
Monitorizando Filesystems AWS con Amazon CloudWatch
Publicado por Sergio Lecuona el
Ya hablemos de plataformas On-Premise o de plataformas Cloud siempre deberíamos disponer de una herramienta de monitorización que nos permita conocer el estado de los componentes que la forman. En este caso, vamos a explicar cómo utilizar Amazon CloudWatch para controlar el estado de ocupación de nuestros Filesystems, y cómo crear Alarmas para enterarnos por correo de cuándo llegamos a un umbral límite que nos permita actuar antes de ser testigos de un desastre mayor.

Por defecto, Amazon CloudWatch nos permite añadir métricas básicas de nuestras instancias EC2, como el tráfico de entrada y salida o el uso de CPU.
Sin embargo, no es capaz de visualizar la ocupación al nivel de FS que nosotros necesitamos. Así que en este caso hará falta crear métricas personalizadas.
El primer paso es instalar el AWS CLI en nuestra instancia (en caso de no tenerlo ya):
#apt-get install awscli
Una vez instalado vamos a crear el script en el que generaremos las métricas, que en nuestro caso es /usr/local/bin/cloudwatch_metrics.sh:
#cd /usr/local/bin
#vi cloudwatch_metrics.sh
El código de nuestro script es bastante simple, pero es fácilmente extensible para añadir las métricas que consideremos necesarias, ya sean a nivel de recursos de la máquina como de los procesos que estemos ejecutando en ella:
#!/bin/bash
export INSTANCE_ID=$(curl -s http://169.254.169.254/latest/meta-data/instance-id/)
export NAMESPACE=testingNameSpace
export REGION=$(curl -s http://169.254.169.254/latest/dynamic/instance-identity/document|grep region|awk -F\" '{print $4}i')
FILE_FS="/tmp/clw_temp.txt"
df -h |grep -v Filesystem > $FILE_FS
while read p; do
PORCENTAJE=$(echo $p | cut -d " " -f5)
FS=$(echo $p | cut -d " " -f6)
PORCENTAJE=$(echo $PORCENTAJE | cut -d "%" -f1)
aws cloudwatch put-metric-data --metric-name FS_$FS --namespace "$NAMESPACE" --value $PORCENTAJE --region $REGION
done < $FILE_FS
Aunque es bastante sencillo y corto, vamos a diseccionar las tres partes que lo componen:
En primer lugar, tendremos que definir los siguientes valores:
- Region: Región geográfica a la que pertenece nuestra instancia.
- NameSpace: Nombre que daremos al espacio de CloudWatch en el que alojaremos las métricas.
- InstanceId: Identificador de la instancia que estamos monitorizando.
Para obtener los valores de instancia y región hacemos uso de las llamadas a la IP 169.254.169.254, mecanismo por el cual AWS nos devuelve los metadatos de la instancia que hace la petición.
export INSTANCE_ID=$(curl -s http://169.254.169.254/latest/meta-data/instance-id/)
export NAMESPACE=testingNameSpace
export REGION=$(curl -s http://169.254.169.254/latest/dynamic/instance-identity/document|grep region|awk -F\" '{print $4}i')
En segundo lugar obtenemos el listado de Filesystems existentes y lo volcamos a un fichero temporal eliminando la primera línea con las cabeceras:
FILE_FS="/tmp/clw_temp.txt"
df -h |grep -v Filesystem > $FILE_FS
Por último, recorremos el fichero creado parseando cada una de las líneas para obtener los valores que queremos y pasárselos como parámetro al comando de AWS CloudWatch:
while read p; do
PORCENTAJE=$(echo $p | cut -d " " -f5)
FS=$(echo $p | cut -d " " -f6)
PORCENTAJE=$(echo $PORCENTAJE | cut -d "%" -f1)
aws cloudwatch put-metric-data --metric-name FS_$FS --namespace "$NAMESPACE" --value $PORCENTAJE --region $REGION
done < $FILE_FS
Una vez ejecutado, volvemos a nuestro Dashboard en CloudWatch y tratamos de añadir una nueva métrica. Veremos que ya existe el NameSpace que hemos creado:
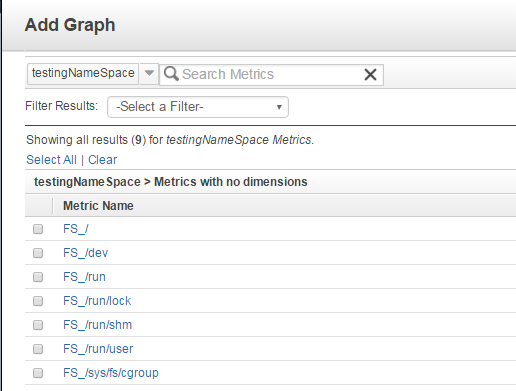
Y tras seleccionarlo veremos el listado de métricas para cada uno de los filesystems:
Seleccionamos todos y añadimos la gráfica nueva. Por desgracia, veremos que solo tenemos un dato puntual:
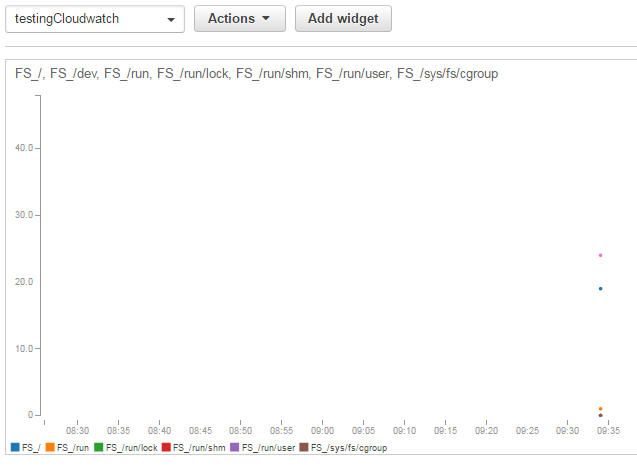
Por sí solo esto no nos vale porque queremos tener una monitorización continua del estado, así que volvemos a la instancia y añadimos una ejecución periódica del script en el fichero /etc/crontab. (Lo planificaremos para ejecutarse una vez por minuto):
