
Git - Como gestionar y cuidar nuestro código
Publicado por Antonio García Candil el
Un repositorio de código puede ser útil para múltiples propósitos en el ciclo de vida de una aplicación. Su misión principal es la de sincronizar e integrar el código desarrollado por un equipo en un producto o componente software, pero también nos permite albergar toda la documentación relativa al desarrollo, o gestionar las distintas entregas y la promoción de código.

Con esta introducción ya empezamos a ver la relevancia que puede tener un servidor Git dentro de una organización. Gracias a él disponemos del histórico de todo el trabajo realizado, puede contener las causas que han propiciado realizar cualquier cambio en el producto y nos ofrece información privilegiada de qué contienen las distintas entregas que se han liberado siguiendo los flujos de código entre las distintas ramas del propio repositorio.
Todo esto es posible gracias a Linus Torvalds cuando liberó Git, revolucionando el concepto de repositorio de código respecto a los sistemas anteriores como Harvest, CVS o Subversion.
... As Code
Toda esta información y capacidad de gestión que nos brinda nos ha llevado a plantear paradigmas "as code" en cualquier ámbito relacionado con el ciclo de vida de un producto software. No es objetivo entrar mucho en el detalle de estas técnicas, ya que pueden dar contenido a otro post completo, pero vamos a destacar:
- Configuración: Disponer de la parametrización de la aplicación en tiempo de ejecución.
- Pipelines (CI/CD): Gestionar toda la información del proceso de construcción, empaquetado, validación y despliegue del producto software.
- Infraestructura: Identifica igualmente los requisitos de infraestructura y configuración de la misma para que nuestro producto pueda ejecutarse.
Tener toda esta definición en un repositorio nos permite definir ciclos automatizados y repetibles de cualquier evento pasado o presente, aportando mayor seguridad para los cambios que se puedan plantear en el futuro.
¿Cómo de maduro es mi equipo?
Del propio repositorio también se puede extraer bastante información inherente al producto software desarrollado, por ejemplo, la relativa al propio equipo, a la parte de negocio (Product Owner y definición funcional) o a la calidad del código:
- Es posible identificar rápidamente equipos caóticos y/o desorganizados, observando como se gestionan ramas y flujos de código.
- Equipos poco motivados suelen presentarse con información y documentación obsoleta, comentarios poco explicativos, cambios muy frecuentes donde se añade, se modifican y se deshacen las mismas funcionalidades.
- También es posible detectar problemas en la definición funcional, donde Product Owners y Usuarios ofrecen poca visión del producto y de las historias de usuario. En estos escenarios se propician los habituales abandonos de ramas que nunca se han integrado en las distintas entregas, o historias de usuario poco o mal definidas que implican numerosos cambios en momentos de aceptación.
- Respecto a la calidad del producto, en cualquier repositorio donde el número de ramas hotfix es elevado, nos indica que hay que revisar y analizar los requisitos de calidad, en cuanto a cobertura de pruebas, análisis estáticos y la automatización de pruebas funcionales.
Todo estos problemas que podemos detectar en Git a simple vista, afectan directamente en el Time To Market y a la entrega de funcionalidad en producción.
Git branching models
Una vez detectada la necesidad de organizar y aplicar buenas prácticas en un repositorio de código, es el momento de decidir qué modelo de trabajo se va a seguir.
No es recomendable intentar definir un modelo de trabajo personalizado al existir bastantes convenciones que definen como se debería trabajar en Git. Tampoco voy a entrar en detalle de cómo aplicar estos modelos, ya que existe bastante documentación al respecto. Las alternativas más comunes son las siguientes:
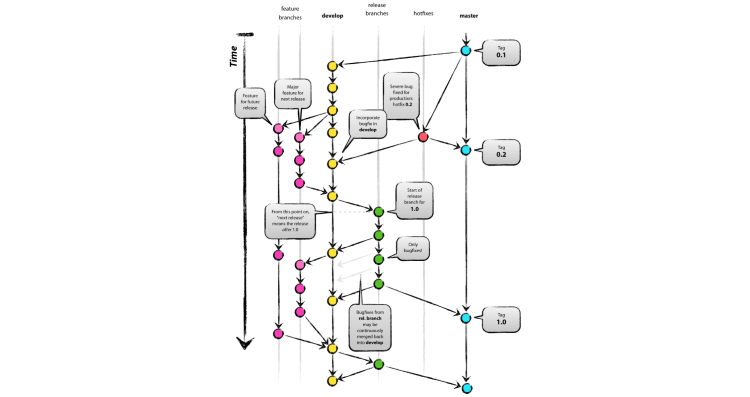
- GitFlow: Suele considerarse el estándar para trabajar con Git, es el modelo más extendido y utilizado.
