
Observabilidad en entornos cloud usando OpenTelemetry (Parte 1)
Publicado por Manuel García de Vinuesa Gómez el
Introducción
El concepto de observabilidad no es algo nuevo o algo relacionado con los sistemas distribuidos tan comunes en la era cloud. Desde los inicios del desarrollo del software ha sido fundamental conocer si los sistemas que manejamos están comportándose como se les espera y el rendimiento de los mismos.

Dicho esto, seguramente os suenen herramientas relacionadas con las métricas que actualmente están en producción en vuestros proyectos, como pueden ser Grafana y Prometheus, otras relacionadas con la gestión de logs, como el stack ELK, Graylog o Loki, o incluso si trabajas con sistemas distribuidos más o menos complejos es básico disponer de herramientas como Jaeger, Zipkin o similar para gestionar las trazas del mismo.
A esta lista se podrían seguir añadiendo herramientas, tanto específicas como más “cross” como Datadog, Dynatrace o Splunk que nos ofrecen una gestión end-to-end de la observabilidad para nuestros sistemas.
En este artículo vamos a dar a conocer y evaluar un proyecto de la CNCF (Cloud Native Computing Foundation) que nace de la unión de dos iniciativas como eran OpenCensus y OpenTracing y que pretende convertirse en la solución de facto para la gestión de la observabilidad en entornos cloud dentro de las organizaciones.
¿Qué es la observabilidad?
Antes de empezar a conocer OpenTelemetry es fundamental conocer y tener unas nociones básicas de qué es la observabilidad. Para ello podríamos definirla como:
La capacidad de conocer el estado actual de un sistema a partir de los datos que genera, como los logs, las métricas y las trazas.
Estos tres conceptos se definen como los tres pilares de la observabilidad.
Haciendo una breve introducción a cada uno de ellos podríamos decir que:
- Un log es un registro inmutable, con una marca de tiempo, de un evento concreto que ocurrió durante la ejecución de un sistema o aplicación. Gracias a los logs podemos, entre otras cosas, conocer qué está ocurriendo en nuestro sistema de una manera descriptiva y funcional.

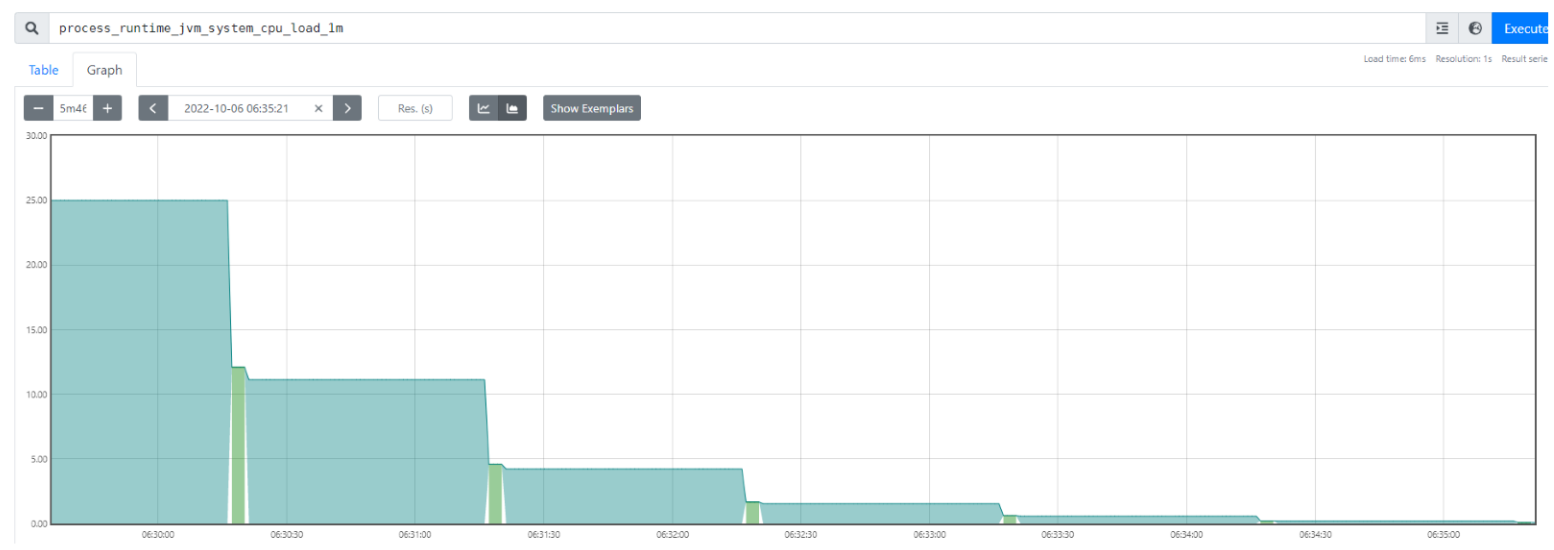
- Las métricas son representaciones numéricas de mediciones de nuestro sistema en un determinado intervalo de tiempo. Consumos de CPU y memoria, número de peticiones, tiempos de respuesta son algunos ejemplos de métricas que nos pueden ayudar a conocer y a predecir el comportamiento de nuestro sistema.
