
Presentando Apache Pulsar
Publicado por javier sanz el
Arquitectura de SolucionesApache AvroPulsarMensajeríaEventos
El objetivo de este artículo es dar a conocer Apache Pulsar, sus principales características y mostrarlo como alternativa a otros sistemas de mensajería distribuida del mercado llámense Kafka, RabbitMQ, Apache RocketMQ, etc., sin entrar en la comparativa con los mismos.

Un poco de historia.
Durante 2012, Yahoo! Japón requería internamente de unos sistemas de mensajería orientados a resolver una serie de problemas y no acababan de encontrar soluciones en el mercado ni en la comunidad Apache, de los cuales destacaban:
- Dar servicio a muchos clientes.
- Desplegar muchos servicios.
- Gestionar mensajería segura y crítica (latencia y garantías entrega).
- Despliegue en múltiples centros de datos.
Todos ellos se podrían resumir en que tenían que partir de un sistema centrado en disponer de capacidades en la gestión del almacenamiento más allá de ofrecer un potencial de procesamiento extremo.
Hasta 2014, básicamente no se inició el desarrollo de lo que sería Yahoo! Pulsar, ya poniendo sobre la mesa internamente que estaban desarrollando un nuevo producto mientras existían alternativas como ActiveMQ, Kafka o RabbitMQ.
En años siguientes, estuvieron trabajando en el proyecto y para 2017 donaron una versión a la fundación Apache y ésta, que es la que podemos utilizar, se presentó sobre 2018. Había nacido Apache Pulsar.
Hay que poner siempre el contexto sobre cómo opera Yahoo! Japón en el sentido de colaboración con la comunidad. No es precisamente un referente, por no entrar en cómo se inició el proceso de donación a la fundación Apache. En fechas posteriores y sucesivas evangelizaciones, muchos programadores Yahoo! han ido reconociendo que la versión Yahoo! Pulsar tiene más funcionalidades, que claro, no fueron entregadas como Apache Pulsar (que se están desarrollado a día de hoy), seguramente por cubrir necesidades muy específicas (y no publicables) de Yahoo! Japón.
Donaron una gran idea, solución, pero no su "producto estrella", sabiendo que se apoyaban en múltiples proyectos de la comunidad, en especial, Apache BookKeeper. También es cierto, que, dentro de la comunidad Apache, hay recurrentemente tiranteces sobre "quién" colabora en "qué" y "porqué" se hacen las cosas a determinados "ritmos". Búsquese, por ejemplo, las colaboraciones sin ánimo de lucro de los desarrolladores Confluent/Kafka en proyectos Apache. Una a modo de entretenimiento, Apache OpenWhisk.
También otro aspecto a tener en consideración era: ¿en qué modelos de arquitectura trabajaban en Yahoo! Japón por esas fechas?
Casi todos los diseños de arquitecturas de procesamiento masivo caían en dos modelos genéricos, el modelo Lambda o el Kappa y aquí vemos un ejemplo de lo que se mueve entre bambalinas.
La arquitectura Lambda, definida Nathan Marz, nos ayudaba con un modelo de procesamiento que permitía tanto streaming como batch, procesamiento de vistas, etc., una solución que arrancaba con Apache Storm y marco los pasos conceptuales a seguir de todo lo que había que hacer en la resolución de ese tipo de problemas.
