
Observabilidad en entornos cloud usando OpenTelemetry (Parte 2)
Publicado por Manuel García de Vinuesa Gómez el
Introducción
En el artículo previo que puedes encontrar en el siguiente enlace estuvimos viendo qué es OpenTelemetry y cómo nos permite gestionar, mediante la auto-instrumentación, la emisión de las distintas señales que componente la observabilidad y como enviarlas a distintos backends.
En este nuevo artículo continuaremos hablando sobre opentelemetry y uno de sus componentes principales como es el collector. Exploraremos las capacidades del mismo y cómo nos puede ayudar a definir nuestra arquitectura de observabilidad, así como los distintos modos de despliegue que soporta.

OpenTelemetry Collector
El collector es el componente encargado de recibir toda la información de observabilidad que va a ser generada por las aplicaciones, dicho componente soporta varios formatos y protocolos, procesa los datos y los exporta a diferentes destinos. Es decir, actúa como un broker o un gateway entre la fuente de datos (las aplicaciones o sistemas) y los distintos backends que explotarán esos datos (Jaeger, Zipkin, Elastic...)
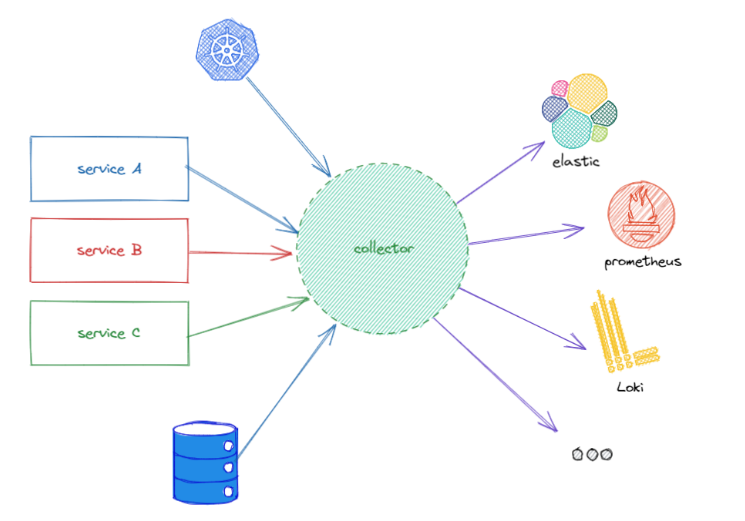
Lógicamente implica desplegar y mantener un nuevo componente dentro del sistema, punto que abordaremos más adelante, por lo que es importante conocer las posibles ventajas que nos va a ofrecer el uso del collector a nuestro stack de observabilidad.
- Desacoplar la fuente de datos del destino, en el artículo anterior vimos cómo podríamos plantear una migración de backends de trazas desde la aplicación cambiando tan solo la configuración de OpenTelemetry, lógicamente esto implicaba redesplegar la aplicación (imaginemos que tenemos cientos), con el collector podemos realizar esa misma casuística sin generar ningún impacto a las aplicaciones que actualmente están dando servicio.
- Las aplicaciones no tienen que conectar con los distintos backends, por lo que puede mejorar latencias y problemas de conexión, además el collector escala horizontalmente de manera muy sencilla, evitando posibles cuellos de botella.
- Volcar los datos del mismo tipo (métricas, trazas ,logs...) a distintos backends. En ciertos entornos empresariales se pueden dar más de un componente para la misma señal en función de las necesidades.
- Nos va a permitir definir pipelines que nos permitirán realizar filtrados y tratamiento de los datos recibidos sin necesidad de modificar la fuente de datos (las aplicaciones).
Componentes del collector
El collector se encarga de definir los pipelines para cada señal combinando distintos tipos de receivers, processors y exporters, además los receivers pueden soportar distintos protocolos de comunicación, por ejemplo, el receiver de Jaeger puede operar en Thrift y en gRPC.
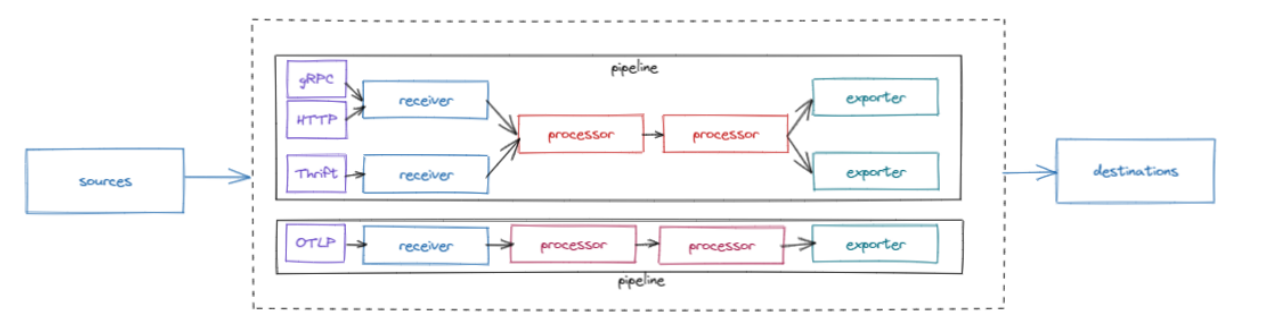
- Un receiver, define como los datos se consumen en el collector. El receiver acepta los datos en un determinado formato y los traduce al formato interno del componente para que posteriormente sean tratados por los processors y exportados a los distintos destinos por los exporters.
- Los processors se usan en varias fases de los pipelines. Permite pre-procesar el dato y aplicarle reglas antes de que sean exportados. Así como opciones de reintento o agrupación.
- Los exporters definen el destino de los datos de observabilidad, como las diferentes señales serán volcadas a distintos backends. El exporter es encargado de traducir el formato interno del componente al formato destino.
Configurar el collector para definir diferentes pipelines con los componentes anteriores es tan sencillo como crear el siguiente fichero de configuración eb formato yaml:
receivers:
otlp:
protocols:
grpc:
jaeger:
protocols:
thrift_binary:
processors:
batch:
exporters:
zipkin:
endpoint: <endpoint>
format: proto
jaeger:
endpoint: <endpoint>
logging:
logLevel: DEBUG
service:
pipelines:
traces/otlp:
receivers: [otlp]
exporters: [logging, zipkin]
processors: [batch]
traces/jaeger:
receivers: [otlp]
exporters: [jaeger]
En el fichero se definen los distintos receivers, processors y exporters, para posteriormente definir los pipelines que los agrupan formando un flujo de información.