- Una traza es la relación de una serie de eventos o acciones que agrupa el end-to-end de una petición a través de un sistema distribuido. Es decir, en un sistema donde diferentes servicios toman parte, la traza nos va a permitir relacionar las acciones que han ocurrido en cada uno de ellos una vez que el usuario final ha ejecutado una acción.
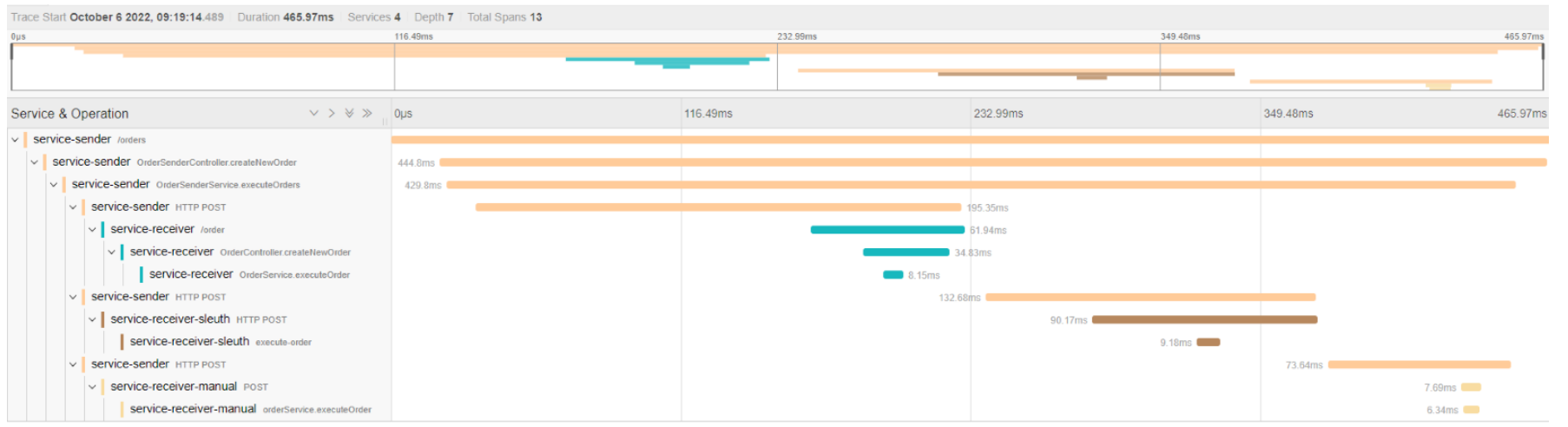
Sin entrar en excesivo detalle, pero por no omitir información que puede ser de utilidad a lo largo de este artículo, es importante conocer que una traza (end-to-end de una petición) está dividida en lo que se conoce como Spans, que no son ni más ni menos que los diferentes "bloques de ejecución" o unidades de trabajo que componen la traza.
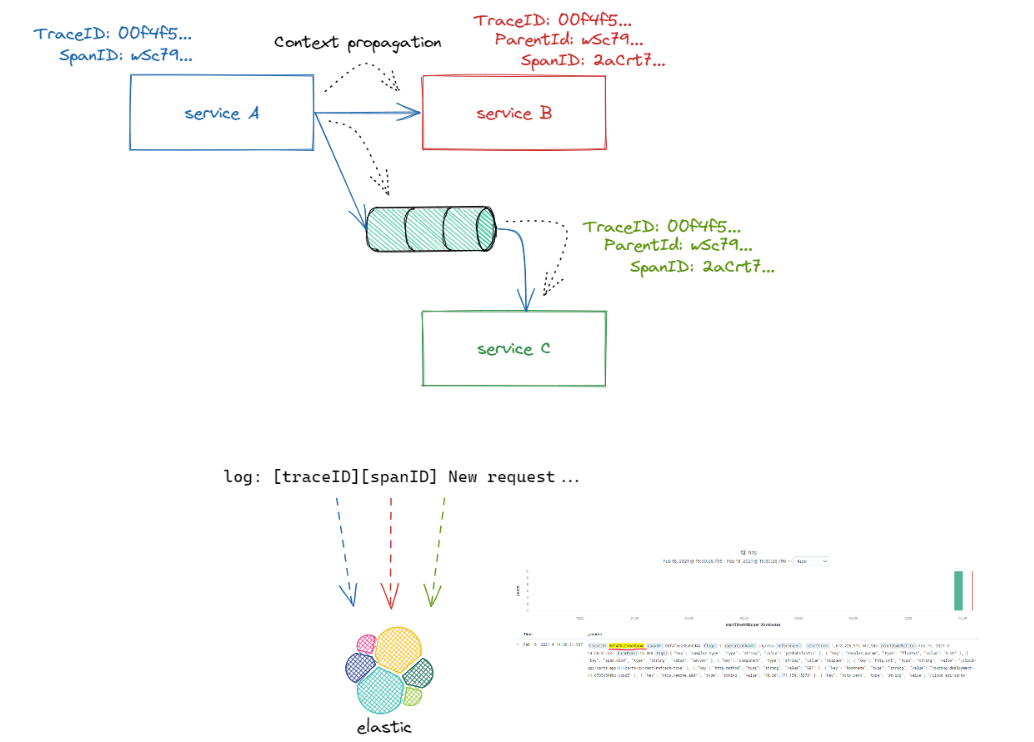
Aparte de los tres pilares, existe otro concepto fundamental que permite relacionar los diferentes actores de nuestro sistema e incluso con sistemas externos, la propagación de contexto. La propagación de contexto es la capacidad que van a tener nuestros servicios, sistemas y aplicaciones para poder progresar el contexto recibido (la información que nos va a permitir correlacionar eventos) hacia los distintos elementos del flujo y que nos ofrece la capacidad para relacionar las trazas, los logs y las métricas.