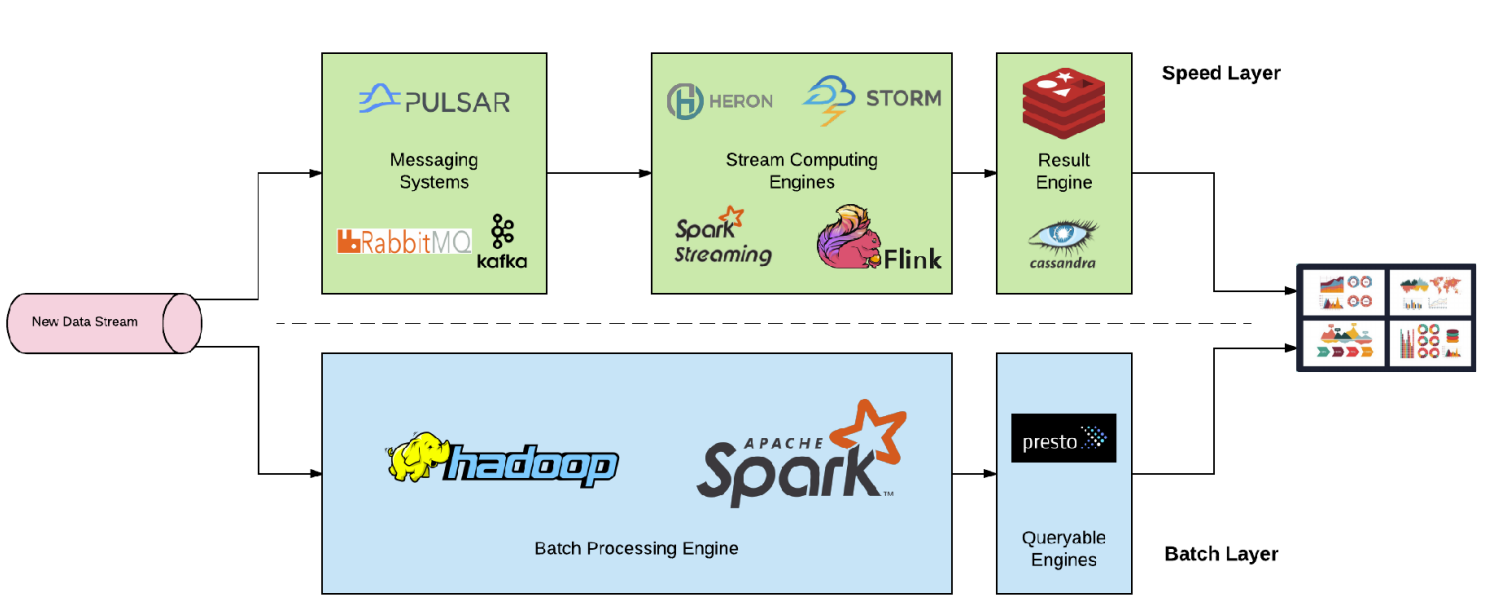
Y, por otro lado, aparecieron las alternativas, cuya premisa fundamental era que el modelo era "muy complejo" y uno de ellos, por no decir el principal fue... Jay Kreps. ¿Quién es este señor?
"I wrote a new blog post on stream processing and an alternative to the Lambda Architecture"
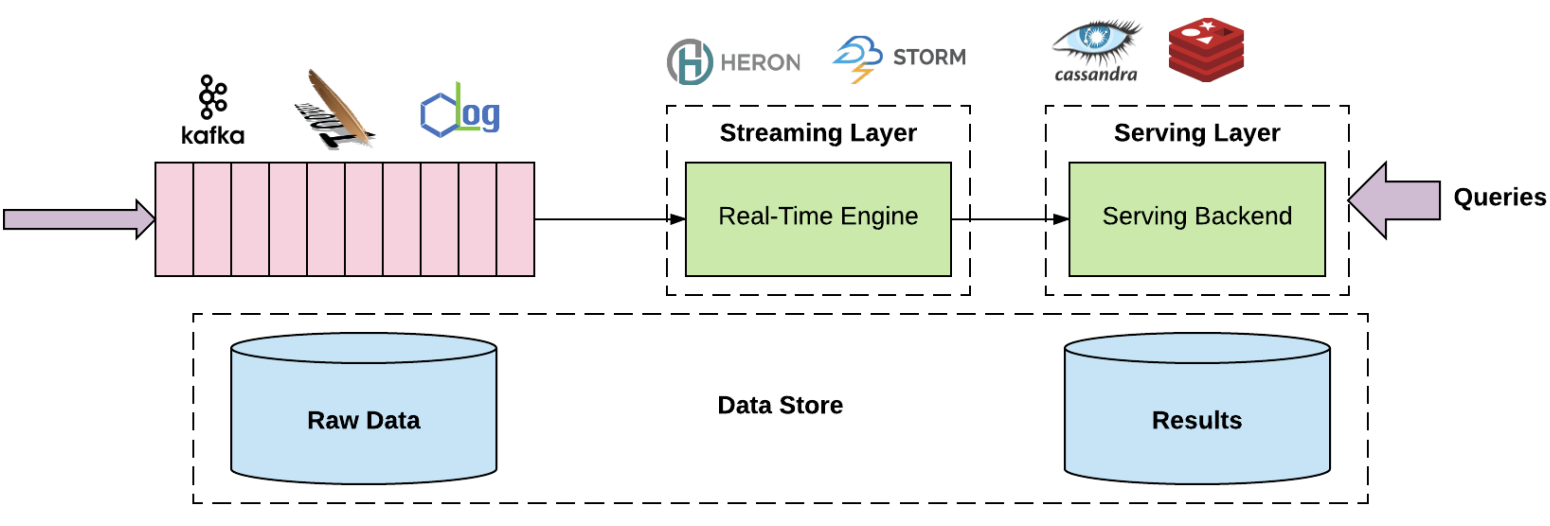
Bueno, uno de los creadores de Kafka. Este señor dijo que el modelo Lambda era complejo y de difícil uso. De todos modos, ¿Kappa es mucho más sencillo?... un poco más de lo mismo, pero de lo mismo que sólo aplicaba centrado y usando Kafka.
