
Explotación de logs en Amazon Web Services
Publicado por Sergio Lecuona el
Una de las mayores ventajas a la hora de decidir implantar nuestras plataformas en el Cloud es sin duda el uso de infraestructuras adaptadas a la demanda y escalables según las necesidades, dos propiedades de las infraestructuras líquidas definidas con el concepto de Infraestructura como Código; en el caso de AWS, por ejemplo, estaríamos hablando del uso de Autoscaling Groups.

Esta funcionalidad nos permite que los grupos de autoescalado, ante un incremento de la necesidad de recursos de nuestra plataforma vaya creando instancias dinámicamente, y en caso de que la demanda baje también destruirá instancias para adaptarse al nuevo escenario.
Igualmente, en caso de que alguna instancia sea objeto de alguna incidencia que provoque su falta de respuesta a las peticiones de los clientes, nuestro grupo de autoescalado también la destruirá para crear una nueva y garantizar la continuidad nuestro negocio:
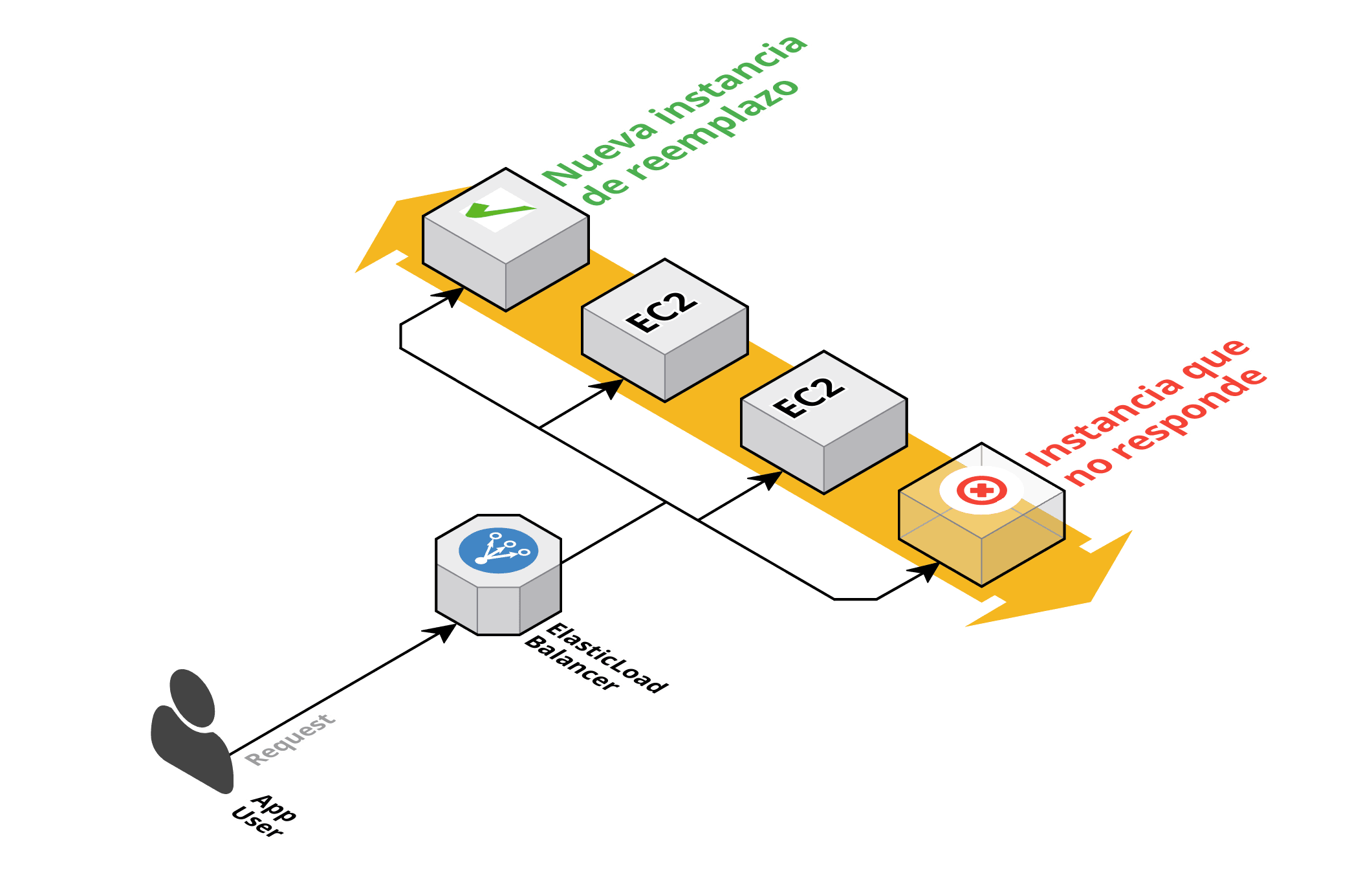
Sin duda esto es un paso de gigante a la hora de generar confianza en los clientes, pero ello no significa que debamos olvidarnos de la fase de análisis, del post-mortem, tras una incidencia para dar respuesta a estas preguntas:
- ¿Cuál ha sido la causa de la incidencia?
- ¿Me puede volver a ocurrir?
- ¿Debo tomar alguna medida que no tenía contemplada?
Históricamente esto se ha hecho siempre de la misma manera, conectándose a la instancia en cuestión y revisando los logs. Sin los logs muchas veces es imposible realizar análisis de problemas y encontrar soluciones a los mismos, qué os voy a contar que ninguno de vosotros no sepa ya.
Pero aquí es donde se chocan de frente nuestra necesidad de análisis y nuestra capacidad de recuperación. Si mi instancia la he “matado” y he generado una nueva, se plantea imposible el acceso a unos logs que ya no existen. Y de esto va este post, de persistir y mantener disponible esos archivos de logs que genera mi aplicativo, ya sean los logs de acceso y error generados por servidores web como el Apache o Nginx, de los logs del propio sistema operativo, el catalina.out de mi Tomcat o el micustomlogqueyohegenerado.log que esté creando mi aplicación, el que sea, si se genera probablemente lo necesite y no es plan verlo volar hacia el horizonte junto a mi instancia desaparecida.
¿Qué hacíamos allá en los albores de AWS?
Muy fácil (o no tanto, que más de un dolor de cabeza tuvimos por culpa de esto):
Si nuestra instancia va a morir, antes de que desaparezca, guarda esos archivos. Cómo lo hacíamos no tiene ningún misterio, simplemente creábamos un script que se ejecutaba durante la parada de la máquina, este script generaba un fichero comprimido con todos mis logs y los subía a un bucket de S3/Glacier (para los que aún no hayan oído hablar de las bondades de S3 lo resumiré diciendo que es el almacenamiento de AWS en el que se me garantiza la durabilidad y disponibilidad de mis datos con muchos, muchos nueves de porcentaje).
Sin duda esto garantizaba:
- La durabilidad y disponibilidad de mis ficheros de logs.
- Persistir los ficheros en caso de parada de la instancia.
Pero también tiene una serie de inconvenientes:
- Si el script de parada falla mis ficheros no se subirán a S3.
- Ralentizaba la parada de la instancia.
- Bastante poco tiempo tenemos como para tener que andar buscando ficheros en S3, descargándomelos y descomprimiéndolos.
Había otra opción, utilizar el S3 montado como NFS gracias a herramientas como el s3fuse pero su rendimiento para este caso era tan malo y provocaba tantos problemas que no merece la pena ni comentarlo.