En este artículo no entraremos de fondo en el uso de los processors, ya que existen multitud de ellos con diversos usos, si estáis interesados en ver que opciones ofrecen al collector podéis visitar los siguientes enlaces:
Ejemplo 2: Uso del collector
El objetivo de este ejemplo es mostrar como usar el collector como servicio que recibirá las diferentes señales de una aplicación auto-instrumentada. En este caso no exportaremos los datos a ningún servicio externo (backend de métricas) sino que usaremos el exporter por defecto de tipo logging para mostrar como el collector recibe las señales usando el protocolo OTLP.
El código de este ejemplo lo podéis encontrar aquí.
Para crear la nueva aplicación reaprovecharemos los tres primeros puntos del ejemplo del post anterior. La única diferencia es que vamos a añadir un logger para ver también como las señales de tipo log son emitidas al collector.
-
Añadir logger al código de la aplicación.
private static final Logger log = LoggerFactory.getLogger(HelloController.class); @GetMapping(value = "/hello") public String sayHello() { log.info("The application is saying Hello"); return "Hello"; } -
El fichero Dockerfile se mantiene exactamente igual. En cambio el fichero de docker-compose donde definimos el stack local, cambia:
version: '3' services: collector: image: otel/opentelemetry-collector-contrib:0.51.0 volumes: - ./otel-config.yml:/otel-config.yml command: ["--config=/otel-config.yml"] ports: - "4317:4317" # otlp receiver simple-collector-service: build: ./ environment: OTEL_SERVICE_NAME: "simple-collector-service" OTEL_EXPORTER_OTLP_ENDPOINT: "http://collector:4317" OTEL_LOGS_EXPORTER: "otlp" # logs are disabled by default due to Alpha status ports: - "8080:8080" depends_on: - collectorEn dicho fichero podemos ver:
-
Se han sustituido los backends de trazas y métricas y se ha añadido el collector. Dicho collector tiene definido su fichero de configuración y se expone en el puerto por defecto 4317.
-
Nuestro nuevo servicio, tiene una configuración distinta, en este caso OTLP como protocolo por defecto sólo necesita definir un único endpoint, ya que todas las señales se emiten bajo ese protocolo. Además, los logs al estar en fase Alpha no están activados por defecto, en nuestro caso, los activamos añadiendo la variable de entorno OTEL_LOGS_EXPORTER.
El fichero de configuración del collector, otel-config.yml lo creamos con el siguiente contenido:
receivers: otlp: protocols: grpc: exporters: logging: logLevel: DEBUG service: pipelines: traces: receivers: [otlp] exporters: [logging] metrics: receivers: [otlp] exporters: [logging] logs: receivers: [otlp] exporters: [logging]La configuración es muy sencilla, tan solo hemos creado un receiver, con el protocolo OTLP y un exporter, en este caso de tipo logging, que lo que nos mostrará por consola la información recibida por el collector. Por último, los pipelines, para cada una de las señales su respectivo receiver y exporter.
-
-
Levantamos el stack en nuestro local vía docker-compose y en consola vamos a activar los logs del collector para ver que se recibe, recordemos que hemos añadido un exporter de tipo logging. Para ello, primeramente localizamos el nombre del contenedor y posteriormente lanzamos el comando logs:
docker-compose ps NAME COMMAND SERVICE STATUS PORTS simple-collector-service-collector-1 "/otelcol-contrib --…" collector running 0.0.0.0:4317->4317/tcp, :::4317->4317/tcp, 55678-55679/tcp simple-collector-service-simple-collector-service-1 "/bin/sh -c 'java -j…" simple-collector-service running 0.0.0.0:8080->8080/tcp, :::8080->8080/tcp docker-compose collector logs simple-collector-service-collector-1 -f -
Lanzamos una petición de la misma manera que el ejercicio anterior y comenzamos a revisar los logs generados.
- Para localizar las trazas, ver el log generado a partir del TracesExporter
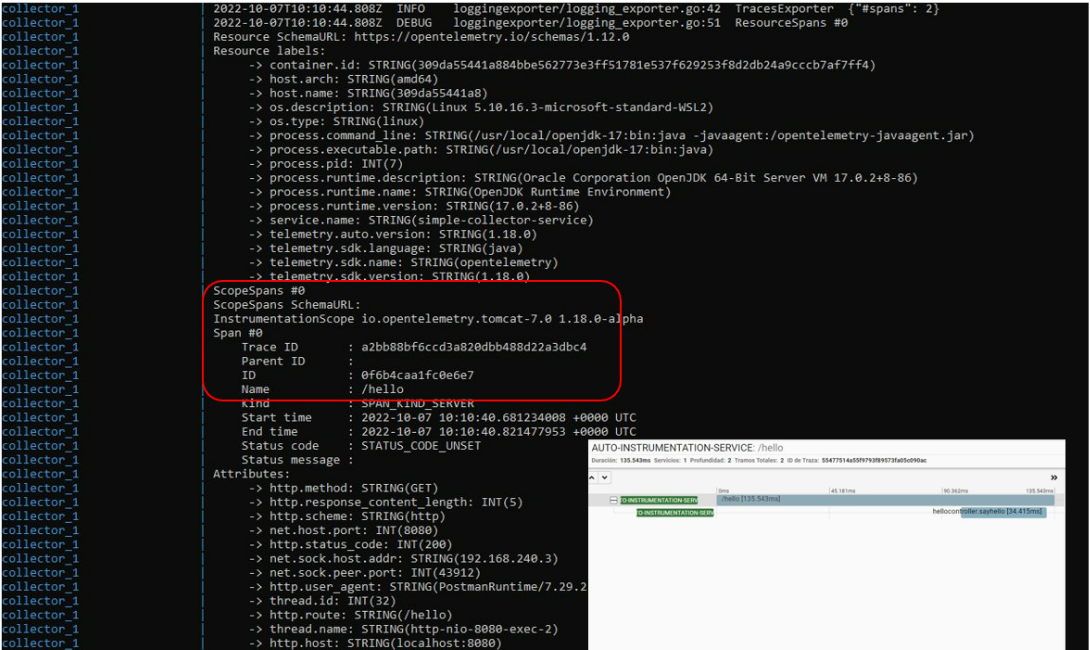
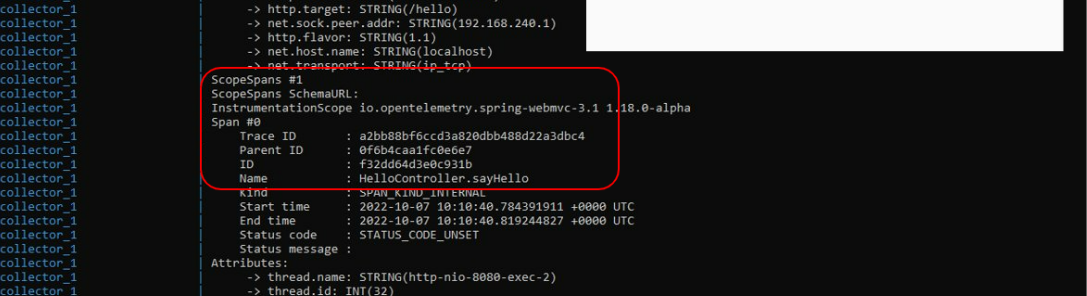
En dichos logs podemos ver la estructura de la traza recibida, los distintos Spans que contiene y los atributos o tags asociadas a la misma. Toda la información sobre las trazas y los spans la podéis revisar aquí. - Para localizar las señales de tipo log, tenemos que localizar el log del collector LogExporter.