Sí hay que hacer mención a sus esfuerzos por hacer que Kafka se entendiera, dado que se fundamenta en el procesamiento de logs. Su artículo introductorio es:
The Log: What every software engineer should know about real-time data's unifying abstraction
Y también tiene un libro muy interesante, al que no le voy a hacer publicidad.
Frente a estos dos escenarios, Yahoo! Japón parece que decidió orientar Yahoo!Pulsar como una herramienta que pudiera coger lo mejor de las dos propuestas y empaquetarla en una para cubrir sus necesidades (cosas distintas en sitios distintos):
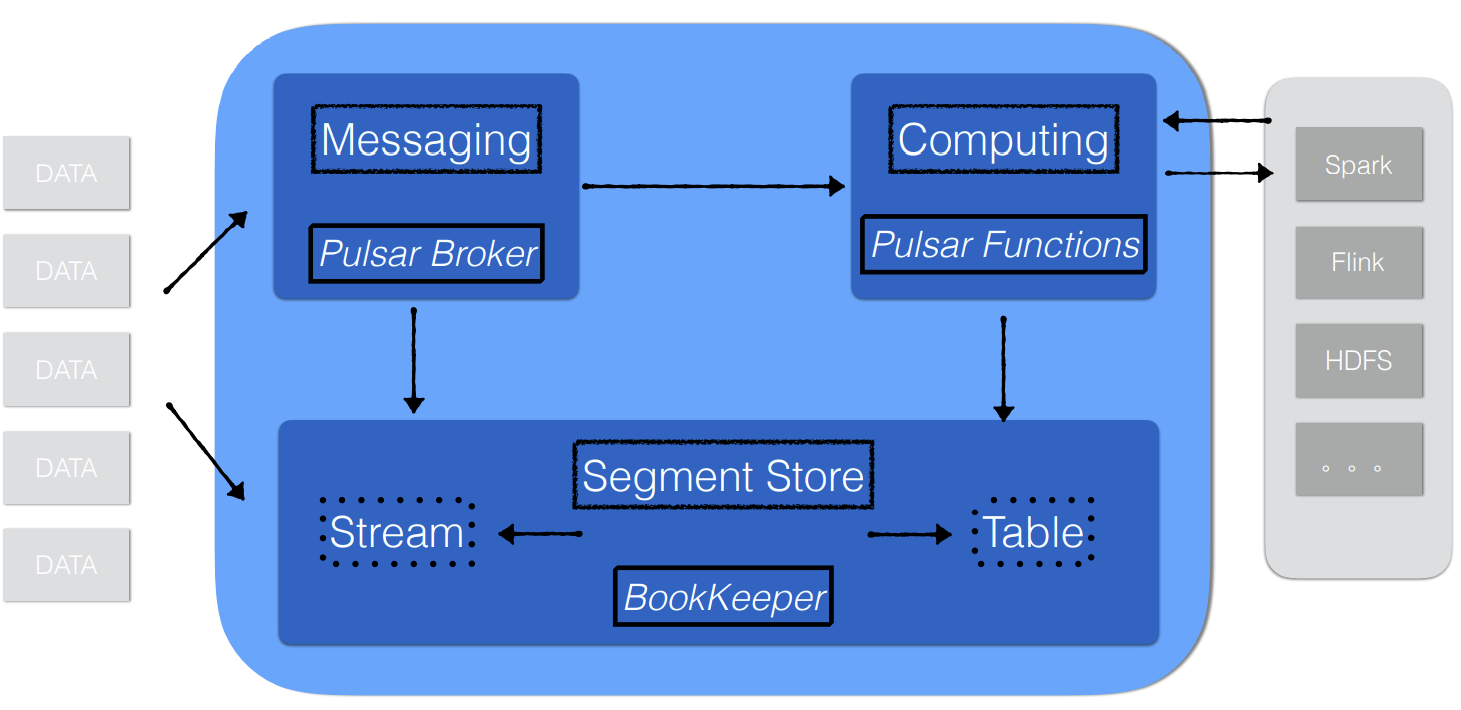
Apache Pulsar.