Para nuestra alegría, en junio de 2016, Amazon Web Services por fin anunció un nuevo servicio, el Elastic File System (EFS para los amigos).
Adoptando el nuevo escenario
La aparición del EFS permitía montar por NFS directorios que podrían compartir varias instancias EC2 y encima pagábamos por el espacio ocupado sin necesidad de aprovisionar. No solo para la persistencia de logs, sino para múltiples topologías este servicio supuso un paso adelante:
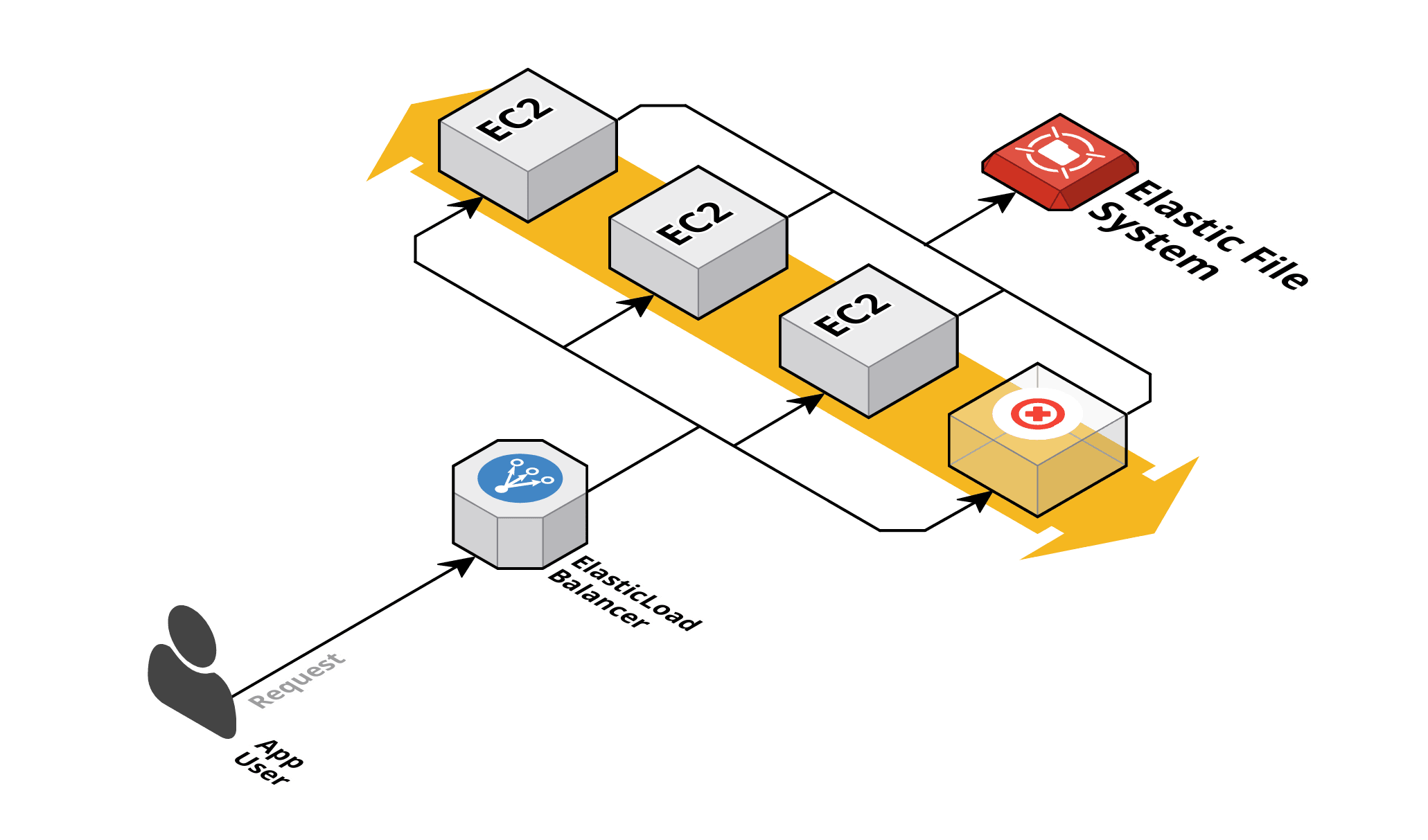
Este escenario plantea mejoras claras respecto al caso anterior:
- Nos olvidamos de crear servicios en las instancias y de la compresión y copia de los ficheros.
- Nos olvidamos de los habituales problemas de llenado de FileSystems por culpa de una mala gestión de rotado de logs.
Pero nuevamente plantea inconvenientes:
- Nos obliga a adaptar la configuración de las aplicaciones para ir generando un nombre diferente para el log de cada nodo (o para crear un subdirectorio específico por cada nodo).
- Aunque el EFS se paga solo por el espacio ocupado, su coste es mayor que el de los volúmenes EBS.
- El rendimiento de escritura en disco se ve penalizado respecto a los EBS.
Así que, tras mucho hablar (o escribir) por fin llego a mi escenario ideal (pero seguro que mejorable) y del que os venía a hablar. Veamos primero el dibujo y luego lo explicamos:
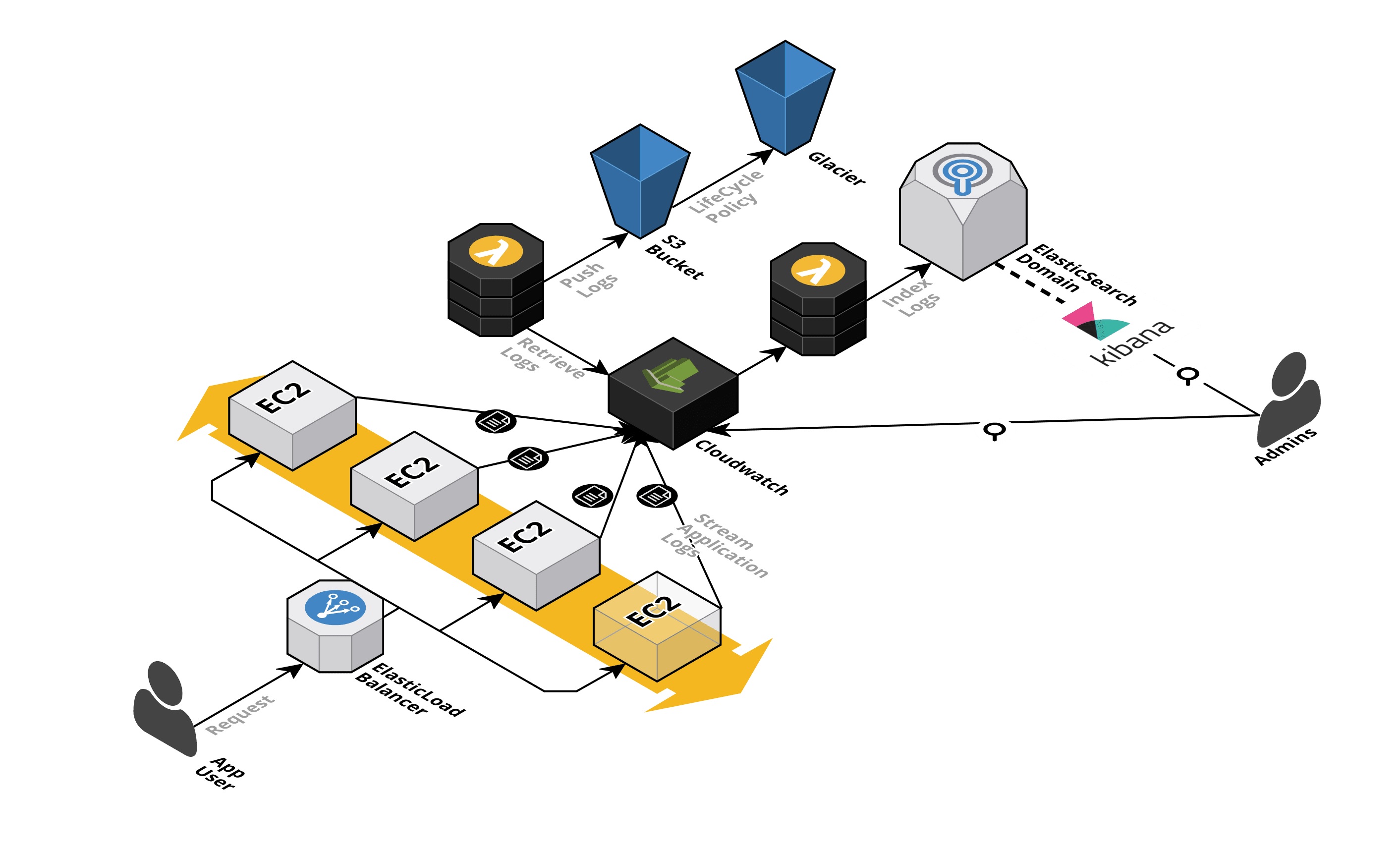
No os asustéis por todas las piezas que añado ahora, os prometo que todo este escenario lo he montado tan solo en unas horas para este Post.
