
Hablemos de Seguridad - Parte 2: Medidas de seguridad
Publicado por Thorsten Prumbs el
Seguimos con nuestro pequeño viaje por el mundo de la seguridad, tras el primer post de Introducción. En esta segunda edición vamos a presentar los conceptos de medidas de seguridad con el fin de establecer protocolos de seguridad y mitigar así posibles vectores de ataque (riesgos).

Separation of Concerns
En el mundo del software es buena práctica separar los intereses o Separation of Concerns. Veremos que los siguientes conceptos de seguridad tienen cada uno su correspondencia en componentes de Software, p.ej. Spring Security o productos específicos como Access Managers, Identity Managers, etc.
Identificación
La identificación es la respuesta a la pregunta:
- ¿Quién eres?
La respuesta a esta pregunta debe ser siempre un dato, o conjunto de datos, público, único e inequívoco.
Ejemplos de respuestas, es decir, formas de identificación:
- Nombre de usuario.
- Correo electrónico.
- Número de teléfono.
- D.N.I./N.I.E. (¡OJO! En España existen duplicados y por tanto no sirven para la identificación.)
- Datos biometricos (huellas dáctilares, etc.).
- Conjunto de datos:
- Nombre.
- Apellidos.
- Fecha y lugar de nacimiento.
- Dirección.
- Familiares, amigos, etc.
En España existe con el D.N.I./N.I.F. un identificador único (dejando aparte que hay duplicados por razones históricas) que permite identificar a una persona física de forma inequívoca, emitido por la Administración Pública.
En otros países como Reino Unido o Alemania, entre otros, la Administración Pública no tiene el derecho de asignar un identificador único a sus ciudadanos. Si se establece un identificador, p.ej. número de pasaporte, este identificador debe ser temporal, es decir, una vez caducado el pasaporte cambia el identificador.
Como conclusión nos debemos quedar con:
La identificación es un dato público e inequívoco. Nunca debe ser un secreto o algo privado.
Autenticación
La autenticación, o autentificación, es la respuesta a la orden:
- ¡Demuéstrame quién eres!
Se trata de verificar que una persona o un actor verdaderamente es quien pretende ser. Es decir, el paso previo a cualquier autenticación tiene que ser la identificación.
Se suele decir que existen tres formas de demostrar la identidad:
1.- Algo que tú sabes (y nadie más):
- Contraseña.
- PIN.
- Detalles personales de la vida privada, familiares, etc.
2.- Algo que tienes:
- Token físico:
- tarjeta SIM.
- tarjeta D.N.I.
- Token digital:
- Cookie.
- Código de transacción (Transaction Authentication Number (TAN)).
- Código de seguridad, p.ej. RSA SecurID.
3.- Algo que eres (o biometría):
- Huella dactilar.
- Reconocimiento de iris.
- Reconocimiento de cara.
- Geometría de mano.
- ADN (DNA).
Según el contexto y los riesgos asociados, se aplican múltiples factores de autenticación (Multi-factor authentication) para disminuir los riesgos de ataque. Los distintos factores se suelen separar en distintos canales independientes. Por ejemplo: una transferencia bancaria online con un código de seguridad (TAN) y otro token mandado por SMS.
En todos los casos, las medidas de autenticación pueden ser comprometidas, es decir, otra persona puede haber conseguido conocimiento (contraseña, PIN, etc.), posesión (tarjeta SIM, tarjeta RFID de acceso) o el sistema de biometría puede tener demasiados falsos positivos.
Por lo tanto, todas las medidas de autenticación deben ser sustituibles, por ejemplo:
- Establecer nueva contraseña o PIN.
- Pedir nueva emisión de tarjeta de crédito o SIM.
- Invalidar Cookie (logout).
- etc.
¿Qué NO sirve para la autenticación?
Sobre todo en la atención telefónica suele ocurrir que nos pidan nuestra fecha de nacimiento para validar nuestra identidad (es decir: autenticar). Es teatro de seguridad y no sirve de nada porque la fecha de nacimiento se ha convertido en un dato público (copias de D.N.I., perfiles en redes sociales, etc.).