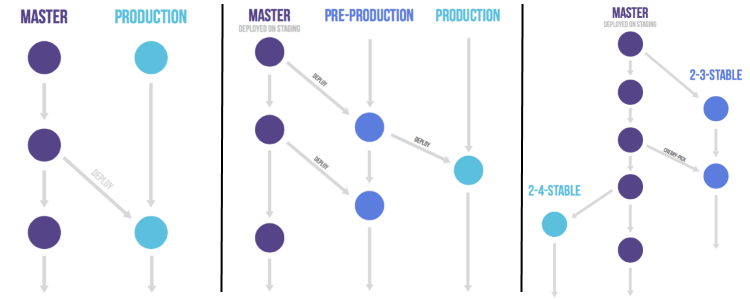
- GitLab Flow: Gitlab propone una serie de alternativas de ramas que cubren algunas lagunas que puede tener GitFlow. Por ejemplo, la definición de rama de producción o rama por entorno, donde la rama master es la que genera la Release Candidate y permite promocionar esta release a los distintos entornos. Otra alternativa que propone es la definición de ramas estables por release, cuando sea necesario disponer de varias releases estables en producción y que sea necesario aplicar mantenimiento, tanto evolutivo, como correctivo
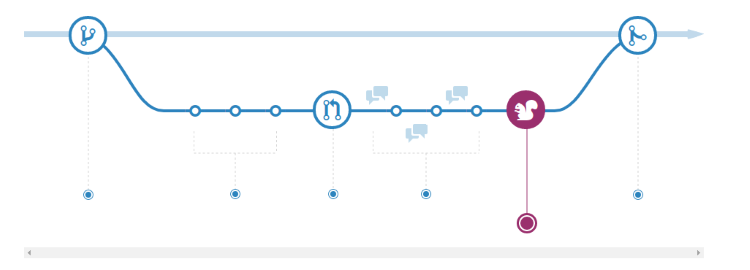
- GitHub Flow GitHub intenta simplificar la gestión de ramas, trabajando directamente sobre la rama master y generando integrando las distintas features directamente a esta rama.
- Forking Workflow: Donde se recomienda que cada usuario de un repositorio realice un Fork del mismo y trabaje en repositorios privados. Suele ser una foto común y necesaria en modelos Open Source, donde únicamente sea interesante disponer de los Pull Request que llegan a develop y master. En escenarios corporativos, suele ser más recomendable el uso de ramas que posibiliten que cualquier miembro tenga visibilidad del trabajo que realicen sus compañeros.
- Staging branches: Hay modelos donde se diferencian ramas releases y ramas staging como paso previo de validación de una release candidate.
Es buen momento de pararnos a pensar
La decisión de qué modelo se va a usar no es la única decisión que hay que tomar. Es importante tener en cuenta más detalles para disponer de un repositorio bien organizado y que sea útil cuando vayamos a desarrollar el componente funcional.
Readme.md
Parece que solo es útil cuando se va a publicar un repositorio Open Source, pero no, es necesario en cualquier repositorio, aunque sea privado.
Es bastante común, en la mayoría de las organizaciones, encontrar la documentación de los repositorios con una única línea con su nombre o con escasa y obsoleta información de cuando se creo.
Al menos, el readme.md debería de contener:
- Descripción funcional del repositorio y enlaces a urls de ejemplos donde se pueda ver en funcionamiento
- Tecnologías usadas
- Dependencias
- Cómo construir el proyecto, además de información de CI/CD que aporte el propio repositorio (JenkinsFile, Travis,...)
- Cómo desplegar el proyecto y consideraciones de configuración
- Otras consideraciones de uso
- Información de contacto del equipo de desarrollo
Comentarios de los commits
Es importante a nivel de equipo definir un formato en los comentarios de los commits que se realicen sobre el repositorio, es decir, que sea posible identificar la motivación del commit y toda la información necesaria para entender el por qué y para qué se ha realizado ese cambio.