Diferentes herramientas para gestionar la observabilidad
Como se comenta en la introducción de este artículo, actualmente existen múltiples alternativas para manejar la observabilidad de un sistema, muchas de ellas sólo se enfocan en uno de los pilares y otras intentan ofrecer una visión más transversal.
A nivel de nuestros sistemas y aplicaciones puede resultar complicado saber por dónde comenzar o que herramientas elegir para implementar la observabilidad. Cada una de las herramientas necesitará una implementación diferente y los sistemas evolucionan a tal velocidad que la herramienta que ahora sirve puede que para otras aplicaciones o sistemas no se ajuste a las necesidades de negocio.
Además, el uso de distintas herramientas ha conllevado a la aparición de distintos estándares y formatos por lo que la interconexión entre sistemas externos puede generar sobresfuerzos para mantener la coherencia en la solución final.
¿Qué es OpenTelemetry?
OpenTelemetry (OTEL) es un proyecto liderado por la CNCF (Cloud Native Computing Foundation) y por tanto OpenSource, que pretende estandarizar a través de herramientas, API's y una completa SDK, como las aplicaciones y sistemas se instrumentan para manejar la observabilidad de los mismos. Es decir, estandarizar como los datos están siendo generados, recogidos y transmitidos a los diferentes sistemas de explotación de los mismos.
¿Qué no es OpenTelemetry?
Es importante añadir este punto antes de seguir escribiendo, OpenTelemetry no es un servicio o un backend para gestionar los datos generados como pueden ser Prometheus o Jaeger, no almacena o explota la información generada, la emite, la formatea y la estandariza, para que posteriormente otros sistemas, y ahora sí, como Prometheus o Jaeger puedan explotarla.
Componentes de OpenTelemetry
OpenTelemetry es un framework complejo, nace con la idea de dar soporte e integrarse a la mayoría de las soluciones actuales de la CNCF (Como por ejemplo Prometheus, Jaeger...), por tanto, ofrece distintos modos de comunicación, exportación, uso y despliegue en entornos productivos.
Además, aparte de ofrecer un core de producto, existen distintas extensiones que pueden añadirse a la solución final para dar soporte a los distintos sabores que existen actualmente en el mercado.
En este artículo iremos explicando paso a paso cada una de las piezas que componen este puzzle, poniendo foco en aquellas que entendemos son más interesantes y nos pueden aportar más valor a la hora de trabajar con OpenTelemetry.
Con el objetivo de entender el producto, primeramente, vamos a explicar una serie de conceptos que son clave para entender la solución final:
-
Signals (señales): Son los diferentes tipos de datos que OpenTelemetry soporta, en este caso actualmente trazas, métricas, logs y baggages. Esto último se refiere a cómo la información del contexto se propaga entre los distintos componentes (o spans).
-
Librerías de instrumentación: OpenTelemetry ofrece una serie de librerías que dan soporte a distintos lenguajes Estas librerías serán las encargadas de generar los datos de observabilidad a través de la API de OpenTelemetry.
Existen dos tipos de instrumentación, manual, donde los desarrolladores deberán implementar la solución en base a la SDK de OpenTelemetry, y automática, donde OpenTelemetry se encarga de instrumentar las diferentes librerías de nuestra aplicación para generar los datos de observabilidad.
Por ejemplo con Java, OpenTelemetry es capaz de auto-instrumentar las siguientes librerías de manera transparente.
-
OTLP: El protocolo de comunicación nativo definido en OpenTelemetry para transmitir información entre sus componentes.
-
Collector (colector): el colector ofrece la capacidad de recibir, procesar y exportar todos los datos de observabilidad de una manera estándar con el objetivo de que las aplicaciones e infraestructura no se acoplen con ningún vendor.
-
Pipelines: Definen el flujo que seguirá una señal, desde su emisión hasta su exportación.
Auto-Instrumentación con OpenTelemetry
Como ya se ha comentado, OpenTelemetry ofrece una serie de librerías que nos van a permitir instrumentar de manera manual toda la generación de señales. Usar instrumentación manual tiene los siguientes retos:
- La SDK es bastante amplia, con bastantes opciones y obtener la experiencia necesaria puede ser difícil.
- Ofrecer la suficiente información de manera manual puede ser tedioso, por ejemplo, en las métricas sería necesario implementar código por cada una de las métricas que quisiéramos exponer (CPU, Memoria...) Con la auto-instrumentación las principales métricas están ya incluidas.
- Para instrumentar de manera manual hay que conocer la convención semántica de OpenTelemetry. OpenTelemetry Specification
- Para cada lenguaje existe una SDK distinta, si estuviéramos en un ecosistema políglota (diferentes lenguajes en nuestros micros) deberíamos implementar la misma instrumentación en todos los lenguajes existentes.