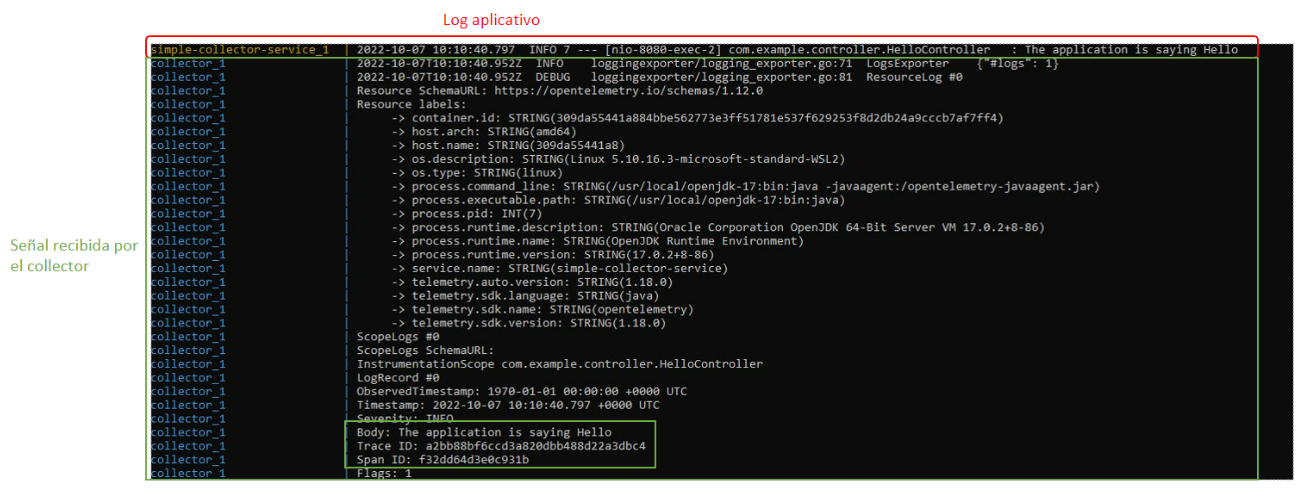
De la misma manera que las trazas, la señal de log contiene toda la información que la relaciona con la traza en la que está contenida. En el campo body aparece el mensaje de log.
- Para las métricas, es un poco diferente, ya que las métricas entre la aplicación y el collector no se mandan bajo petición, sino que cada cierto intervalo definido con la variable OTEL_METRIC_EXPORT_INTERVAL (defecto 60s) se manda las métricas gestionadas por la aplicación al collector. En el siguiente ejemplo vemos un conjunto de métricas relacionadas con el consumo de memoria en la JVM.
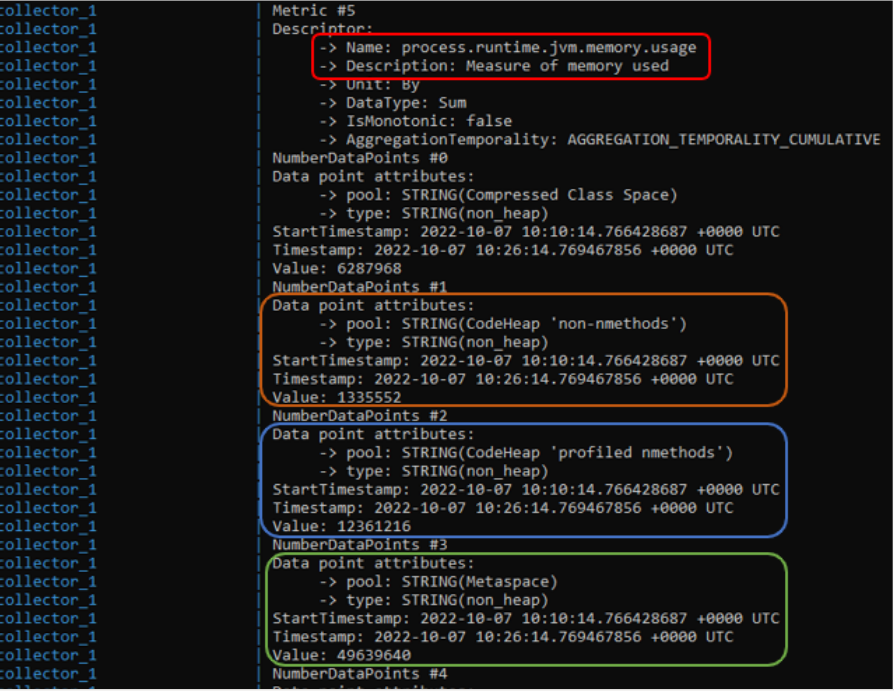
- Para localizar las trazas, ver el log generado a partir del TracesExporter
Ejemplo 3: Conectando el collector a distintos backends
El collector nos va a permitir desacoplar aún más la generación de datos de su destino final, en el primer ejemplo del post anterior vimos cómo cambiar de un backend a otro pasaba por simplemente ajustar la configuración en las aplicaciones.
Usando el collector este paso se simplifica aún más, ya que las aplicaciones no se ven afectadas. En el siguiente ejemplo vamos a ver cómo conectar una aplicación a distintos backends a través del collector.
Además vamos a probar otro de los conceptos de la observabilidad que no hemos trabajado aun, la propagación de contexto y como éste se propaga usando la auto-instrumentación usando distintas librerías de invocación HTTP entre servicios.
El código de este ejemplo lo podéis encontrar aquí. Dado que en este ejemplo vamos a usar varios servicios, no iremos paso a paso explicándo cómo crearlos siguiendo el caso anterior. Os recomendamos bajaros el código directamente y continuar paso a paso este ejemplo.