También es interesante que podamos disponer de trazabilidad con cualquier issue o tarea que haya originado el cambio.
Como ejemplo, definir las siguientes técnicas puede ayudar bastante al propio equipo y sobre todo a las nuevas incorporaciones que puedan ir surgiendo:
- Dividir el comentario en dos partes principales: un asunto (50 caracteres) y un mensaje (72 caracteres/línea y opcional) separadas por una línea en blanco. Definir un número de caracteres por línea ayuda en la visualización de cualquier herramienta que intervenga en el proceso.
- Convención en los asuntos de los commits, añadir palabras claves de añadir funcionalidad (ADD), actualizarla (UPDATED), corrección de errores (FIXED) o borrado de código obsoleto (DELETED).
- Usar el imperativo. Internamente Git usa el imperativo en los mensajes que genera. Por ejemplo, Merge branch 'feature-refactor’.
- En diversos foros, recomiendan las descripciones en Inglés por simplicidad del lenguaje y para estandarizar con los comentarios automáticos del propio servidor.
Un mensaje de commit no es para explicar cuáles son los cambios, ya que se pueden consultar en el diff del commit.
La principal utilidad es detallar el por qué detrás de esos cambios; si se presentan distintas alternativas en el momento de implementar la solución, describir la que se ha adoptado y las razones de elegir esa en particular. También es importante anticipar el impacto que se pueda producir en el resto de la aplicación.
Gestión de Versiones
Si ya sabemos el modelo de trabajo, es importante también detallar y documentar (el readme.md sería el sitio ideal) cómo se van a gestionar las versiones de las distintas ramas.
Se debe de intentar evitar, por ejemplo, que los artefactos que se generen de las distintas funcionalidades en desarrollo, se sobrescriban en un repositorio centralizado de artefactos.
También es importante pararse un momento a pensar cómo se van a desplegar estas versiones en los distintos entornos de que se dispongan.
¿Qué modelo de ramas utilizo?
De los distintos modelos enumerados, no es posible recomendar uno para cualquier tipo de desarrollo. Si ya disponemos de información más detallada del contenido del repositorio, cómo se va a construir, versionar y desplegar, podemos identificar un modelo que nos pueda beneficiar en el día a día de nuestro desarrollo.
GitFlow
En principio, tiene sentido plantear usar GitFlow para cualquier repositorio.
Es el modelo más extendido y define un flujo de evolución y entregas vía ramas de funcionalidad (feature) y estabilización (release) donde se resaltan las integraciones y la promoción del código.
Otra de las características que destaca es la identificación de una línea evolutiva (develop) de nuestro producto, y una línea estable de producción.
Suele ser altamente recomendable aplicar este modelo en repositorios con mucha carga funcional (antipatrón de las arquitecturas de microservicios), equipos de desarrollo grandes y/o en fases iniciales de un desarrollo.
Con la automatización necesaria de CI/CD, se adaptan muy bien a metodologías ágiles y entregas de funcionalidad frecuentes, sobre todo en los que se aplique Scrum, ya que facilita bastante la entrega de historias de usuario mediante features y los periodos de aceptación y review en ramas releases.
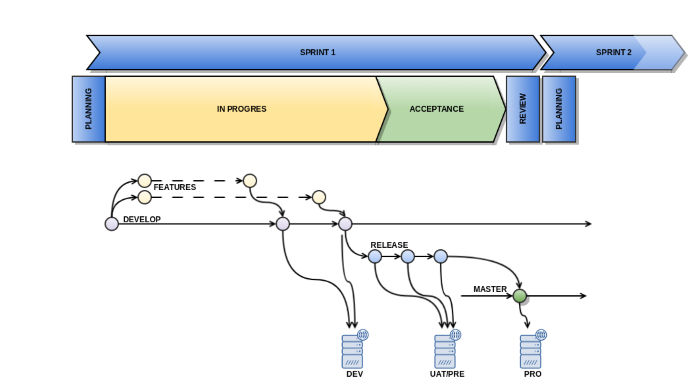
GitHub Flow
La característica que más destaca es la propia definición del modelo: Entregar cada funcionalidad directamente en producción.