Aparece Cloudwatch en escena
Seguramente conozcáis el servicio de AWS Cloudwatch porque ya muchos lo utilizáis, pero también es verdad que el 90% (y seguramente no exagero) de los usuarios de Cloudwatch tan solo tienen generados Dashboards con cuatro gráficas de métricas básicas.
Nuestra idea es:
- Utilizar Cloudwatch como repositorio de logs para que las instancias vayan lanzando en streaming sus logs contra él.
- Usar una función Lambda para indexar esos logs sobre un dominio de Elastic Search que ofrece como servicio AWS.
- Aprovechar la integración de Kibana con ese Elastic Search para generar análisis y paneles de visualización sobre los logs.
- Lanzar una función lambda de manera periódica que extraiga los logs de Cloudwatch y los copie a S3.
- Crear políticas de ciclo de vida de los logs de S3 para migrarlos a Glacier.
¿Y qué pretendemos con esto?
- Le pase lo que le pase a nuestra instancia, nosotros tendremos ya la información en Cloudwatch para su análisis. No os preocupéis por los logs o por persistirlos, dejadlos ir, que vuelen y sean felices allá donde vayan.
- Directamente desde Cloudwatch podremos indexar los logs sobre un Elastic Search. Esto nos permite su explotación con Kibana ya que, Out of the Box, AWS ofrece un endpoint de Kibana al crear un domino de Elastic Search. Por supuesto, podríais adaptar esta solución a vuestras propias herramientas que se integren con Elastic Search, como Grafana, por ejemplo.
- Además, Cloudwatch nos permite filtrar esos logs según su contenido y generar métricas sobre los filtros, sobre las que posteriormente podemos crear alarmas y notificaciones vía correo electrónico. ¿A que estaría genial enterarse por correo de que un nodo de mi cluster está sufriendo un Out Of Memory?.
- Almacenar los ficheros de logs, ya sea por auditorías o requerimientos legales, alojándolos en S3. Como además, probablemente nunca lleguemos a consultar esos logs, generaremos una política de ciclo de vida para que cada X meses esos logs se trasladen a Glacier (el servicio de “Cold Archive” de AWS).
Paso 1: Que nuestros logs lleguen a Cloudwatch:
Para este laboratorio he instalado un servidor web nginx sobre una instancia EC2 de Ubuntu, utilizando como página web de ejemplo una template gratuita ofrecida por free-css.com
La gestión de qué logs hay que copiar, y de la copia en sí se realiza a través de unos agentes que necesitaremos tener instalados en nuestras instancias, el awslogs agent.
Para instalarlo en primer lugar nos descargamos el instalador:
curl https://s3.amazonaws.com/aws-cloudwatch/downloads/latest/awslogs-agent-setup.py -O
Para los siguientes pasos damos por hecho que tenéis instalado Python en vuestra instancia.
Ahora procedemos a lanzar la instalación y configuración del agente:
root@ip-10-0-0-152:~# python ./awslogs-agent-setup.py --region eu-west-1
Launching interactive setup of CloudWatch Logs agent ...
Step 1 of 5: Installing pip ...libyaml-dev does not exist in system DONE
Step 2 of 5: Downloading the latest CloudWatch Logs agent bits ... DONE
En este paso de la configuración no hace falta especificar vuestro Access Key y Secret Key, siempre y cuando la instancia tenga asociado un role que le permita escribir sobre Cloudwatch Logs.
Step 3 of 5: Configuring AWS CLI ...
AWS Access Key ID [None]:
AWS Secret Access Key [None]:
Default region name [eu-west-1]:
Default output format [None]:
En el siguiente paso definiremos el LogGroup y el fichero de log que queremos volcar sobre Cloudwatch (en este caso uso el LogGroup con el mismo nombre que el fichero, que es el /var/log/nginx/access.log de mi nginx):
Step 4 of 5: Configuring the CloudWatch Logs Agent ...
Path of log file to upload [/var/log/syslog]: /var/log/nginx/access.log
Destination Log Group name [/var/log/nginx/access.log]:
También tenemos que elegir en este paso cómo se llamará el Stream que generará la instancia en el LogGroup (viene a ser algo así como el subdirectorio por debajo del Log Group, para identificar qué log es de cada instancia). En mi ejemplo seleccióné el Id de la instancia:
Choose Log Stream name:
1. Use EC2 instance id.
2. Use hostname.
3. Custom.
Enter choice [1]: 1
Ahora tenemos que indicar el formato de la fecha y el orden de subida de los logs (descendiente o ascendiente):
Choose Log Event timestamp format:
1. %b %d %H:%M:%S (Dec 31 23:59:59)
2. %d/%b/%Y:%H:%M:%S (10/Oct/2000:13:55:36)
3. %Y-%m-%d %H:%M:%S (2008-09-08 11:52:54)
4. Custom
Enter choice [1]: 2
Choose initial position of upload:
1. From start of file.
2. From end of file.
Enter choice [1]: 2
Por último, nos preguntará si hay más logs que queramos exportar a Cloudwatch. En mi caso repetí los pasos anteriores para configurar también el /var/log/syslog y el /var/log/nginx/error.log
More log files to configure? [Y]: y
Cuando hemos terminado, toda nuestra configuración se vuelca sobre el fichero /var/awslogs/etc/awslogs.conf
Al final del fichero está nuestra configuración, donde podemos añadir manualmente nuevos logs, o también podemos relanzar el instalador ejecutando el comando:
sudo python ./awslogs-agent-setup.py --region eu-west-1 --only-generate-config
Lo ideal sería que esta configuración forme parte de nuestra AMI (la plantilla que utilizamos para la creación de las instancias de nuestro grupo de autoescalado), aunque también podemos hacer uso de AWS OpsWorks para gestionar todas estas configuraciones con Chef.