Una buena parte de técnicas de biometría no sirven para la autenticación porque se trata de propiedades que no podemos esconder o proteger siempre (no llevamos siempre guantes o gafas de sol) y - mucho más importante - no se pueden sustituir muchas veces (sólo tenemos 10 dedos, dos ojos, dos manos, etc.).
La mayoría de las técnicas de biometría se deben considerar como comprometidas:
- ¿Cómo copiar huellas dactilares?
- 26/10/2004: How to fake fingerprints?
- 31/03/2005: Malaysia car thieves steal finger
- 21/09/2013: Chaos Computer Club breaks Apple TouchID
- 01/10/2013: hacking iphone 5S touchID
- 29/12/2014: Politician's fingerprint 'cloned from photos' by hacker
- ¿Cómo falsificar un iris?
- 23/05/2017: Hacking the Samsung Galaxy S8 Irisscanner
Sistemas biométricos sin mecanismos de detección de fraude no sirven en ningún caso para la autenticación. En muchos casos hay que complementar los sistemas biometricos con medidas organizativas.
A pesar de todos los ataques y mejoras de los sistemas de biometría, el problema es el mismo. Nos apuntamos:
Datos públicamente expuestos o no sustituibles, sirven para la identificación, pero no para la autenticación.
¿Y qué pasa con sellos de seguridad?
Existe otro concepto de autenticación pasiva que se utiliza para poner en evidencia cualquier manipulación. Estamos hablando de tamper evidence y tamper resistance.
Se habla de tamper evidence cuando se utilizan sellos de seguridad o un diseño específico para hacer visible cualquier manipulación o por lo menos la mayor parte de ellas. Lo conocemos de embalajes de productos físicos y en el mundo digital suele estar integrado en los protocolos criptográficos.
Por ejemplo, los paquetes de actualización de sistemas operativos (Linux, Windows, Android, etc.) están firmados digitalmente (Digital Signature) para que el receptor pueda autenticar el paquete de software. Adicionalmente, la firma asegura también la integridad del dato (que no haya sido alterado en el camino) y el no repudio (que el emisor no pueda negar que lo haya encriptado).
Si sólo queremos conseguir la evidencia de un cambio en el mundo digital, se suelen utilizar funciones hash criptográficas (Cryptographic hash function). Una función hash es un algoritmo que convierte el mismo input siempre en el mismo output (función unidireccional) y que transforma un pequeño cambio en el input en un cambio muy grande en el output (efecto avalancha).
Existen algoritmos de hash que ya se consideran rotos (MD5) porque se han demostrado ataques viables para provocar colisiones (distintos inputs se convierten en el mismo output).
Las funciones hash son la base inprescindible de prácticamente todos los protocoles de seguridad. Pero de los protocolos de seguridad hablaremos en la siguiente entrega de esta serie.
En este momento nos quedamos con:
Las funciones hash son cruciales para la seguridad digital, requieren un proceso de revisión muy largo y pueden estar expuestas a ataques.
Para el interesado dejo algunos enlaces muy interesantes:
- Cryptographic hash function
- Secure Hash Algorithms
- SHA-3 Project
- SHA-3 Standardization
- Cryptographic Key Length Recommendation
Autorización
La autorización debe responder a la pregunta:
- ¿Puede el Actor A ejecutar la acción X sobre el recurso R, estando en el contexto C?
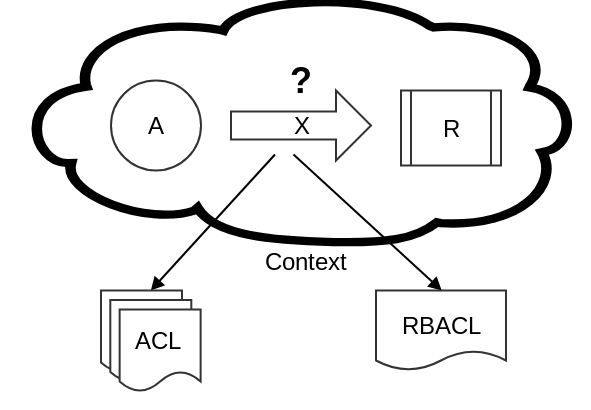
La autorización es la medida de seguridad más conocida, por ejemplo como protección de acceso.