¿Qué nos ofrece Apache Pulsar como un sistema distribuido de mensajería y para que debería ser?:
- Geo-Replication, como mecanismo para ofrecer disaster recovery. Toda la información se replica entre las distintas localizaciones. Soporta multi-datacenter replication(n-mesh).
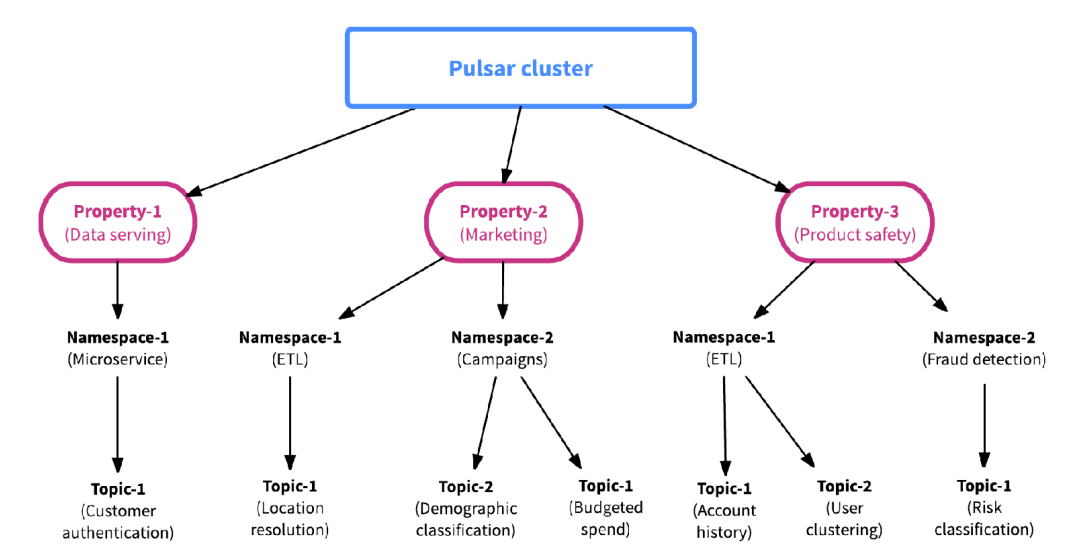
- Multi-Tenancy, un cluster puede procesar varios tenants (unidades lógicas independientes) y sus casos de uso. Básicamente, con esta propiedad se buscaba obtener una separación de los datos procesados y almacenados en los distintos clusters Pulsar, aunque se vea un todo unificado. Enlazado con la propiedad de durabilidad.
- Delivery Guarantees, la garantía de entrega: At least once, at most once and effectively once.
- Ordering, se garantiza el orden.
- Unified Queuing and Streaming Model, soporte para streaming y colas en el mismo modelo.
- Highly Scalable, puede soportar millones de topics.
- High Throughput, soporte para operar con millones de mensajes en una misma partición.
- Pulsar Proxy, mecanismo de exposición/acceso a los cluster Pulsar (brokers)
- Functions, elementos de ejecución basando en listeners, ¿eventos?, que pueden ejecutarse dentro de Pulsar o fuera de él.
El modelo de arquitectura para Apache Pulsar.
Pulsar se compone de unos pocos elementos fundamentales, cuya principal característica de conceptualización fue algo tan, novedoso, como que se pudieran mantener siempre conceptual y realmente separados:
- Brokers, gestionan los mensajes, enviándolos para su almacenamiento a los nodos BookKeeper-bookies y a los consumidores, en función de los tópicos, colas, etc.
- BookKeepers, que se componen de nodos (bookies) encargados de almacenar de forma persistente de los mensajes.
- ZooKeeper, coordinación, metadatos y configuración de los clusters de Pulsar.
La Mensajería.

Los brokers y los bookies se pueden añadir independientemente y se gestionan para ofrecer durabilidad, capacidad de almacenamiento, rendimiento, baja latencia, etc.