Inicialmente, parece obvio que simplificar puede parecer la opción más correcta de organizar el repositorio. Ofrece ciclos de entrega más ágiles que cualquier otro modelo. Pero, en realidad, nada es tan simple como pueda parecer: usar un modelo tan agresivo exige disponer de una alta confianza en el propio código; y la única forma de disponer de esta confianza es con métricas y pruebas continuas de que todo funciona correctamente.
Aunque en cualquier modelo se debería exigir que el código tenga un mínimo de calidad, en este caso, al integrar el código en la propia rama de producción, se vuelve imprescindible disponer de una gran cobertura de pruebas unitarias, funcionales y de regresión.
Otra propiedad que debería de incluir el código es la de activación de funcionalidades por configuración, que permita desactivarlas si se ve afectadas por una de las entregas continuas que se realicen.
También es importante un mecanismo de despliegue que nos permita capacitar y ejecutar entornos previos simultáneos y paralelos donde podamos validar cada funcionalidad por separado.
Este modelo se adapta bastante bien a metodologías tipo Kanban, ya que te permite entregar cada historia de usuario según se va completando, y es muy interesante en repositorios con orientación real de microservicios y con disgregación de funcionalidades.
El modelo de entregas y versiones se plantea de la siguiente manera:
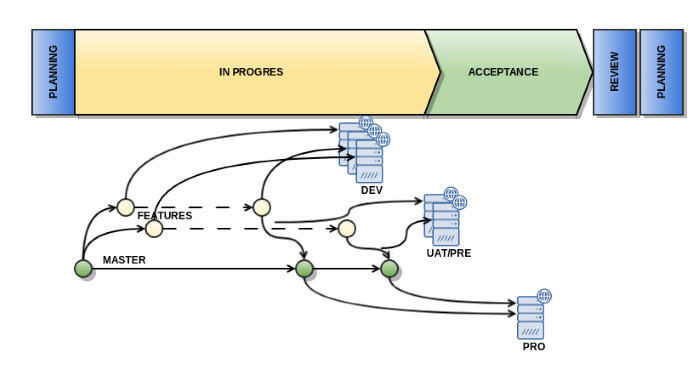
Integrar código mediante Pull Requests.
Independientemente del modelo que se haya decido aplicar, es muy importante definir la integración de código mediante una petición de Merge, nombrada Pull Request en algunos sistemas y Merge Request en otros.
De esta manera es posible aplicar conceptos de Code Review sobre el código a integrar y dar feedback en el propio repositorio del estado de la petición. Disponer de un sistema automatizado que analice estas peticiones de cambio, y sea capaz de ejecutar pipelines completos de CI/CD facilitará y agilizará cualquier revisión manual posterior.
Aplicar este tipo de técnicas no es nombrar a determinados miembros del equipo que sean los "policías" del proyecto, persiguiendo y analizando que todo código que se integre en las ramas comunes cumplan con unas premisas. Lo ideal es definir el número de revisores que validarán cada integración y los checkpoints necesarios; configurar el servidor para que solo permita aceptar el merge cuando se cumplan con estos requisitos; y que todos los miembros del propio equipo ejecuten el rol de Reviewer iterativamente.
Los objetivos deberían ser:
- Minimizar bugs introducidos por las propias integraciones.
- Dar una mayor visibilidad a cada miembro del equipo del conjunto del repositorio, por lo que se aumenta la reutilización de código y se minimiza el código duplicado.
- Colaborar a que se apliquen buenas prácticas en el desarrollo (impulsar las buenas prácticas de QA).
- Facilitar el mantenimiento posterior.
Conclusión
Usar Git como repositorio de código nos aporta mayores beneficios que usar cualquier otro tipo de repositorio. Además, aplicando un conjunto de buenas prácticas sobre el mismo, aumentaremos la calidad de nuestros productos software y facilitaremos bastante el día a día de los propios equipos.
Si a todo esto sumamos la automatización del ciclo de vida de desarrollo, incluyendo buenas prácticas con Integración, Entrega y Despliegue Continuo, se agilizaran las entregas de código y se minimiza el deseado TtM, que es el mayor problema que vivimos hoy en día en el mundo digital. Espero pronto poder escribir el siguiente post sobre estas buenas prácticas.
Para estar al día de próximas entregas síguenos en Twitter.
¡Hasta la próxima!