Un actor puede ser una persona, una pieza de software o incluso una función de una aplicación. El recurso puede ser un objeto de cualquier tipo o simplemente un conjunto de datos. Lo importante es que la acción realice un posible cambio sobre el recurso o de acceso al mismo, en nombre del actor.
Toda la acción se realiza dentro de un contexto que podemos considerar como meta-datos de la decisión de autorización. El contexto contiene datos que ayudan al sistema de autorización para autorizar o no la acción sobre el recurso por parte del actor.
Por ejemplo, una persona A accede desde un dispositivo móvil vía Internet a un recurso R en un horario no habitual y quiere ejecutar la acción X que no debe ser ejecutada en estas circunstancias.
A nivel de usabilidad de interfaces de usuario, se suelen esconder o no pintar aquellas acciones a las cuales el usuario no tenga acceso en el contexto actual. Sin embargo, no se debe confundir la personalización con la autorización ("como el usuario no debe acceder, no le pintamos el enlace"). Si invocamos a una acción protegida, el sistema nos debe dar un error de "no autorizado" (p.ej. 401 Unauthorized). Si únicamente no pintamos la acción, el usuario puede llegar a conocer la acción y ejecutarla.
En el mundo del software, la autorización se considera un Cross-cutting concern. Es decir, no se puede implementar como un filtro ya que es una funcionalidad omnipresente en el sistema, también conocido como servicio horizontal o aspecto.
La implementación de dicha decisión de autorización se basa siempre en una identificación y autenticación anterior para poder decidir. Obviamente no sería mantenible si acoplamos identificadores de usuarios a permisos de autorización. Por lo tanto, los sistemas de autorización suelen externalizar el mapeo entre identificadores de actores y sus permisos.
Dicha externalización se puede realizar mediante Access Control Lists (ACL), conocido del mundo de los sistemas de ficheros y sistemas operativos. Sin embargo, cuando haya cambios, incluso por contexto, de los permisos, tenemos un problema para actualizarlas si son muchos usuarios y muchos objetos distribuidos. En este casos se suele trabajar con grupos de usuarios y roles, mapeando grupos de usuarios a roles e implementando los permisos correspondientes a cada rol. Este mapeo de roles a usuarios de llama Role-based access control.
Con esta pequeña introducción a la autorización podemos entender mucho mejor las implementaciones de autorización del mundo de desarrollo, p.ej. Access-Control (Authorization) in Spring Security.
En este caso nos quedamos con:
Autorización requiere una identificación fiable del actor, es decir se requiere siempre una autenticación antes de autorizar. La autorización basada en roles escala mejor que simples listas de control de acceso.
Auditoría
El objetivo de la auditoría es dejar huellas o trazas de todas las acciones y accesos realizados en un sistema para facilitar la reacción después del hecho.
Es decir, las trazas de auditoría (audit trail) facilitan la revisión de acciones y digital forensics. Existen ámbitos de negocio que tienen por su naturaleza una fuerte necesidad de auditoría, por ejemplo: banca, contabilidad, gestión del cambio, etc.
Como posibles implementaciones conocemos:
- Trazas de acciones (fichero, BBDD, mensajes, etc.) en almacenamiento WORM.
- Tamper-evidence (sin atribución directa).
Como parte del audit trail (conjunto de datos de auditoría) se suelen utilizar:
- Identificador del actor, p.ej. uid, número de tarjeta, etc.
- Token de acción, p.ej. UUID como Transaction ID.
- Datos identificativos del objeto de la acción, p.ej. números de cuentas, valor transaccional, etc.
- Meta-datos del contexto, p.ej. hora, lugar, dispositivo, etc.
En algunos casos la auditoría es imprescindible para la autenticación. Un ejemplo es el sistema de cobros de tarjetas de crédito en modo offline. En estos casos, el banco o la empresa de la tarjeta de crédito autentica la transacción después del hecho de la compra y una vez consolidadas las transacciones, queriendo decir también autorizadas, se cobra al cliente al final del mes.
Por ahora, de la auditoría nos quedamos con:
La auditoría es importante siempre después del hecho de la acción o transacción.
Con actores anónimos (no autenticados) no hay auditoría que valga para la atribución.
Privacidad
La privacidad es un término muy subjetivo y personal. De forma resumida, la privacidad es la protección de datos personales y privados. Sin embargo, lo que es personal y privado depende de cada persona (física o jurídica) y su contexto cultural.