El diagrama de componentes de este ejemplo es el siguiente:
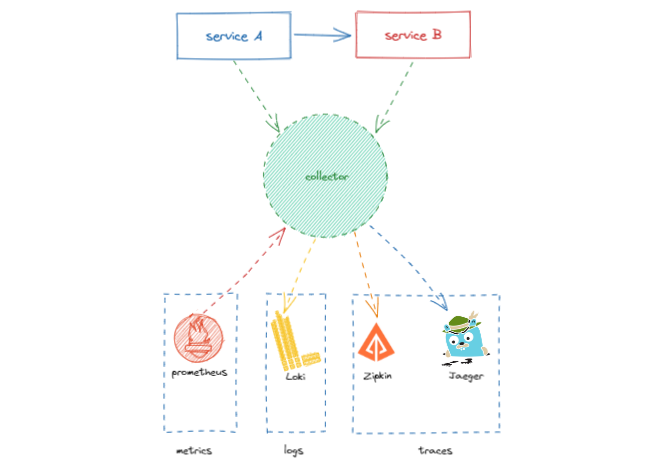
En este caso se ha optado por la gestión de las distintas señales en los siguientes backends:
- Métricas: En prometheus.
- Logs: Loki, en este caso para visualizarlos usaremos Grafana.
- Trazas: Zipkin y Jaeger, siguiendo con los ejemplos anteriores donde realizabamos migraciones.
-
Revisar los servicios descargados. En este ejemplo el servicio A invocará al servicio B mediante HTTP usando el WebClient de spring-boot, por tanto la traza contendrá todos los Spans de la ejecución de ambos servicios. En ambos casos se escriben logs para posteriormente mostrarlos en el backend de logs.
-
La principal diferencia en este caso será nuestro fichero de docker-compose, ya que el stack que presentamos es ligeramente diferente. En este caso, podemos identificar:
- Los distintos backends de trazas, como son Jaeger y Zipkin:
jaeger: image: jaegertracing/all-in-one:latest ports: - "16686:16686" - "14268" - "14250:14250" zipkin: image: openzipkin/zipkin:latest ports: - "9411:9411" - El backend de métricas, en este caso prometheus, con el fichero de configuración que comentaremos a continuación:
prometheus: image: prom/prometheus:latest volumes: - ./prometheus.yml:/etc/prometheus/prometheus.yml ports: - "9090:9090" - El backend de logs, en este caso Loki y Grafana para visualizarlos. En este caso es configuración por defecto para Loki, en el caso de grafana enlazamos una carpeta donde definiremos los datasources de los que debe extraer la información para visualizarla.
loki: image: grafana/loki:2.3.0 ports: - 3100:3100 command: -config.file=/etc/loki/local-config.yaml grafana: image: grafana/grafana:8.3.3 ports: - 3000:3000 volumes: - ./grafana/provisioning:/etc/grafana/provisioning environment: - GF_AUTH_ANONYMOUS_ENABLED=true - GF_AUTH_ORG_ROLE=Editor - GF_AUTH_ANONYMOUS_ORG_ROLE=Admin - GF_AUTH_DISABLE_LOGIN_FORM=true - GF_USERS_DEFAULT_THEME=light - Los servicios A y B, que conectan con el collector para mandar las distintas señales. Al servicio A se le está inyectando la URL del servicio B para poder invocarle.
service-a: build: ./service-a environment: OTEL_SERVICE_NAME: "service-a" OTEL_EXPORTER_OTLP_ENDPOINT: "http://collector:4317" OTEL_LOGS_EXPORTER: "otlp" HELLO_URL: "http://service-b:8080" ports: - "8080:8080" depends_on: - collector service-b: build: ./service-b environment: OTEL_SERVICE_NAME: "service-b" OTEL_EXPORTER_OTLP_ENDPOINT: "http://collector:4317" OTEL_LOGS_EXPORTER: "otlp" ports: - "8081:8080" depends_on: - collector - Y por último el collector. Muy similar al caso anterior excepto porque la configuración variará para poder exportar la información a los distintos backends. La principal diferencia, en el ejemplo del post anterior Prometheus hacía scrapping contra la aplicación, ahora lo hará contra el collector y por tanto se exponen el puerto 8888 y 8889 para la exposición de las métricas aplicativas y del propio collector.
collector: image: otel/opentelemetry-collector-contrib:0.51.0 volumes: - ./otel-config.yml:/otel-config.yml command: ["--config=/otel-config.yml"] ports: - "8888:8888" # Prometheus metrics exposed by the collector - "8889:8889" # Prometheus exporter metrics - "4317:4317" # otlp receiver depends_on: - jaeger - zipkin
- Los distintos backends de trazas, como son Jaeger y Zipkin:
-
En este punto vamos a revisar los distintos ficheros de configuración necesarios para los distintos componentes:
-
Para Prometheus, como hemos comentado, haremos scrapping contra el collector para obtener las métricas, para ello el fichero prometheus.yml contendrá dos jobs para obtener las distintas métricas:
scrape_configs: - job_name: "opentelemetry-collector" scrape_interval: 5s static_configs: - targets: ["collector:8888"] - job_name: "applications" scrape_interval: 5s static_configs: - targets: ["collector:8889"] -
Para grafana, es necesario definir el datasource de Loki, para ello en la ubicación grafana/provisioning/datasources se crea un fichero loki.yml con el siguiente contenido:
apiVersion: 1 deleteDatasources: - name: Loki orgId: 1 datasources: - name: Loki type: loki access: proxy uid: loki_datasource url: http://loki:3100 password: user: database: basicAuth: false basicAuthUser: basicAuthPassword: withCredentials: isDefault: false version: 1 editable: true jsonData: maxLines: 1000 derivedFields: # Field with external link. - matcherRegex: "traceID=(\\w+)" name: TraceID url: "http://localhost:16686/trace/$${__value.raw}"Lo más interesante de este fichero es la URL de conexión a Loki y que vamos a definir que el campo traceID de los logs se enlace con por ejemplo Jaeger. Para ello en derivedFields creamos la redirección.
-
Y por último, la configuración del collector.
receivers: otlp: protocols: grpc: exporters: prometheus: endpoint: "0.0.0.0:8889" resource_to_telemetry_conversion: enabled: true zipkin: endpoint: "http://zipkin:9411/api/v2/spans" format: proto jaeger: endpoint: jaeger:14250 tls: insecure: true loki: endpoint: http://loki:3100/loki/api/v1/push labels: resource: service.name: "job" logging: logLevel: DEBUG service: pipelines: traces: receivers: [otlp] exporters: [logging,zipkin,jaeger] metrics: receivers: [otlp] exporters: [logging,prometheus] logs: receivers: [otlp] exporters: [logging,loki]En dicha configuración podemos ver los distintos exporters, Prometheus, Jaeger, Zipkin y Loki que formarán parte de los pipelines de trazas, métricas y logs.