Llegados a este punto ya tenemos la parte más importante, si vamos a nuestra consola de Cloudwatch veremos que hay un nuevo LogGroup con el nombre que le habíamos dado:
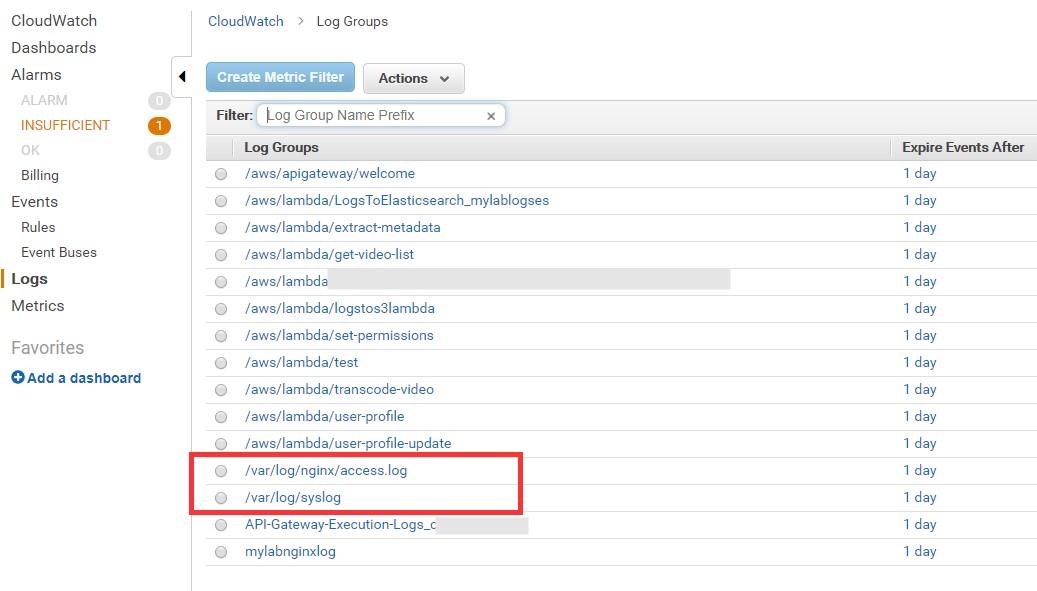
Y donde antes nos teníamos que conectar por SSH a nuestras instancias para ver esto:
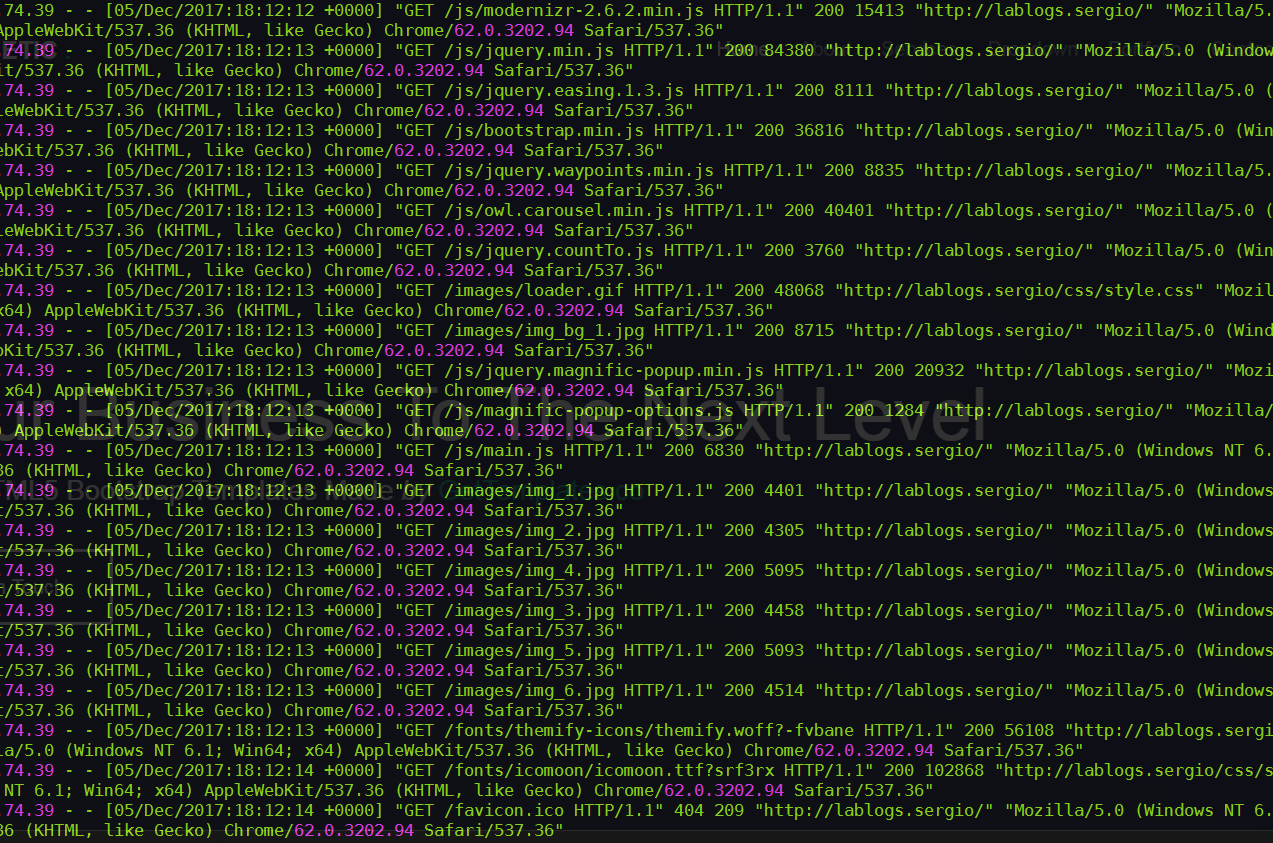
Ahora podemos ir a la consola de CloudWatch y encontrar esto:
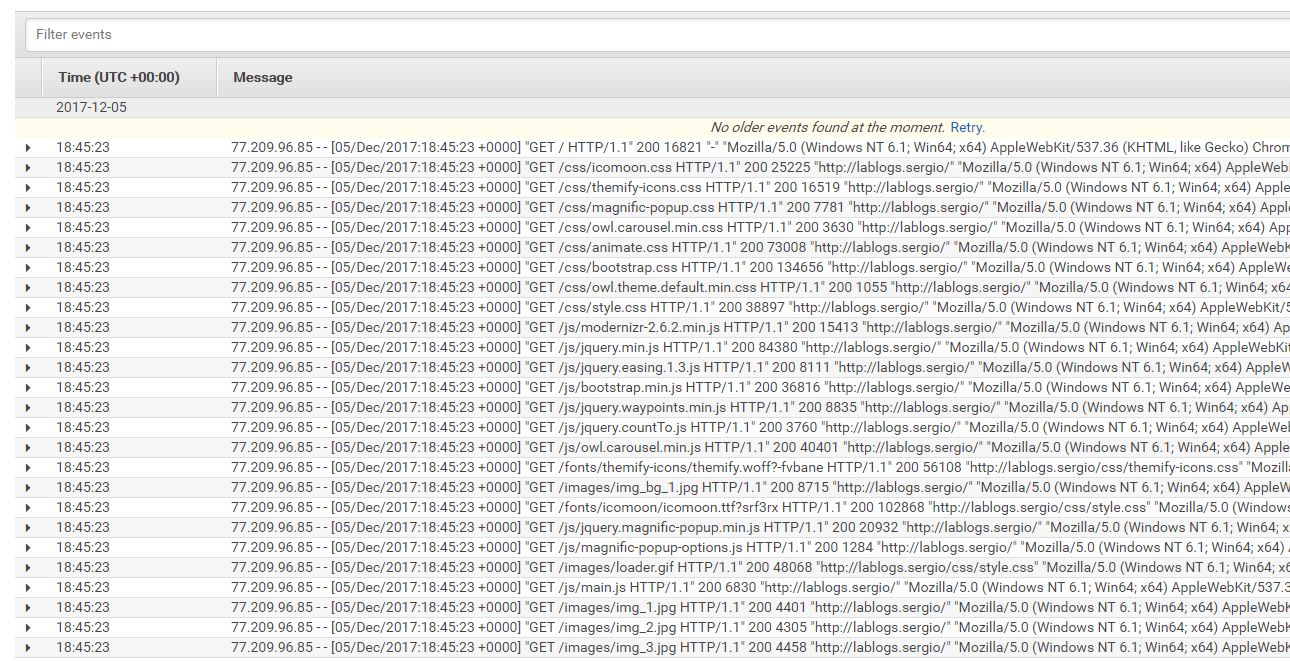
(Hice esta parte con un dispositivo 4G para que no sepáis cuál es la IP de mi casa, ¿o qué os creíais?) 😊
Paso 2: Indexando nuestro log:*
Ahora que ya tenemos nuestro log en Cloudwatch es el momento de exportar estos datos al servicio de Elasticsearch.