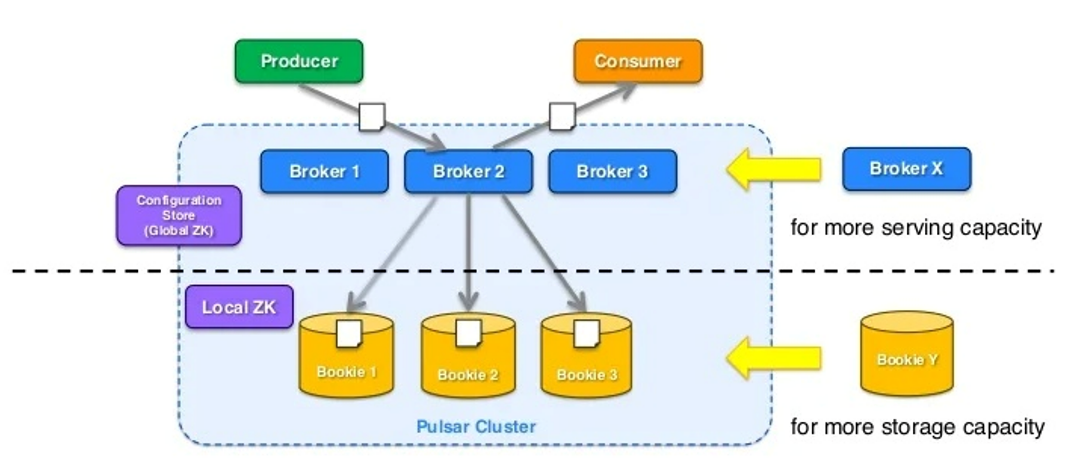
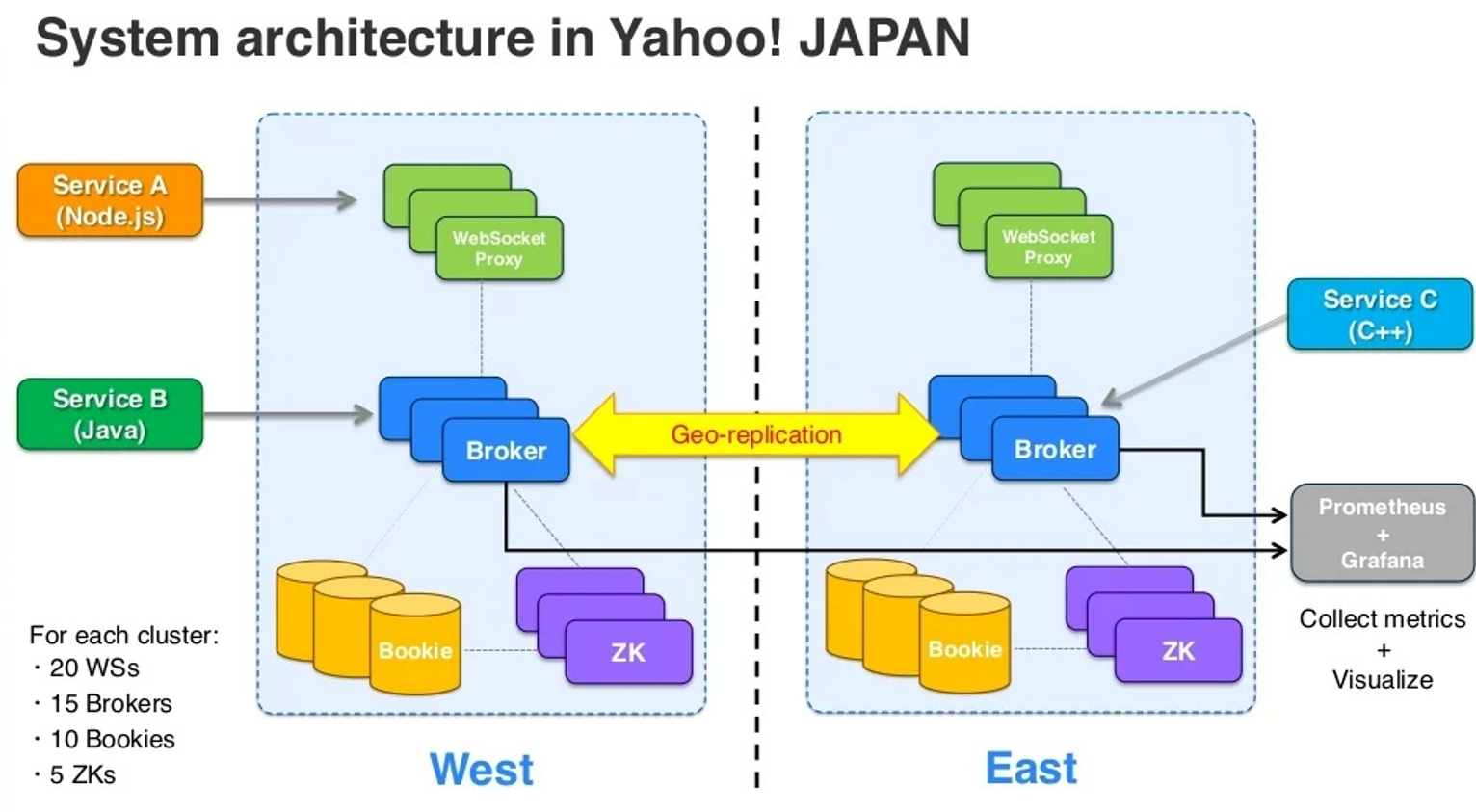
Y así por ejemplo, Yahoo!Japón tiene desplegado Pulsar en distintas localizaciones,
El uso de Pulsar como tenant implica que no hay necesidad de mantener tu propio sistema de mensajería, "está