Con el objetivo de no extendernos demasiado, en este artículo nos centraremos principalmente en el uso de la auto-instrumentación, en concreto implementaremos un ejemplo para aplicaciones generadas serán aplicaciones Java con Spring Boot, donde OpenTelemetry se integra perfectamente.
Aun así, si tienes curiosidad de como instrumentar OpenTelemetry de manera manual, a continuación te dejo una serie de enlaces que pueden serte de utilidad:
- Trace Semantic Conventions
- Instrumenting
- Instrumenting libraries
- Ejemplo de instrumentación manual de llamadas gRPC
Para auto-instrumentar, concretando en el ejemplo que veremos a continuación, bastará con usar un Java Agent específico con el que lanzar nuestra aplicación. Dicho agente es configurable a través de variables de entorno y nos permitirá indicar los backends destinos para cada una de las señales,
En el siguiente enlace podéis encontrar todas las opciones que ofrece este agente a la hora de configurarlo para usar OpenTelementry.
Ejemplo 1: Auto-instrumentar una aplicación Spring-Boot.
En el siguiente ejemplo vamos a crear una aplicación sencilla que mande las señales de tipo métricas a Prometheus y las trazas a Jaeger.
Si queréis ejecutar el ejemplo por vosotros mismos, necesitaréis lo siguiente:
- IDE de Desarrollo (Eclipse, IntellJ...)
- JDK 17
- Maven
- Docker y Docker Compose
Si queréis ejecutar la prueba y estáis usando Windows, podéis instalaros Docker en WSL (Windows Subsystem Linux).
El código de dicho ejemplo lo podéis encontrar aquí.
-
Creación de la aplicación basada en Spring Boot.
Con el objetivo de crear la aplicación inicial usaremos https://start.spring.io/, de esta manera crearemos una aplicación inicial con la que trabajar. En dependencias bastará con incluir spring-web para exponer nuestro servicio.
Es importante resaltar que en ningún momento se ha añadido ninguna dependencia de OpenTelemetry, Jaeger ni Prometheus en lo que sería el código aplicativo. Es decir, no estamos acoplados a este nivel a ninguna solución de observabilidad.
-
Dentro de la aplicación, crearemos el @RestController que expondrá un endpoint sencillo.
@RestController public class HelloController { @GetMapping(value = "/hello") public String sayHello() { return "Hello"; } } -
Creación del Dockerfile, donde definiremos como se construirá la imagen y añadiremos el agente java que nos permite la auto-instrumentación
FROM maven:3.8.3-openjdk-17 as builder COPY src /usr/src/app/src COPY pom.xml /usr/src/app RUN mvn -f /usr/src/app/pom.xml clean package FROM openjdk:17-jdk-slim COPY --from=builder /usr/src/app/target/auto-instrumentation-service-0.0.1-SNAPSHOT.jar /app.jar COPY otel/opentelemetry-javaagent.jar /opentelemetry-javaagent.jar ENTRYPOINT java -jar -javaagent:/opentelemetry-javaagent.jar app.jar -
Y por último definir el dichero de docker-compose para montar nuestro ecosistema local.
version: '3' services: auto-instrumentation-service: build: ./ environment: OTEL_SERVICE_NAME: "auto-instrumentation-service" OTEL_TRACES_EXPORTER: "jaeger" OTEL_EXPORTER_JAEGER_ENDPOINT: "http://jaeger:14250" OTEL_METRICS_EXPORTER: "prometheus" OTEL_EXPORTER_PROMETHEUS_PORT: 19090 ports: - "8080:8080" - "19090:19090" #Prometheus scrapping port depends_on: - jaeger - zipkin zipkin: image: openzipkin/zipkin:latest ports: - "9411:9411" jaeger: image: jaegertracing/all-in-one:latest ports: - "16686:16686" - "14268" - "14250:14250" prometheus: image: prom/prometheus:latest volumes: - ./prometheus.yml:/etc/prometheus/prometheus.yml ports: - "9090:9090" depends_on: - auto-instrumentation-service
En dicho fichero se está definiendo:
- La aplicación de ejemplo (auto-instrumentation-service) la cual expone el puerto 8080 (aplicativo) y el puerto 19090. Además, arranca con las variables de entorno que nos van a permitir configurar la auto-instrumentación. En concreto se están añadiendo:
- OTEL_SERVICE_NAME: Especifica el nombre de la aplicación dentro de OpenTelemetry.
- OTEL_TRACES_EXPORTER: Especifica donde van a ser exportadas las trazas de la aplicación. En concreto a Jaeger.
- OTEL_EXPORTER_JAEGER_ENDPOINT: La URL del backend de Jaeger, donde OpenTelemetry exportará las trazas.
- OTEL_METRICS_EXPORTER: Especifica donde van a ser exportadas las métricas. En concreto a Prometheus.
- OTEL_EXPORTER_PROMETHEUS_PORT: El puerto que se abrirá en esta aplicación para que prometheus haga scrapping de las métricas de la aplicación.En este caso dicho puerto es el 19090 y por eso se expone como puerto en el compose.
Todas las posibilidades de configuración se encuentran en el siguiente enlace.