-
-
De la misma manera que en los demás ejercicios, levantamos el stack con docker-compose, lanzamos la siguiente petición:
curl --location --request GET 'localhost:8080/call/hello'Y exploramos los distintos backends.
-
A nivel de trazas, en Jaeger y Zipkin podemos ver como la llamada entre servicios se mantiene en la misma traza, creando los distintos Spans dentro de cada servicio, es decir, hay propagación de contexto de manera completamente transparente.
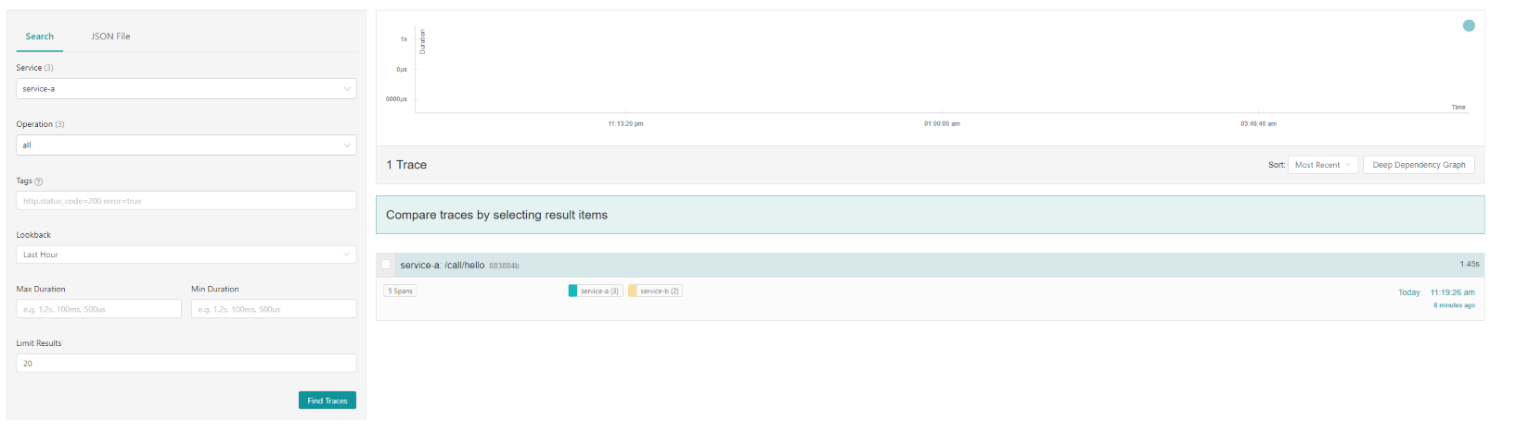

-
En Prometheus, las métricas de ambas aplicaciones.
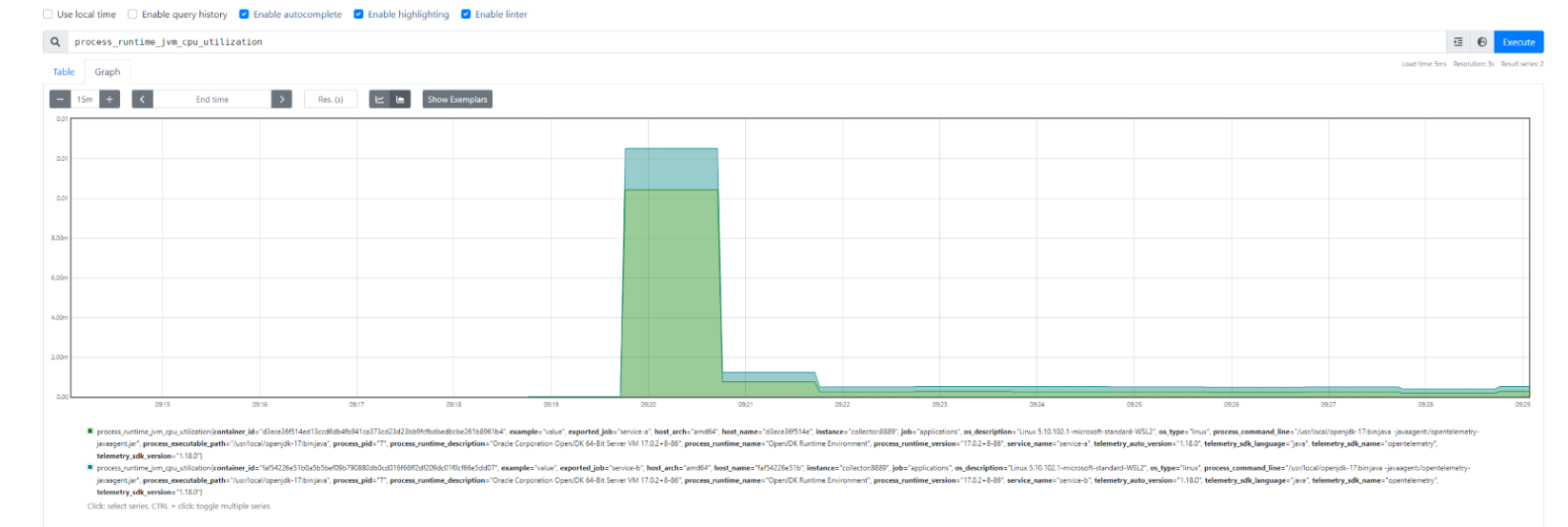
-
Y los logs, accediendo a través de Grafana (aunque están alojados en Loki) para ello navegamos a: http://localhost:3000/explore y realizamos la siguiente navegación:
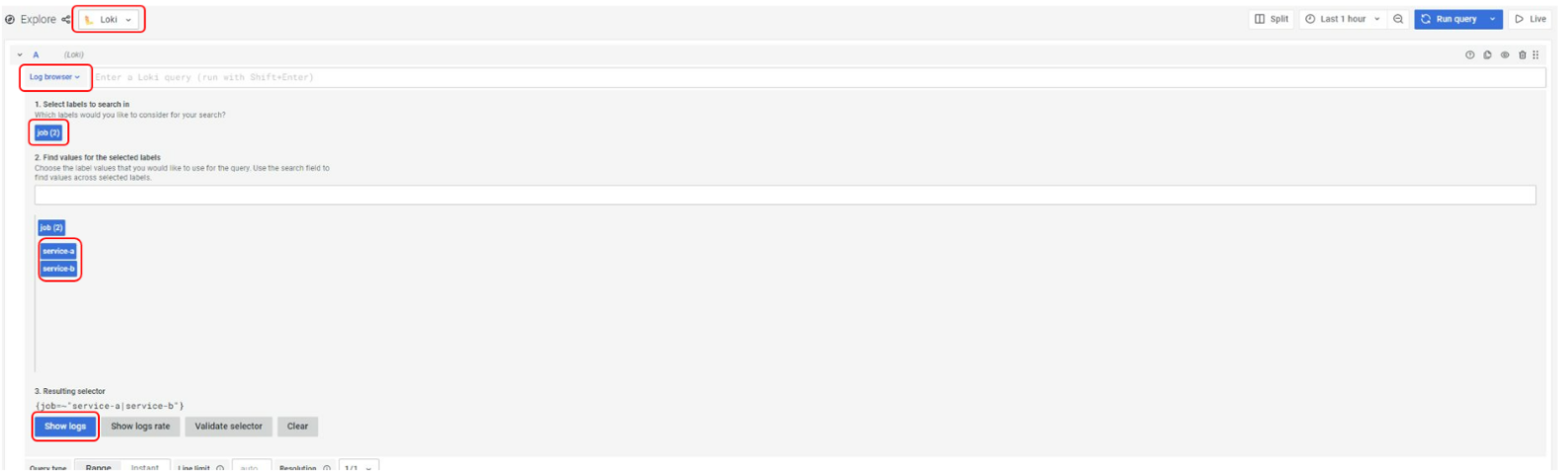
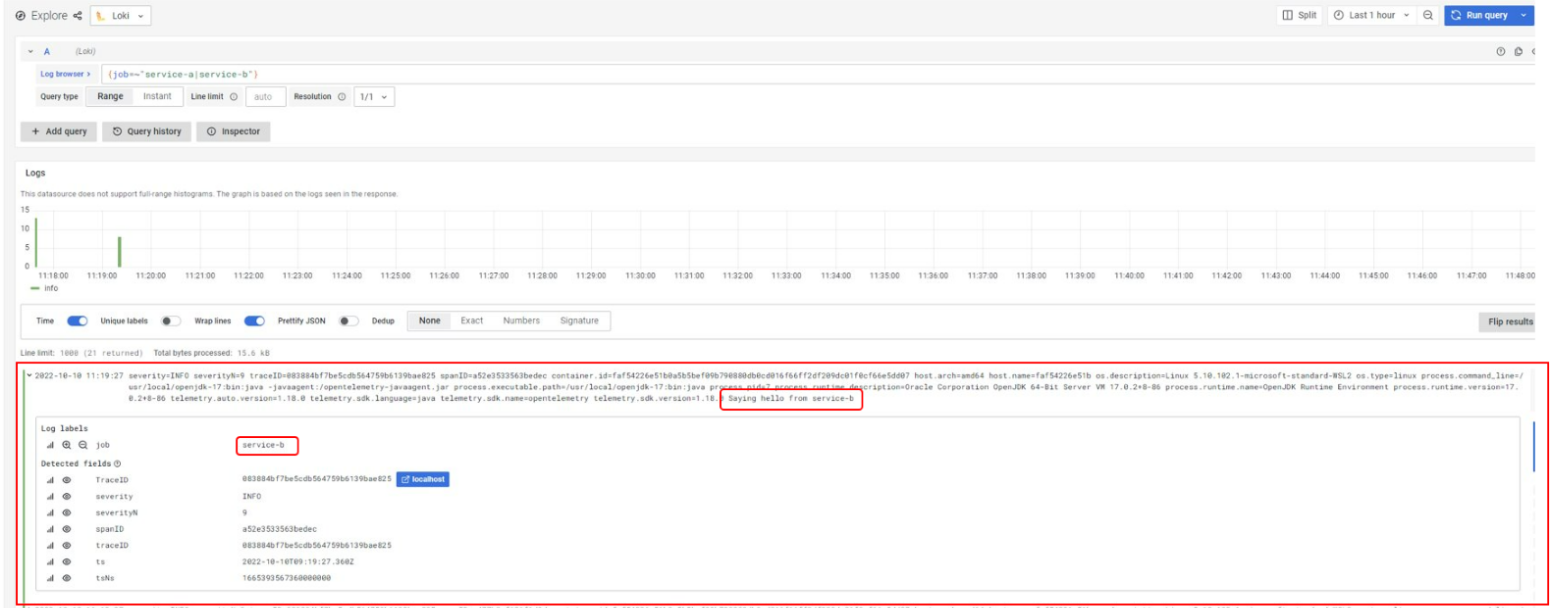

En este ejercicio hemos podido ver cómo conectar el collector a los distintos backends para explotar los datos. Cómo se configura y definen sus pipelines para añadir versatilidad al tratamiento de señales.
Aunque no se ha profundizado, se ha explicado cómo los procesadores nos pueden ofrecer ventajas a la hora de tratar los datos, filtrarlos y agruparlos.
En el siguiente punto vamos a explicar los distintos modos de despliegue del collector, ya que una de sus principales ventajas es la capacidad de despliegue en entornos cloud y las posibilidades que esto permite.
Modelos de despliegue del collector