ahí, parece que es únicamente tuyo, pero en realidad está compartido, es de otros y no lo mantengo",
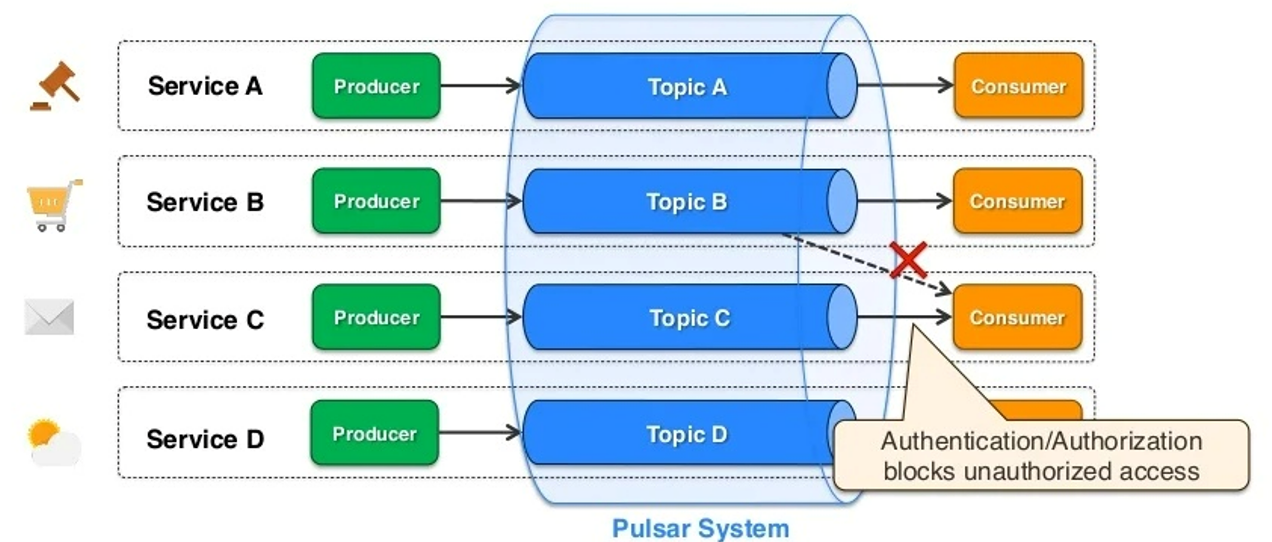
Un sistema multitenant con abstracciones por namespaces,
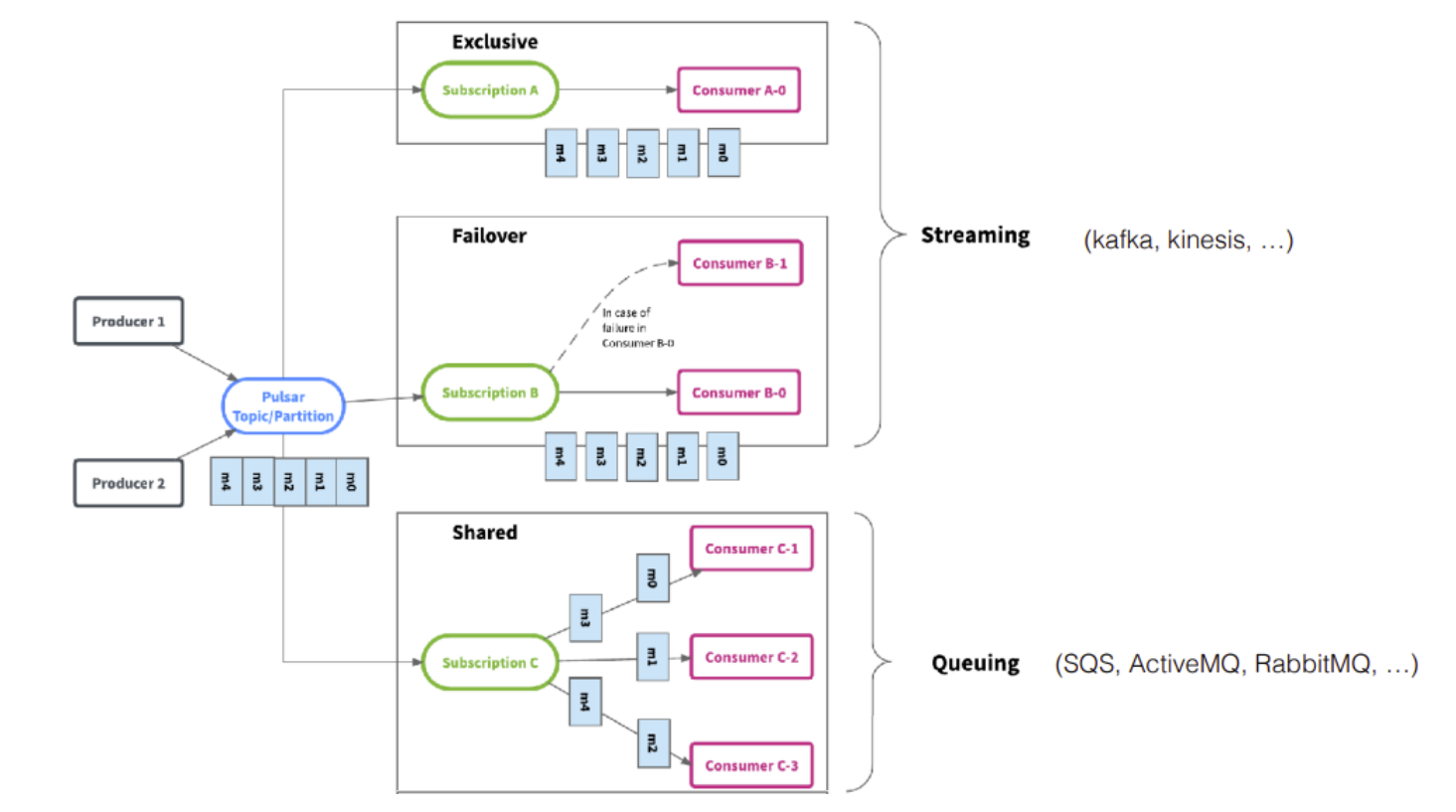