En primer lugar necesitamos disponer de un dominio de AWS Elastic Search. Ya que queremos acceder públicamente al portal de Kibana necesitaremos crearlo fuera de la VPC, pero aseguraos de que tiene la Policy necesaria para que no tengamos disgustos con accesos no esperados:
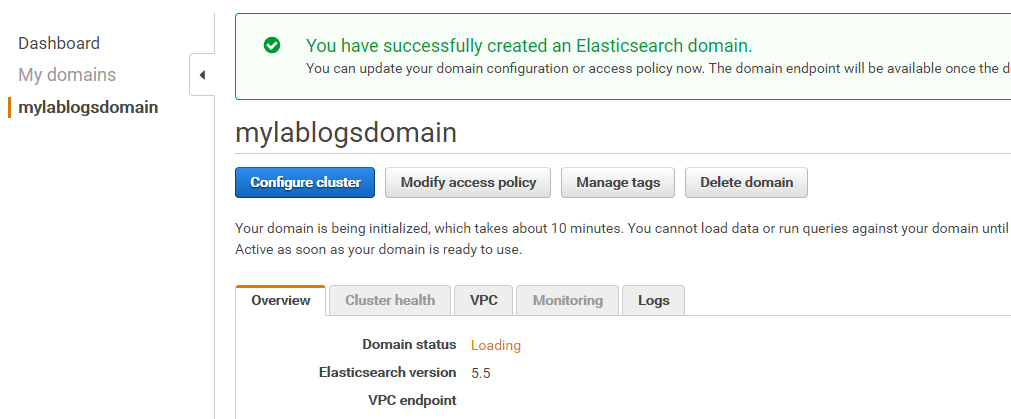
Una vez tenemos disponible el dominio, directamente tenemos la opción de crear un Stream del LogGroup hacia el dominio de Elasticsearch:
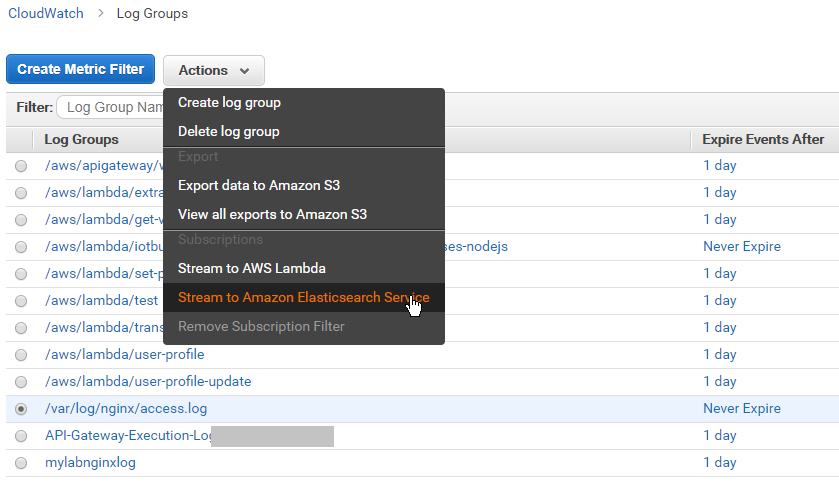
Tendremos que elegir qué dominio de Elasticsearch queremos utilizar y asignar un role a la Lambda que internamente creará esta funcionalidad. (este role necesitará tener permisos de ejecución de Lambda, lectura de Logs y escritura en Elasticsearch):
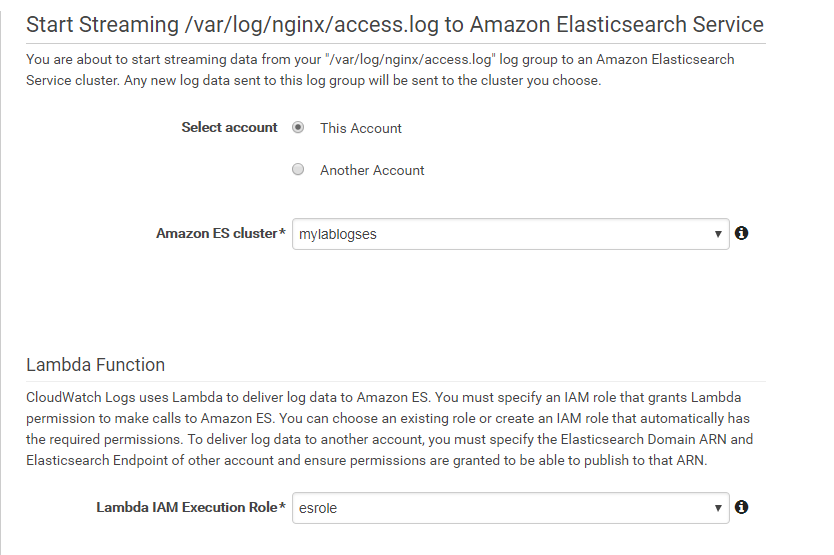
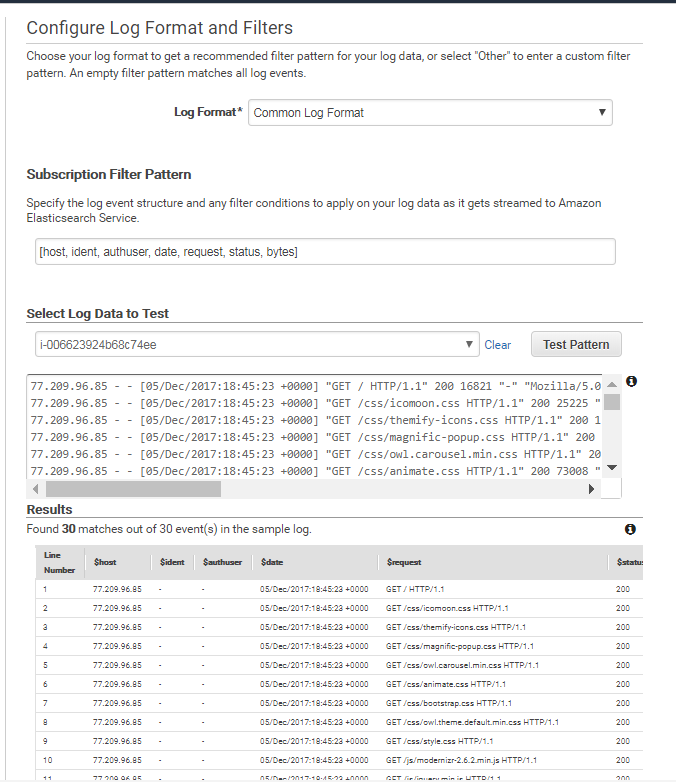
También podremos personalizar el formato de nuestro log para que Elasticsearch sea capaz de generar el indexPattern correspondiente. En este caso usé el “Common Log Format” que automáticamente identificó los campos del access.log del Nginx, pero es también personalizable. Como veis en la siguiente captura podemos testear si nuestro formato parsea correctamente el log antes de comenzar el streaming:
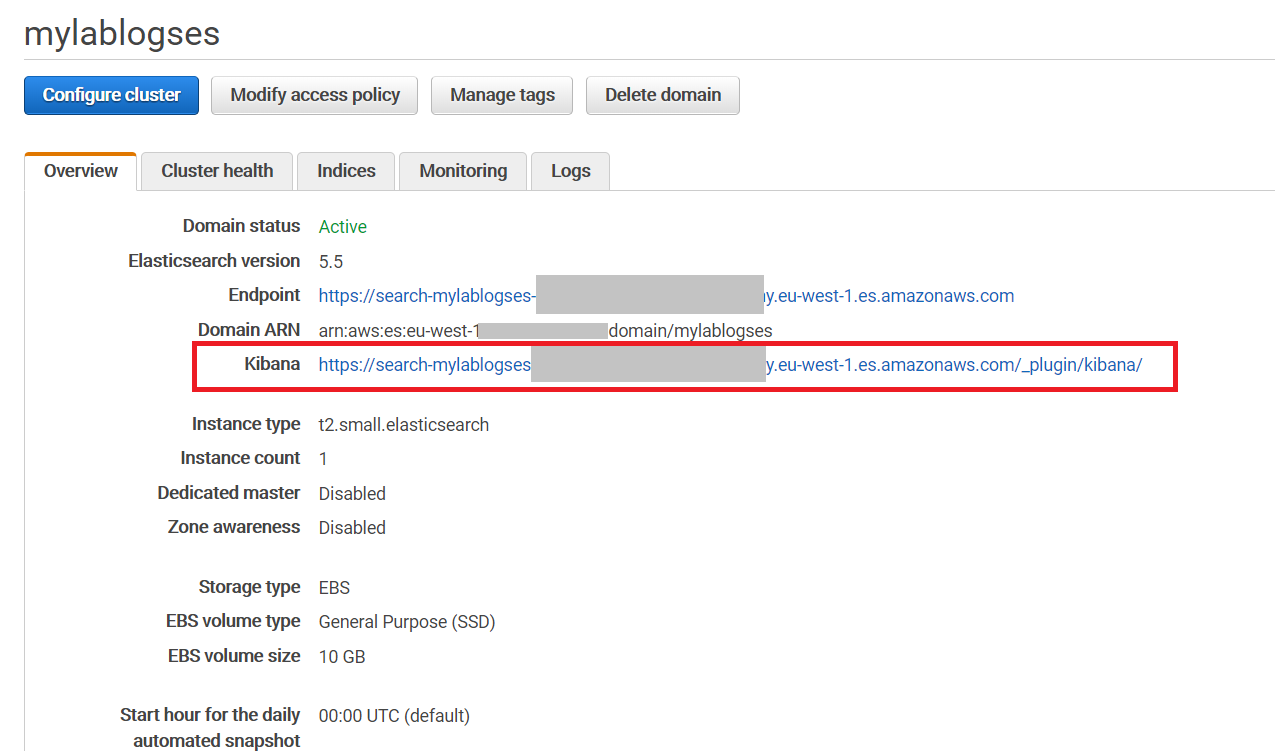
Una vez finalizado el proceso, vuelvo a la consola de Elasticsearch para que apreciéis cómo este servicio integra una consola de Kibana que no necesitamos instalar, directamente para su uso. Como comentaba previamente sois libres de instalar Grafana o cualquier otro producto que sea capaz de integrarse con Elasticsearch:
Y accediendo a ese endpoint llegaríamos a nuestro Kibana donde tenemos ya indexado todo nuestro log:
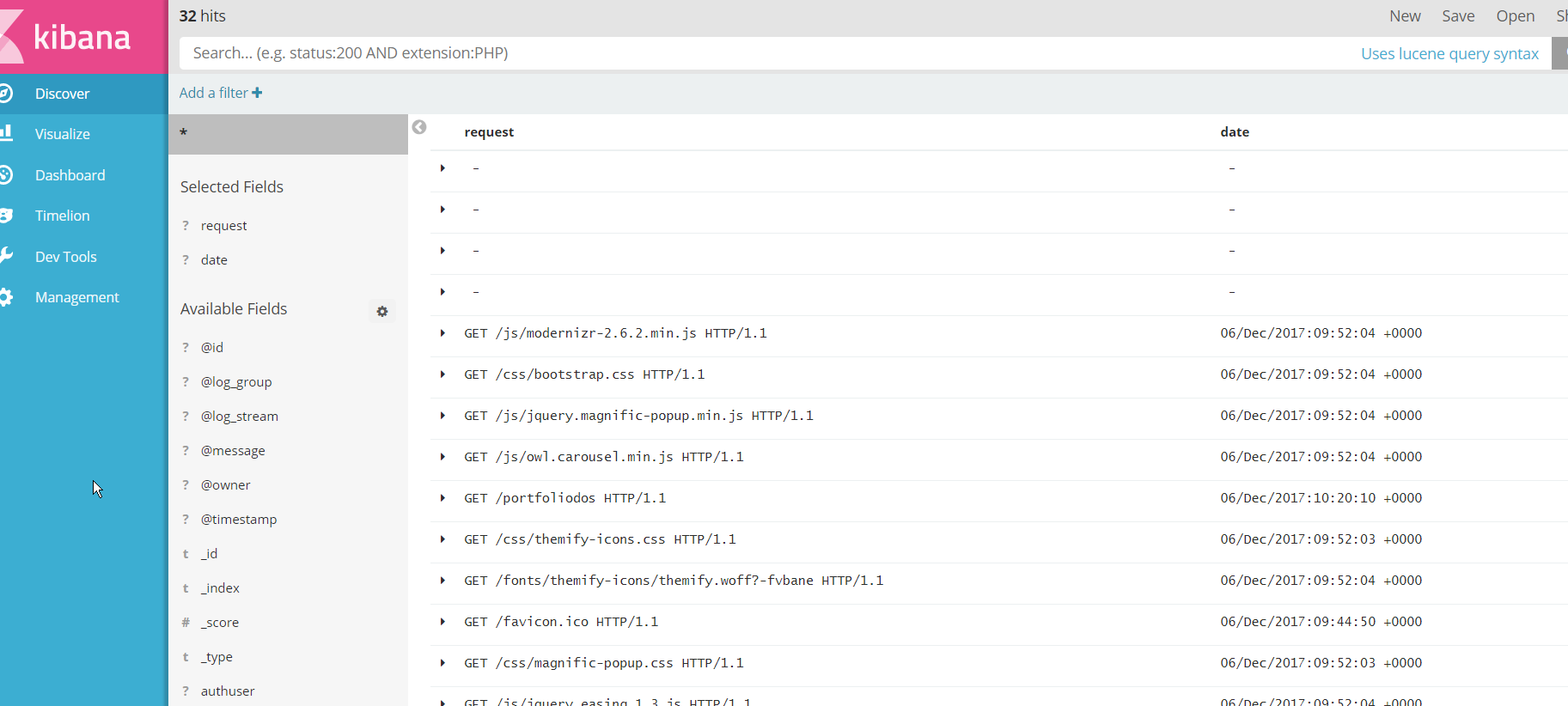
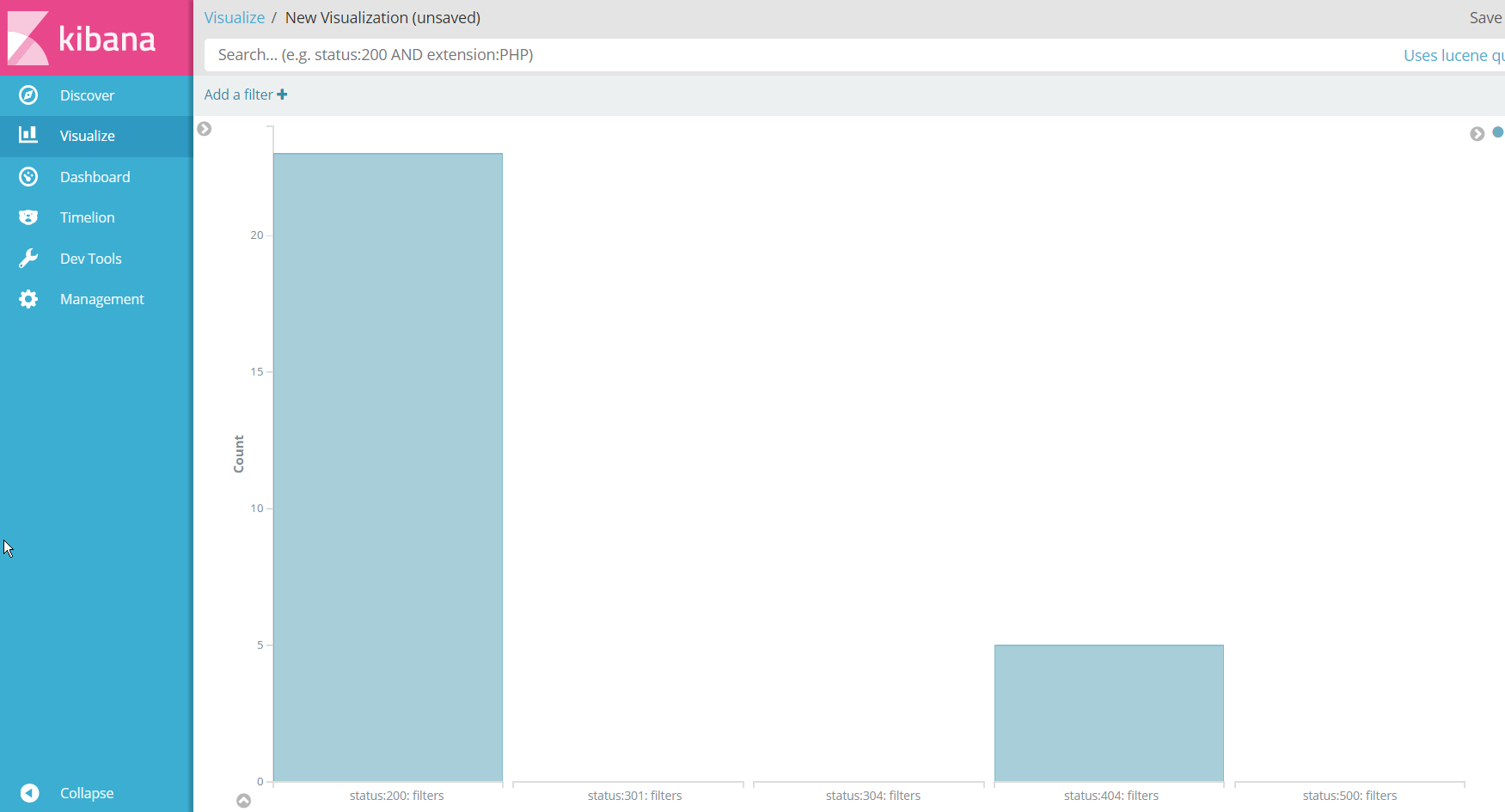
El propósito de este Post no es mostrar la potencia de herramientas como Kibana, pero si quiero que veáis que podemos pasar, de una búsqueda en un fichero vía SSH a tener un panel para visualizar y analizar, casi en vivo, lo que está ocurriendo en nuestros logs. Por ejemplo, aquí tenéis un panel en el que se va actualizando cuántas peticiones tenemos a nuestra web en función del código HTTP de respuesta:
Paso 3: Vale, pero yo quiero almacenar mis ficheros de logs
Como explicábamos al principio, es probable que queráis mantener almacenados los ficheros de logs. Desde el propio Cloudwatch se pueden exportar a S3, pero como soy un vago, lo que yo quiero es que trabaje AWS, no yo. Así que vamos a crear una función Lambda que ejecute de manera periódica ese Job para extraer la información de nuestro LogGroup y alojarlo en S3.
Para ello primero vamos al panel de Lambdas (que desde el último re:Invent se integra con Cloud9 IDE, facilitando el desarrollo y despliegue de las funciones). Ahí, basta con estas pocas líneas de código para crear el job. Yo he elegido hacerlo con Python, pero podéis elegir Node.js si sois más hípsters que yo.
import boto3
import collections
region = 'eu-west-1'
def lambda_handler(event, context):
client = boto3.client('logs')
response = client.create_export_task(
taskName='export_task',
logGroupName='/var/log/nginx/access.log',
fromTime=1400000000000,
to=1999999999999,
destination='lablogs-sergio-exported',
)
Como veréis el código es tremendamente sencillo ya que solo necesitamos crear una tarea de exportación especificándole el LogGroup, el nombre del bucket de S3 sobre el que hay que alojarlo y la franja de tiempo de los datos que serán exportados.