En el ejemplo anterior hemos visto cómo el collector se despliega como un servicio independiente y las aplicaciones se conectan para enviarle información. Pero la potencia de este componente no sólo está ahí, si no en la versatilidad que ofrece a la hora de desplegarlo y que le va a permitir, en función de la casuística, adaptarse a las necesidades de nuestra organización.
En los siguientes puntos se abordarán principalmente de manera teórica los distintos modelos de despliegue. Estos modelos están pensados para trabajar principalmente en clúster basados en kubernetes y aprovechar las ventajas de dicha plataforma junto con la versatilidad del collector.
Por tanto, si no estas familiarizado con el stack de kubernetes puede que la siguiente sección sea complicada de abordar, para ello aquí tenéis un pequeño resumen de los principales conceptos:
-
POD: Es la unidad mínima de despliegue en Kubernetes, nos va a permitir desplegar un contenedor o varios.
-
Sidecar: Es un patrón de despliegue. Se trata de desplegar un componente lo más próximo posible a nuestra aplicación que ofrezca una determinada funcionalidad.
-
Nodo: Un clúster de kubernetes se divide en workers, son las máquinas (físicas o virtuales) que componen dicho clúster.
-
DaemonSet: Es una especialización de cómo vamos a desplegar un POD, en este caso se garantiza que hay un POD en cada nodo del cluster.
-
Helm: Es una herramienta (package manager) que nos facilita la vida para trabajar con Kubernetes y poder desplegar aplicaciones (normalmente una aplicación conlleva desplegar distintos componentes de kubernetes).