-
Jaeger como backend de trazas. Con configuración básica.
-
Prometheus como backend de métricas. En este caso y como se ha explicado anteriormente, prometheus necesita definir su proceso de scrapping, para ello se define un fichero específico de configuración (prometheus.yml) donde se añade la siguiente información:
global: scrape_interval: 15s scrape_timeout: 10s evaluation_interval: 15s scrape_configs: - job_name: auto-instrumentation-service honor_timestamps: true scrape_interval: 15s scrape_timeout: 10s metrics_path: /metrics scheme: http static_configs: - targets: - auto-instrumentation-service:19090
Lo más importante en dicho fichero es el job que hará scrapping cada 15 segundos contra el servicio publicado.
-
Una vez definido todo, se procede a levantar el stack
docker-compose up -d --buildY comprobar que no hay ningún error
docker-compose ps docker-compose logs -
Con todo los servicios levantados de manera correcta, se pueden explorar los siguientes endpoints:
- Jaeger UI: http://localhost:16686/
- Prometheus UI: http://localhost:9090/
- Endpoint de métricas: http://localhost:19090/metrics
Una vez hecho esto, se puede ejecutar la siguiente petición contra nuestra aplicación:
curl --location --request GET 'http://localhost:8080/hello'
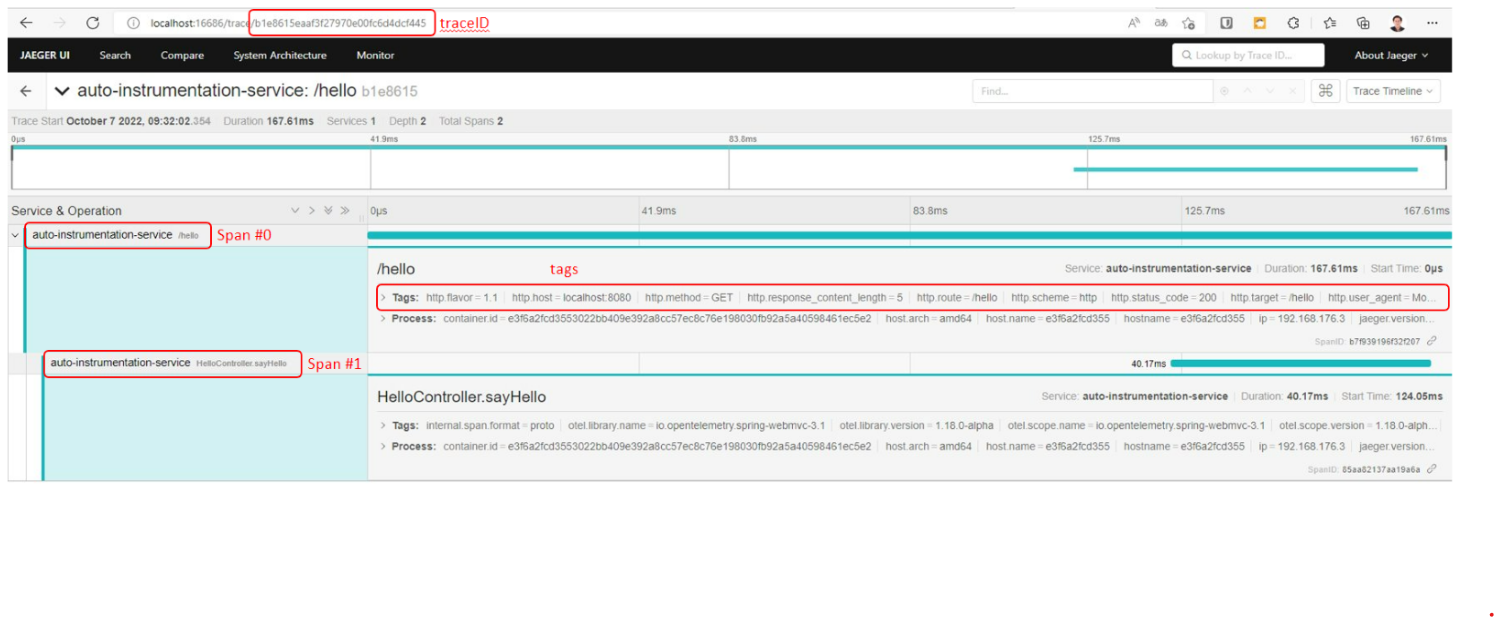
En Jaeger, el backend de trazas, podemos ver la siguiente información:
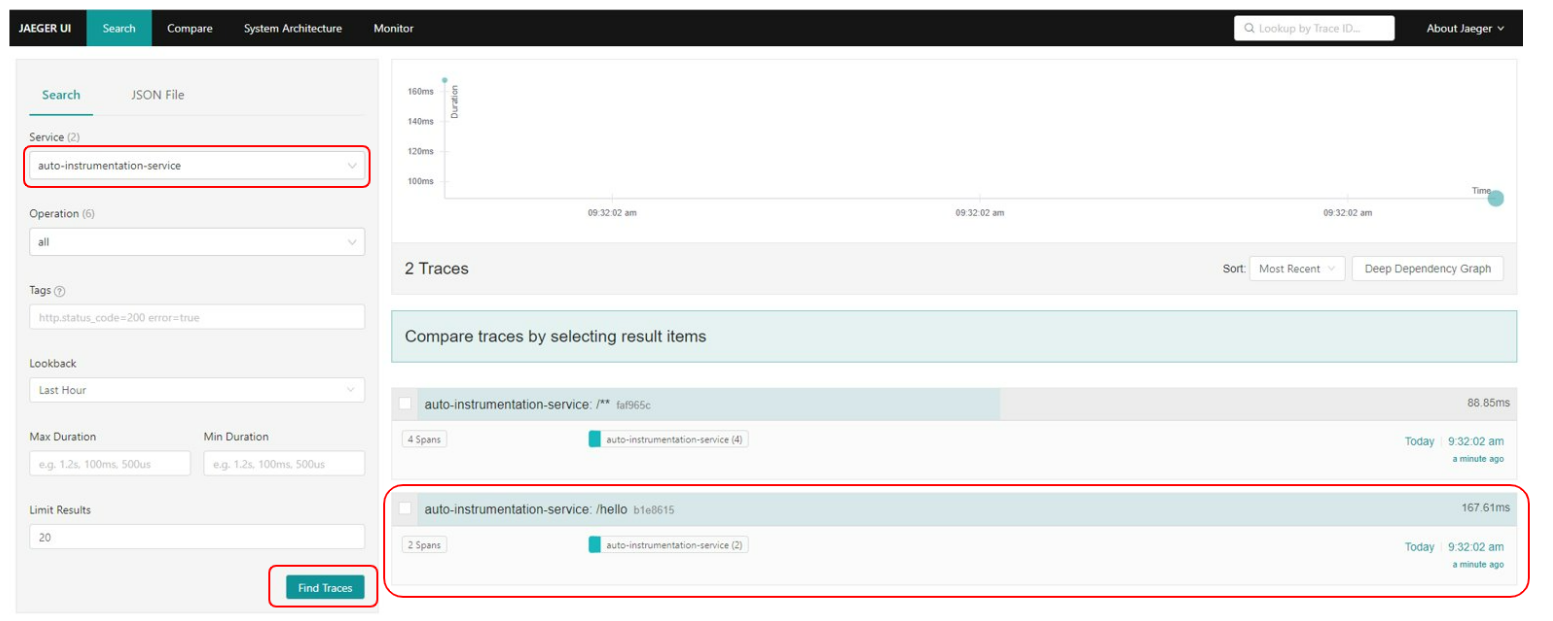
En el combo de servicios (service) se elige la aplicación y se pulsa el botón "Find Traces". Tras ello deberían aparecernos las diferentes peticiones contra el servicio.
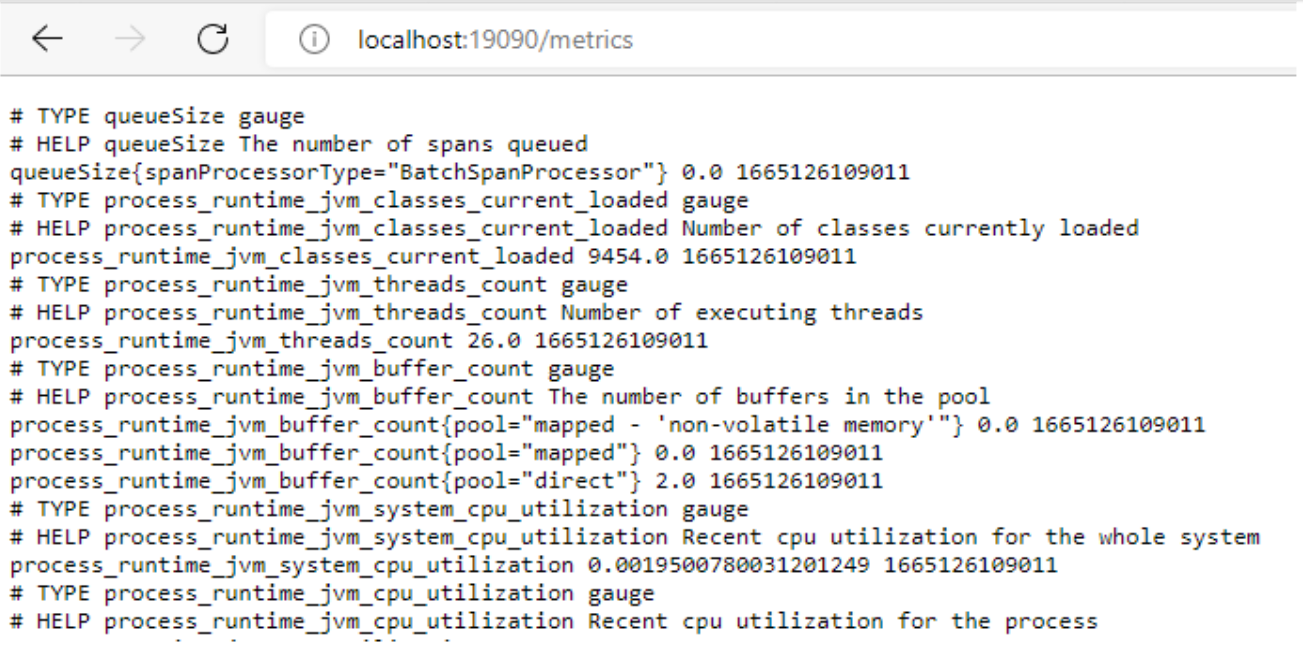
Para ver las métricas, tenemos dos opciones, una de ellas es ir al endpoint que expone OpenTelemetry sobre la aplicación para que prometheus recupere las métricas. Dicho endpoint se expone sobre el puerto 19090.