Las legislaciones al respecto son muy diferentes en distintos países, p.ej. Europa vs. EEUU. En Alemania, por ejemplo, la protección de datos personales tiene un muy alto nivel de protección hasta el punto que un dato personal obtenido por una entidad sin el consentimiento explícito o OPT-IN (en España es implícito o OPT-OUT) del afectado se considera un delito con el consecuente derecho de indemnización y corrección o borrado del dato. Es decir, el afectado no deja de ser el propietario del dato personal.
En EEUU es muy diferente y de forma simplificada se podría decir: "quien recopila el dato personal, se convierte en el propietario del dato". El único derecho que mantiene el afectado es el de la corrección.
Esta diferencia legal es la razón por la cual existen muchos problemas legales de empresas de EEUU trabajando con datos de personas de la Unión Europea (UE). Durante muchos años existía un "acuerdo" muy flexible entre EEUU y la UE llamado Safe Harbour hasta que el Tribunal de Justicia de la Unión Europea lo invalidó en octubre 2015 (U.S.-EU & U.S.-Swiss Safe Harbor Frameworks). Para subsanar este autentico vacío legal se puso en marcha el Privacy Shield. Sin embargo, la Comisión Europea considera dicho acuerdo como insuficiente para garantizar los derechos de los ciudadanos de la UE (http://eur-lex.europa.eu/legal-content/ES/TXT/?uri=CELEX:32016D1250).
Con la entrada en vigor del Reglamento general de protección de datos (GDPR, General Data Protection Regulation) el 25 de mayo 2018, los derechos de privacidad de los ciudadanos de la UE se verán fortalecidos y está por ver de qué manera se podrá exigir por parte de las empresas de EEUU el cumplimiento del reglamento (GDPR), si procesan datos personales de ciudadanos de la UE.
Para los interesados en la GDPR recomiendo:
- EU General Data Protection Regulation (GDPR)
- GDPR Key Changes
- Directiva 95/46/CE
- Democracy: Im Rausch der Daten (2015) - IMDb
Y a nivel técnico, ¿qué hacemos?
Vemos que el concepto de la privacidad es sobre todo un tema personal, legal y político. A nivel técnico se intentan dar soluciones a estos requisitos legales y de ética empresarial.
Las soluciones técnicas actuales de privacidad rodean los conceptos de Gobierno del dato, la Seguridad del dato, tanto almacenado como en tránsito.
Según los requisitos legales y operativos, los almacenes de datos personales (es decir, BBDD, sistemas de ficheros, etc.) pueden ser encriptados y desencriptados por la aplicación cliente del almacén. De esta manera se excluyen los administradores y operadores de los sistemas de almacenamiento del dominio de confianza y se elimina un vector de ataque para brechas de datos.
Si se trata de transferir datos personales sobre lineas de comunicación fuera del dominio de confianza, se suele encriptar el canal de comunicación (p.ej. TLS, SSH, etc.) e incluso de forma adicional datos de alta sensibilidad dentro del payload (p.ej. enfermedades de un cliente dentro del XML de un WebService con AES) para evitar la fuga de datos en proxies o gateways.
Respecto al ámbito del Gobierno del dato existen productos comerciales con la promesa de hacer cumplir con la legislación vigente. En muchos casos son productos horizontales de virtualización del dato o incluso de bases de datos para conseguir así el control sobre quién o qué puede cambiar qué tipo de dato.
Hay que tener en cuenta que dicho enfoque va en contra de la orientación a productos software, Domain Driven Design y arquitecturas de micro-servicios. En estas arquitecturas, el Gobierno del dato se convierte en requisito funcional de cada dominio, pero esto ya se sale del tema de seguridad ;-)
En el caso de la Privacidad nos quedamos con:
La privacidad ha ganado importancia en los últimos años y tiene que ver con el Gobierno del dato y Domain Driven Design junto con el respeto al marco legal de datos personales.
Disponibilidad
De entrada la disponibilidad es la continuidad de un sistema durante un periodo de tiempo y se suele calcular como un pocentaje de la disponibilidad p.ej. de un servicio sobre el tiempo total, p.ej. un año. Es decir, una disponibilidad de 99,99% significa tener que asumir o mitigar una pérdida de servicio durante más o menos 52 minutos al año.