-
Operador de Kubernetes: Otra herramienta que nos va a permitir empaquetar y gestionar aplicaciones de la plataforma, no es lo mismo que Helm, pero no entra dentro de este artículo explicar las diferencias y cuando usar uno y otro. Un operador nos va a permitir gestionar el ciclo de vida de una aplicación de manera completa.
Dicho esto, el collector se puede desplegar de las siguientes maneras:
-
Como sidecar a nuestra aplicación, para recoger toda la información de nuestra aplicación de manera que el collector esté lo más cerca posible a la aplicación, de esta manera los datos se emiten cuanto antes y se reduce el posible impacto a la aplicación.
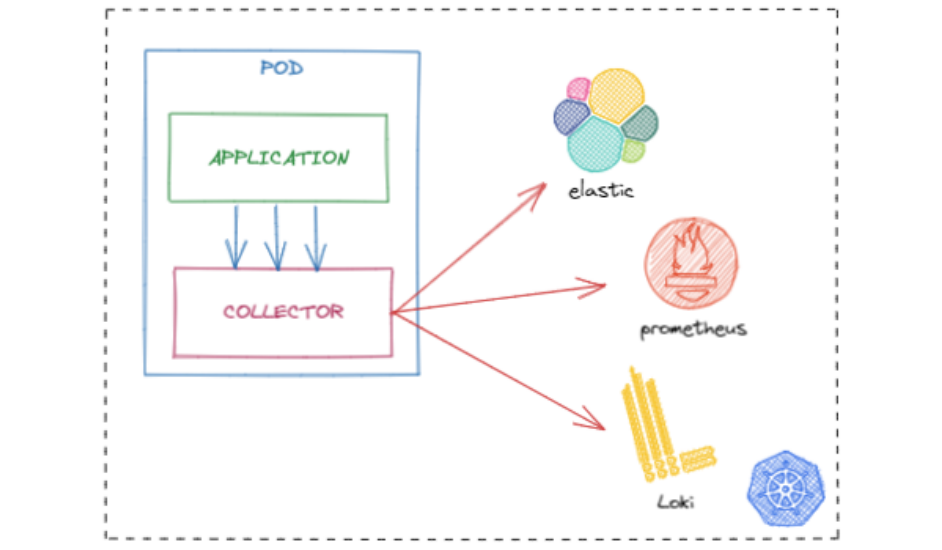
Con este modelo obtenemos las siguientes ventajas:
- La aplicación no debería tener ningún problema relacionado con la red a la hora de emitir las señales, ya que sidecar corre en el mismo POD y por tanto podemos acceder a dicho collector a través de localhost.
- Al no haber problemas de red y no haber latencia, los datos se emiten al instante y por tanto datos clave como CPU o memoria no se deben perder.
- En caso de necesitar procesadores específicos o pipelines específicos, se pueden gestionar en este punto en vez de en el collector más general.
Este modo de despliegue se consigue añadiendo en la definición del Deployment de Kubernetes, un contenedor con el collector:
spec: containers: - name: simple-collector-service image: simple-collector-service_simple-collector-service - name: collector image: otel/opentelemetry-collector:0.51.0 -
Como agente en cada host (DaemonSet en Kubernetes), que además nos permitirá recoger telemetría de los mismos.
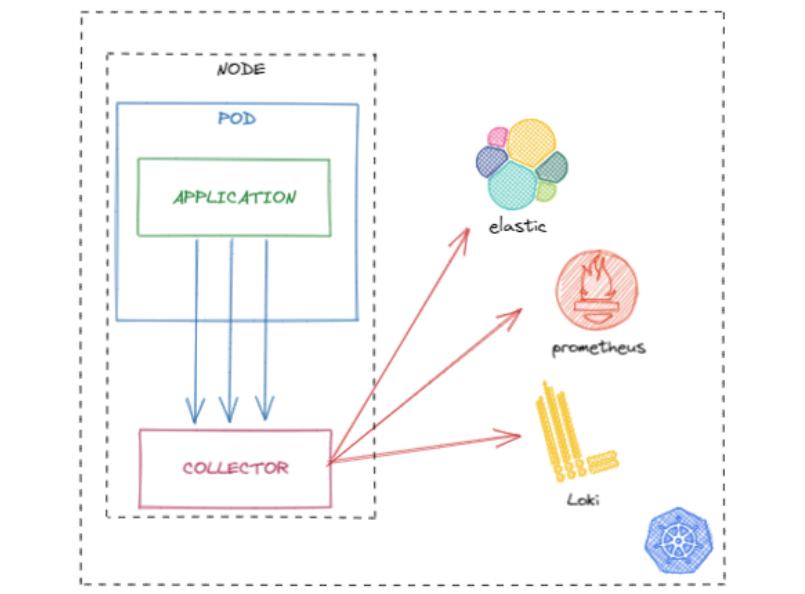
Con este modelo conseguimos lo siguiente:
-
Crear un punto de agregación en cada nodo, todos los PODs de un nodo volcarían sus datos en el agente, y este haría forward de los datos a los backends. Esto tiene ventajas a nivel de latencia y además reduce el número de conexiones finales contra el backend, ya que sólo se creerían desde los nodos al backend.
-
Obtener las métricas del host, en este caso de los nodos de kubernetes, para conocer su carga y detectar posibles complicaciones.
Para desplegar en Kubernetes el collector como agente podemos usar el Chart de Helm que nos ofrece OpenTelemetry.
-
-
Combinando el sidecar con el agente. De esta manera obtenemos las ventajas de ambos modelos y además se nos abre la posibilidad de organizar los procesadores en función de la necesidad, ciertos procesadores estarán orientados a negocio deberán estar en el sidecar y otros más técnicos podrían estar en el agente.
