relevante en tiempo real, especialmente útil en entornos donde los datos cambian constantemente o cuando no se dispone de LLMs entrenados con datos específicos del negocio.
Juntos, RAG y LangGraph están sentando las bases para una nueva generación de sistemas multi-agente que no solo responden, sino que comprenden y actúan con un contexto de información realmente útil para generar respuestas más adecuadas al usuario.
Términos clave
Conceptos Fundamentales
-
RAG (Retrieval-Augmented Generation) - Documentación LangChain RAG
Sistema que combina la recuperación de información con la generación de texto para proporcionar respuestas más precisas y contextualizadas.
-
LangGraph - Documentación Oficial
Framework para construir aplicaciones de IA basadas en grafos de flujo de trabajo.
-
Embeddings - OpenAI Embeddings
Representaciones numéricas de texto que capturan significado semántico.
Componentes del Sistema
-
ChromaDB - Documentación ChromaDB
Base de datos vectorial para almacenar y buscar embeddings de manera eficiente.
-
FAISS (Facebook AI Similarity Search) - FAISS
Biblioteca para búsqueda eficiente de vectores similares.
Herramientas y Utilidades
-
Tavily Search API - Documentación Tavily
API de búsqueda web optimizada para aplicaciones de IA.
-
Streamlit - Documentación Streamlit
Framework para crear interfaces de usuario interactivas en Python.