Una vez tenemos nuestra Lambda necesitamos generar, desde Cloudwatch, una regla que responda a eventos planificados. Como vemos en la captura creamos en este caso un evento periódico (en formato cron) para ejecutarse cada día a la 1 de la madrugada y que como destino del evento tiene la ejecución de la función Lambda que acabamos de crear:
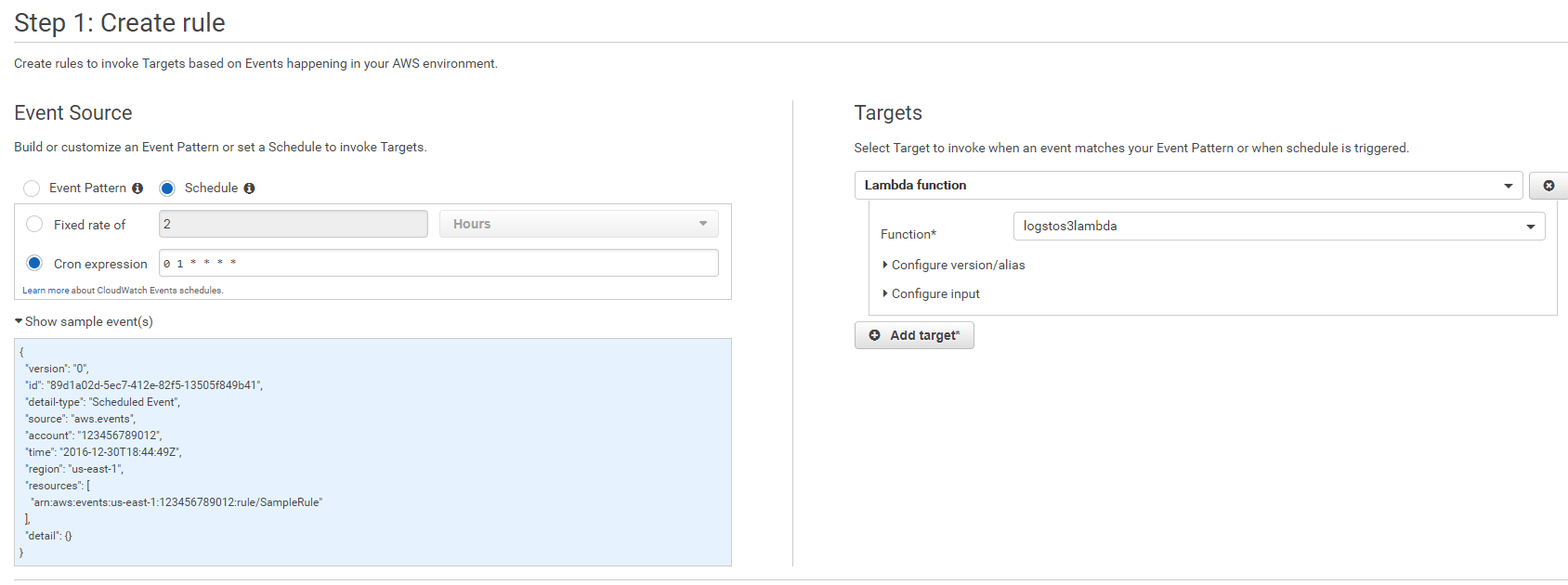
Esto provocará que cada día aparezca en nuestro bucket de S3 un fichero comprimido con los logs que hemos exportado:
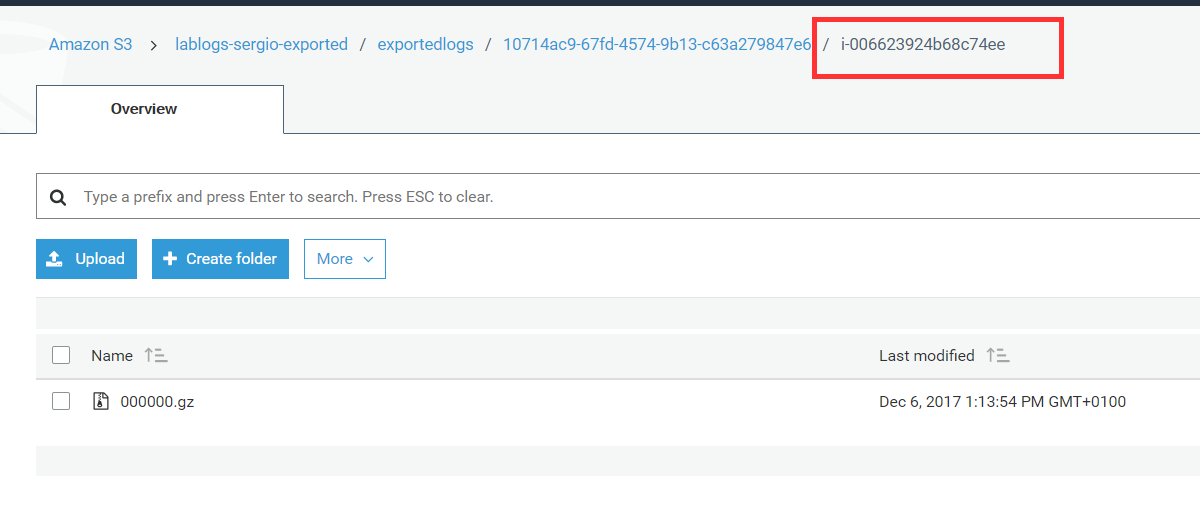
Pero también sé que probablemente nunca utilicéis esos ficheros, así que es tontería tenerlos en S3 costando dinero por estar disponibles inmediatamente cuando no lo necesitáis. Y esto lo solventamos añadiendo a nuestro bucket una política de ciclo de vida que nos traslade esos logs a Glacier cada 1, 2 ó los meses que queráis. Esto nos reducirá el coste de almacenarlos pero mantendrá la durabilidad. Simplemente tendremos algo de latencia si hace falta recuperarlos, pero las ocasiones deberían ser mínimas.
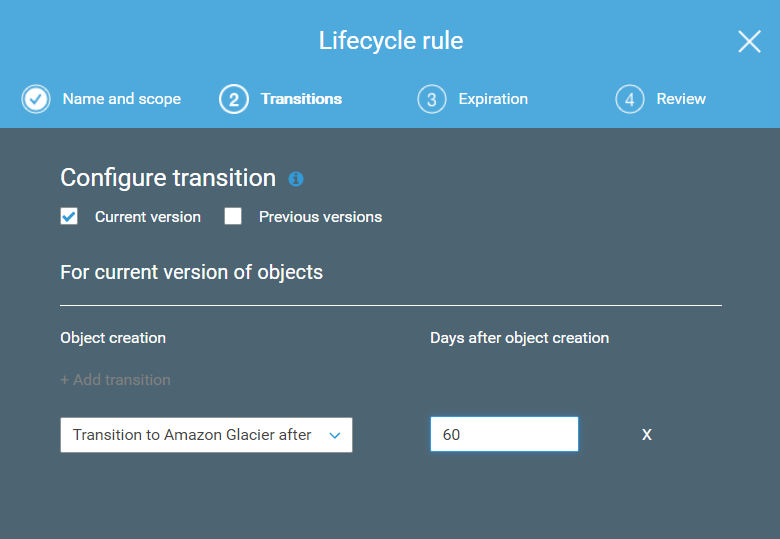
Concluyendo
Sé que probablemente algunos al leer este Post estéis pensando que seguís prefiriendo el uso de vuestras herramientas habituales como Graylog; sin duda son herramientas geniales y potentes para la gestión de los logs, pero nuestro propósito era enseñar un entorno de gestión completo (y Serverless) haciendo uso de los servicios ofrecidos por Amazon Web Services.
Con esto acabo el Post. Espero haberos convencido de las ventajas de dedicar algo de tiempo inicial a la creación de un entorno de explotación de la información que generan nuestras aplicaciones y servidores. Habréis visto que la balanza entre esfuerzo y beneficios está claramente a favor del uso de soluciones como la expuesta. Así que, y con esto termino, recordad:

Si te ha gustado, ¡síguenos en Twitter!. Y si vives en Madrid, ven a conocernos en nuestro grupo de Meetup.