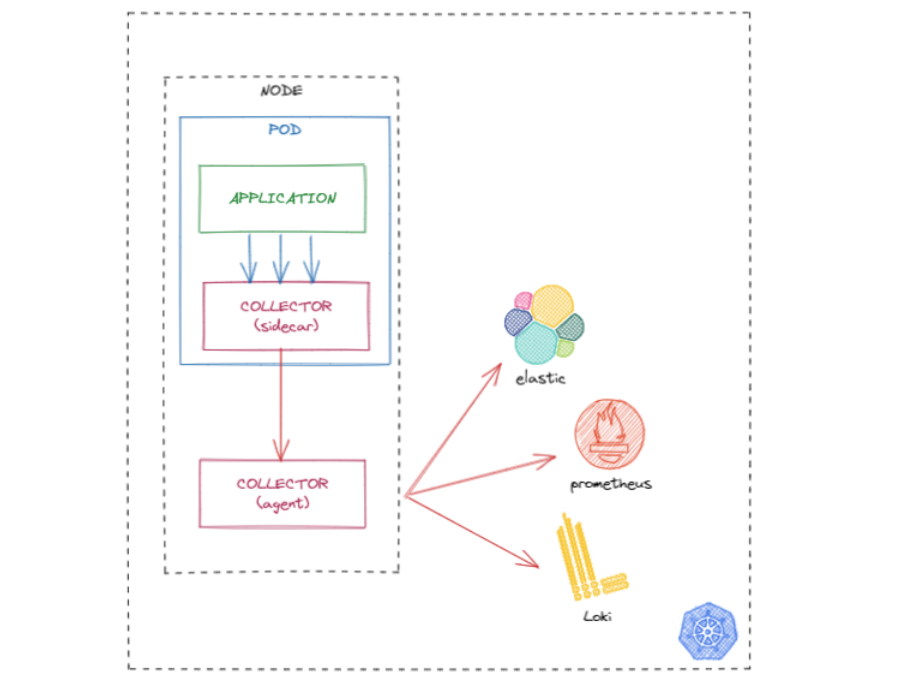
-
Añadiendo al modelo anterior, el collector como servicio independiente a modo de gateway, de la misma manera que en el caso anterior, donde combinábamos el sidecar y el agente, añadiendo el gateway a la ecuación aumentamos la versatilidad de la plataforma.
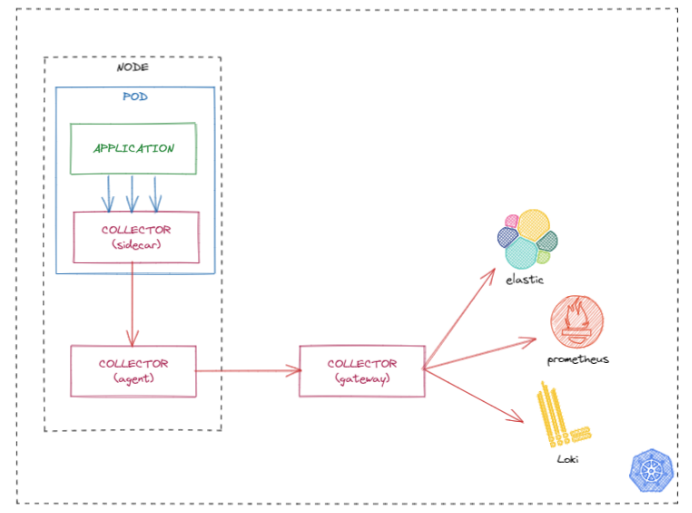
Las ventajas de usar este modelo de despliegue pasan por el escalado horizontal que puede soportar este nuevo servicio y que los procesadores orientados a seguridad y filtrado de información relacionado con los backends cuando son sistemas externos pueden ser aplicados en este punto.
De la misma manera que el agente, para desplegar este servicio nos podríamos apoyar en el mismo chart de helm pero parametrizando su entrada tal y como se explica en la documentación.
Por último, y como curiosidad, para manejar todos estos despliegues en un clúster de kubernetes y además auto-instrumentar las aplicaciones sin necesidad de modificar el dockerfile como hemos visto en los ejemplos, se puede plantear el uso de un operador de kubernetes proporcionado por OpenTelemetry. Podéis encontrar más información aquí.
Conclusiones finales
A lo largo de esta serie de artículos se ha revisado en profundidad como OpenTelemetry se está posicionando como el estándar de la observabilidad. Las capacidades de auto-instrumentación y el uso del collector en sus diferentes formas permiten asumir la adopción de la observabilidad en fases iniciales o tempranas del desarrollo de software, ya que por un coste muy pequeño podemos tener las aplicaciones generando trazas, métricas incluso logs.
Desde nuestro punto de vista las principales ventajas de esta iniciativa son:
- Capacidad de abstracción y desacoplamiento con la solución final, favoreciendo que los equipos de desarrollo no se tengan que preocupar por la generación de señales y añadiendo capacidades de migración y colecta de datos a diferentes backends de manera sencilla.
- Soporte a múltiples escenarios. OpenTelemetry nace con la idea de adaptarse a todo el ecosistema actual de observabilidad, por ello ofrece múltiples capacidades de integración y despliegue.Un ejemplo podría ser como datadog o dynatrace implementan su propio agente de métricas basado en OTLP para ser compatible con OpenTelemetry. OTLP Trace Ingestion by the Datadog Agent y OpenTelemetry traces with OneAgent o como Dapr se puede integrar con el collector de OpenTelemetry
- Soporte a múltiples vendors, lenguajes y librerías. Una comunidad de contribuidores amplia y soporte de vendors para la evolución de la iniciativa. EL proyecto nace tras la fusión de dos iniciativas importantes como son OpenCensus y OpenTracing, además vendors como Splunk, Dynatrace, Amazon, Google, Lightstep, Microsoft, y Uber están detrás de dicha iniciativa como contribuidores, por tanto se debe considerar a OpenTelemetry como un nuevo estándar en el mercado.
Si tuviéramos que decir algunos puntos a mejorar o a tener en cuenta:
- Aunque hay multitud de artículos, libros y blogs sobre el tema, la documentación oficial no es demasiado completa, en muchos casos hay que navegar a los distintos repositorios de github para complementar información y ciertas cosas se dan por hechas o sabidas.
- A nivel de rendimiento y tunning de la solución (collector) quizás falta disgregar bien los escenarios y aportar más información al respecto. Actualmente apenas se encuentra información o no es demasiado completa. opentelemetry-collector/performance.md
- Todavía está en algún caso o puntos en fase experimental, por ejemplo los logs, o ciertos exporters, por lo que debe tomarse con precaución su uso productivo a todos los efectos para aquellos componentes no considerados estables.
Bibliografía y enlaces de interés
- https://geekflare.com/opentelemetry-introduction/
- https://www.datanami.com/2021/09/23/opentelemetry-gains-momentum-as-observability-standard/
- https://medium.com/opentelemetry/deploying-the-opentelemetry-collector-on-kubernetes-2256eca569c9
- https://learning.oreilly.com/library/view/cloud-native-observability-with/9781801077705/
- https://learning.oreilly.com/library/view/distributed-systems-observability/9781492033431/
- https://signoz.io/blog/opentelemetry-collector-complete-guide
- https://signoz.io/blog/opentelemetry-spring-boot/
- https://betterprogramming.pub/distributed-tracing-with-opentelemetry-spring-cloud-sleuth-kafka-and-jaeger-939e35f45821
- https://medium.com/wwblog/auto-instrumentation-with-opentelemetry-3b096fdd068f
- https://medium.com/apache-apisix/end-to-end-tracing-opentelemetry-a50fceafed74