En lo que respecta a las capacidades de procesamiento de los mensajes, las opciones disponibles por los sistemas de mensajería en general, resolviendo ciertos problemas de garantías, escalabilidad, etc., los clásicos exclusive, failover, shared, key_shared.
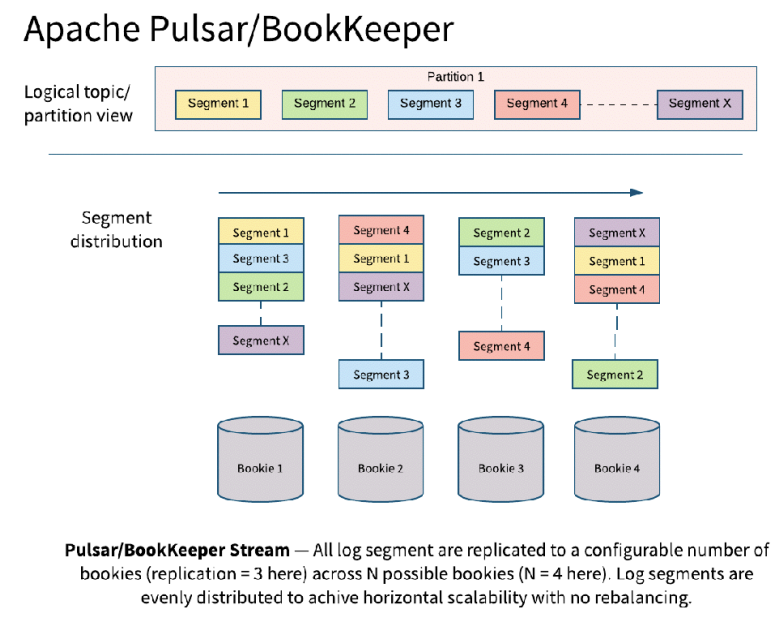
El almacenamiento.