En un sistema grande, p.ej. sistema de banca online, no hablamos de un único sistema, sino de un conjunto muy grande de distintos sistemas como redes, almacenamientos y aplicaciones, sin entrar más en detalle. Todos los sistemas suelen tener un alto nivel de acoplamiento entre ellos y por lo tanto aplica "a chain is no stronger than its weakest link", es decir, el sub-sistema con el menor nivel de disponibilidad se impone a nivel global.
De forma simplificada se puede decir que la disponibilidad es la eliminación del único punto de fallo (SPOF). Pero en el contexto de la seguridad digital y sistemas distribuidos, la disponibilidad se convierte en algo más amplio relacionado con la fiabilidad y escalabilidad de un sistema.
Existen estrategias para aumentar la disponibilidad a distintos niveles:
- Infraestructura:
- Eliminación SPOF con la ayuda de balanceo y fail-over (active/active o active/passive).
- Uso de un Content Delivery Network (CDN).
- Arquitectura de soluciones:
- Separación de sistemas online y offline/batch.
- Cambios funcionales para limitar la carga y evitar avalanchas (waiting room, sync vs. async).
- Incorporar limitaciones de computación distribuida en el modelo de negocio (CAP Theorem), ACID vs. BASE, PACELC theorem).
Una vez que ya no existen SPOF a nivel infrestructura, la disponibilidad de un servicio se puede reducir al tiempo de respuesta por debajo de un úmbral máximo con un nivel de carga o concurrencia máximo. El razonamiento detrás es que un sistema que tarda más en responder lo que un cliente está dispuesto a esperar, se considera no disponible aunque el sistema hubiera podido haber respondido rápidamente un poco más tarde. Desde este punto de vista, la disponibilidad se convierte en un tema de rendimiento y de escalabilidad. Esto convierte los ataques distribuidos de denegación de servicio (DDoS attack) en uno de los mayores problemas de la disponibilidad.
¿Y qué tiene que ver con la seguridad?
La disponibilidad se considera un concern o necesidad de seguridad porque un sistema de mitigación de riesgos de seguridad que no está disponible, bien hace imposible el negocio o incluso la vida, o bien deja expuesto un asset a más ataques.
Esto aplica en el mundo físico, p.ej. una valla oxidada con agujeros, y mucho más en el mundo digital. Por un lado aplica por la complejidad de sistemas distribuidos para satisfacer la demanda y por el otro lado aplica por el muy alto nivel de dependencia de la vida humana de servicios digitales o en general de software, por ejemplo:
- Comunicaciones:
- Internet, telefonía, televisión, radio, satélite...
- Transporte:
- Coches, autobuses, trenes, aviones...
- Energía
- Producción y distribución de electricidad, gas natural, carburantes...
- Sanidad:
- aparatos médicos de monitorización, análisis...
- Alimentación:
- producción industrial y distribución de alimentos, agua...
- Y mucho otros...
Todos estos ámbitos y muchos más dependen directamente o indirectamente de la disponibilidad y el funcionamiento de sistemas de software. Si ahora recordamos que la inmensa mayoría del software empleado en dichos sistemas es propietario, incluso con patentes, sin auditar y sin actualizaciones recientes, nos debería sorprender que no ocurran más incidencias como el famoso ataque WannaCry.
A raíz de un lento proceso de concienciación de la sociedad, se empiezan a establecer regularizaciones legales para aquellos que ofrecen servicios de infraestructura crítica. Cuando los sistemas críticos dependen de Internet es especialmente problemático porque no existe un marco legal internacional a pesar de que Internet no conoce fronteras.
En el ámbito español el Centro Nacional de Protección de Infraestructuras y Ciberseguridad (CNPIC) recoge la legislación aplicable según el sector: http://www.cnpic.es/Legislacion_Aplicable/index.html
Hablando de disponibilidad nos quedamos con:
Disponibilidad no es solo un tema de eliminación del único punto de fallo.
Es un tema de seguridad por nuestra dependencia vital de los sistemas de software.
En el próximo episodio de esta serie descubriremos cómo podemos mitigar riesgos y proteger activos utilizando protocolos de seguridad.
¡Síguenos en Twitter para estar al día de las próximas entregas!