Lógicamente, esta información no es explotable, para ello prometheus la almacena y nos permite visualizarla. Si tuviéramos herramientas como Grafana podríamos crear dashboards mucho más completos con los que explotar dicha información. Accedemos a Prometheus y exploramos las métricas disponibles:

En este punto aparecerá un popup con las métricas generadas por la aplicación, dichas métricas están asociadas a la CPU, la memoria y las peticiones HTTP, por ejemplo:
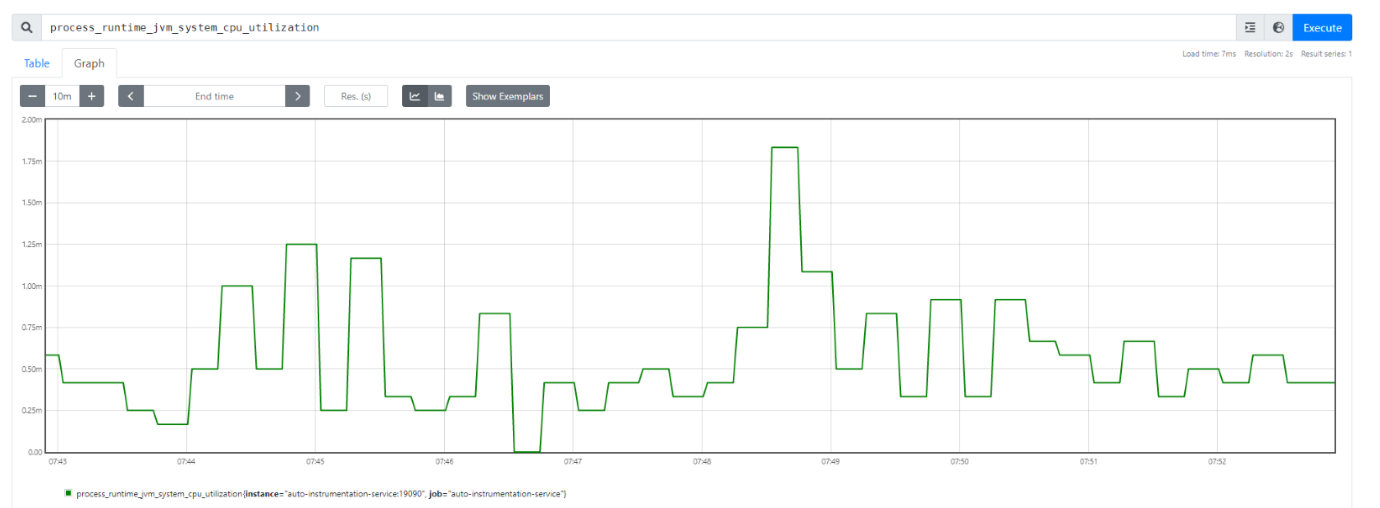
- Hasta este punto hemos explorado como, usando OpenTelemetry, podemos exportar las diferentes señales asociadas a la observabilidad a distintos backends que las exploten sin acoplar nuestro código a ninguna solución.
Ahora imaginemos, que a nivel corporativo en nuestra empresa han decidido sustituir Jaeger por otro backend de trazas, por ejemplo Zipkin.
En este caso, para evitar afectación a nuestros sistemas y para favorecer un escalado del despliegue de la solución, lo lógico sería mandar dichas trazas a ambos backends y una vez validada la solución terminar quitando Jaeger.
En cualquier otro escenario, sin usar OpenTelemetry, implicaría modificar nuestras aplicaciones, revisar posibles conflictos y crear nuevas versiones de las mismas. En cambio, usando OpenTelemetry esta situación se simplifica, ya que sólamente modificando la configuración del agente de auto-instrumentación, conseguimos el efecto deseado. Vamos a mostrar los pasos necesarios en nuestro ejercicio para conseguir cambiar Jaeger por Zipkin y que exista convivencia entre ellos.
-
En el docker-compose añadimos la nueva instancia de Zipkin.
zipkin: image: openzipkin/zipkin:latest ports: - "9411:9411" -
A su vez, en el mismo fichero, modificamos las variables de entorno de la aplicación asociadas a OpenTelemetry, informando de que las trazas serán enviadas tanto a Jaeger como a Zipkin e indicando el endpoint de este último.
OTEL_SERVICE_NAME: "auto-instrumentation-service" OTEL_TRACES_EXPORTER: "jaeger,zipkin" OTEL_EXPORTER_JAEGER_ENDPOINT: "http://jaeger:14250" OTEL_EXPORTER_ZIPKIN_ENDPOINT: "http://zipkin:9411/api/v2/spans"
-
Volvemos a arrancar el stack completo con
docker-compose up -
Visitamos la URL de Zipkin http://localhost:9411/zipkin/ y tras hacer alguna petición al servicio, localizamos la traza tanto en este backend como en Jaeger.