# cat /etc/crontab
# /etc/crontab: system-wide crontab
# Unlike any other crontab you don't have to run the `crontab'
# command to install the new version when you edit this file
# and files in /etc/cron.d. These files also have username fields,
# that none of the other crontabs do.
SHELL=/bin/sh
PATH=/usr/local/sbin:/usr/local/bin:/sbin:/bin:/usr/sbin:/usr/bin
# m h dom mon dow user command
17 * * * * root cd / && run-parts --report /etc/cron.hourly
25 6 * * * root test -x /usr/sbin/anacron || ( cd / && run-parts --report /etc/cron.daily )
47 6 * * 7 root test -x /usr/sbin/anacron || ( cd / && run-parts --report /etc/cron.weekly )
52 6 1 * * root test -x /usr/sbin/anacron || ( cd / && run-parts --report /etc/cron.monthly )
* * * * * root /usr/local/bin/cloudwatch_metrics.sh
Como no queremos estar mirando continuamente las gráficas, sino recibir una alerta por correo en caso de superar un umbral de ocupación, vamos a generar una alarma de CloudWatch para (en este caso) el Filesystem /:
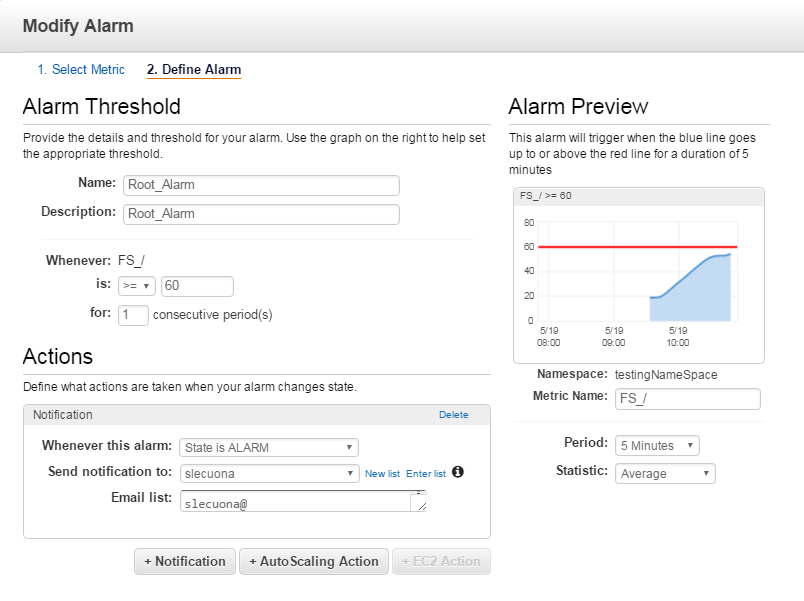
En este caso hemos creado la alarma para que se ejecute periódicamente cada 5 minutos, enviando un email a mi dirección de correo en caso de superar el 60% de ocupación. Como estamos en una instancia de prueba vamos a simular la ocupación del disco para verificar nuestra alarma. Para ello lanzamos 4 procesos para generar automáticamente ficheros dummy test.txt con un tamaño de 2GB:
#dd if=/dev/zero of=test.txt bs=1 count=2GB &
#dd if=/dev/zero of=test1.txt bs=1 count=2GB &
#dd if=/dev/zero of=test3.txt bs=1 count=2GB &
#dd if=/dev/zero of=test4.txt bs=1 count=2GB &
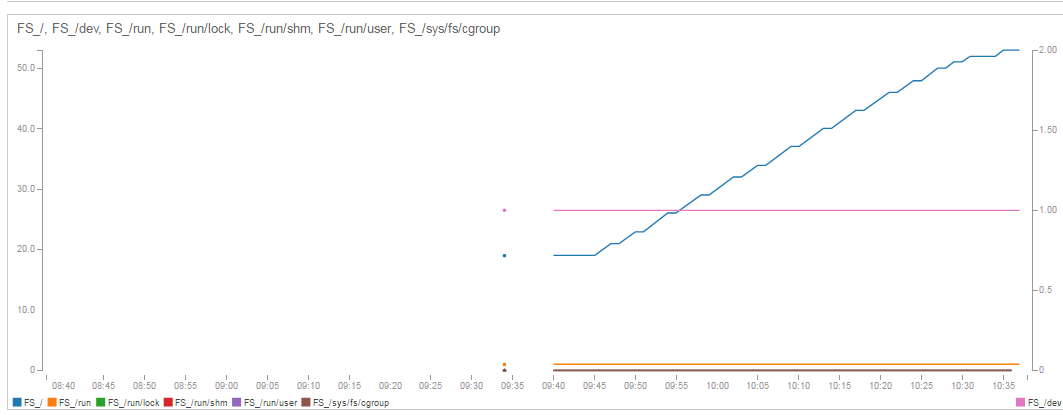
Si volvemos a la métrica veremos cómo la gráfica cobra vida, y la línea del Filesystem raíz comienza a indicar la ocupación que estamos lanzando:
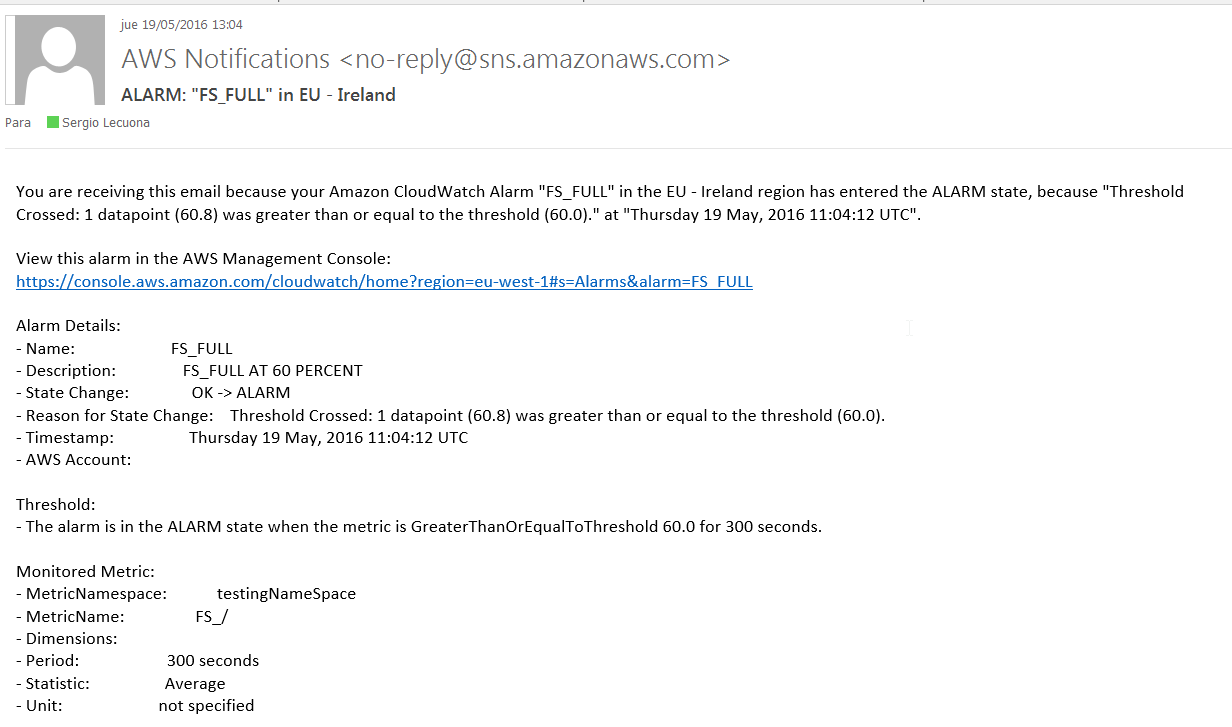
Esperamos a que el FS se llene y comprobamos que recibimos correctamente la alerta en nuestro buzón:
Espero que os sea útil y ayude a evitar algún dolor de cabeza :)