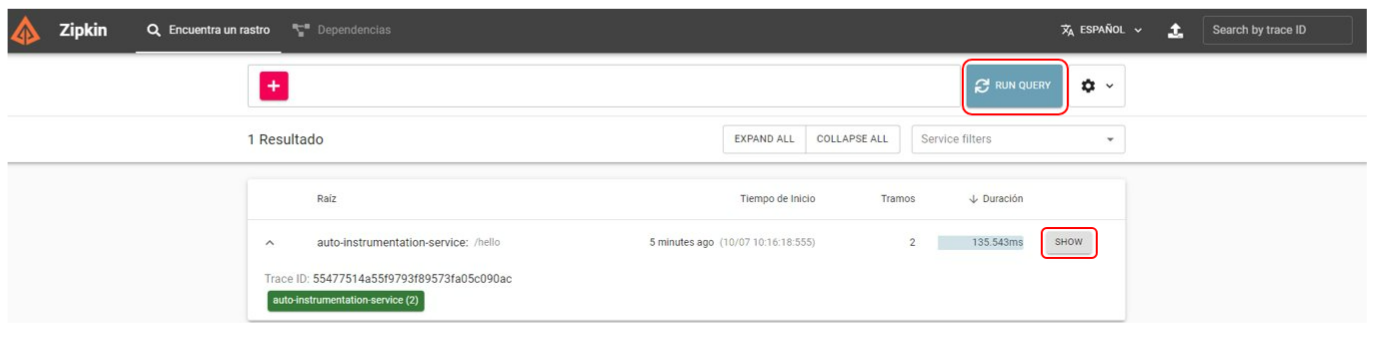
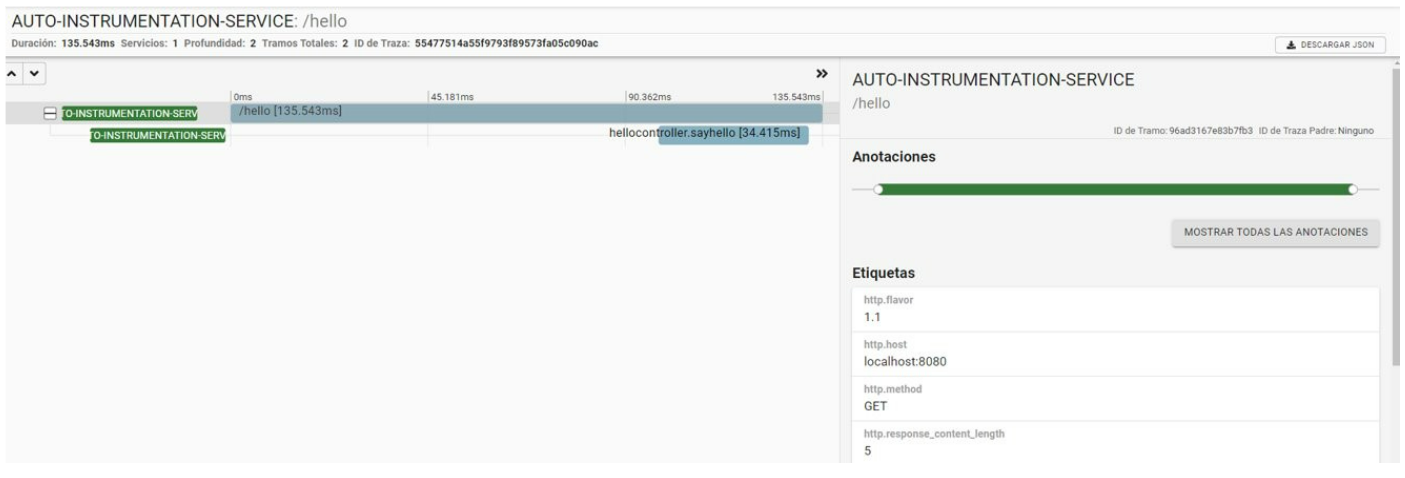
-
Ahora si, podríamos eliminar Jaeger y mantener Zipkin como backend de trazas distribuidas.
Conclusiones
En este artículo hemos podido entender que es OpenTelemetry y su principal misión en la estandarización e instrumentación de cómo se generan, emiten y exportan las diferentes señales asociadas con la observabilidad.
Una de las principales ventajas de esta iniciativa es la capacidad de abstracción y desacoplamiento, ya que permite a los equipos de desarrollo centrarse en el código de negocio.
A su vez, hemos visto como la migración entre distintos backends se torna muy sencilla, sin necesidad de modificaciones dentro de las aplicaciones y de manera casi transparente.
Si bien es cierto que la auto-instrumentación puede llegar a un punto de no ser suficiente, permite a los equipos arrancar los proyectos con un mínimo de capacidades a nivel de observabilidad. Además, la elección de los distintos backends en muchos casos no está definida al inicio de los proyectos, con OpenTelemetry conseguimos que podamos postergar la decisión sin afectar a la evolución del proyecto.
En el siguiente artículo de la serie, seguiremos profundizando en OpenTelemetry, en concreto en una de las piezas fundamentales de su arquitectura para entornos cloud, como es el collector.