Una de las características que definen a Pulsar es el uso de la entidad denominada segmento, donde entra Apache BookKeeper.

La idea es evitar ciertos problemas de procesamiento, escalabilidad que podrían plantearse con los logs y las particiones. Para ello, se generan logs más pequeños que se denominan segmentos, con las propiedades de un log, y se añade un nivel lógico de gestión, que permite realizar acciones de reparto, escalado y procesamiento, los denominados managed ledgers, que siguen logs.
Aquí atentos a la terminología porque entramos en terreno pantanoso. Para las acciones "garantía de correcto uso" usando un modelo WAL, se aplican ya múltiples palabras, que sí acordaremos representan el mismo concepto, aunque siempre aparecerán las sutilezas en función de si nos movemos con sistemas de ficheros, base de datos, etc., managed legders vamos a verlos como los "gestores" de otros legders (veámolo como un meta log de logs que tiene a su vez las propiedades de un log-WAL). Las traducciones, registro mayor, lo que sea, vamos a ver un WAL como {journal, log, ledger}. El que se aburra, que traduzca el libro:
Con los segmentos se resuelven muchos problemas, los mensajes de las particiones sí se reparten de manera razonable entre los bookies en el clúster (almacenamiento y procesamiento) y se pueden escalar sin dificultad en múltiples escenarios.
La ejecución.

En Yahoo!Japan determinaron que requerían de unos mecanismos de ejecución basados en:
- Las necesidades de ejecución, sobre todo transformaciones, que son la mayoría, suelen ser relativamente simples, procesos ETL de clasificaciones, agregaciones, también mucho routing de eventos entre servicios, etc.
- En esos momentos, se empezaba a hablar del Serverless, ejecuciones por eventos, API de funciones simples, "composición" de API para elementos complejos, input/output/logs como topics, aplicaciones standalone contra servicios manejados ...
Por ello, apoyándose en el uso de Apache OpenWhisk como FAAS, dotaron de esas capacidades de ejecución a Pulsar, tanto en las capacidades de procesamiento basado en eventos,
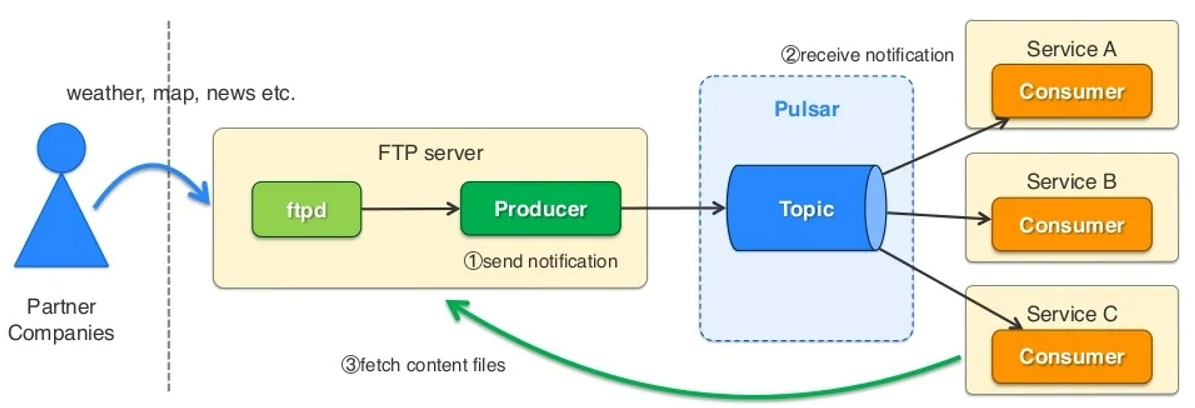
como en la necesidad de ejecutar pipelines,
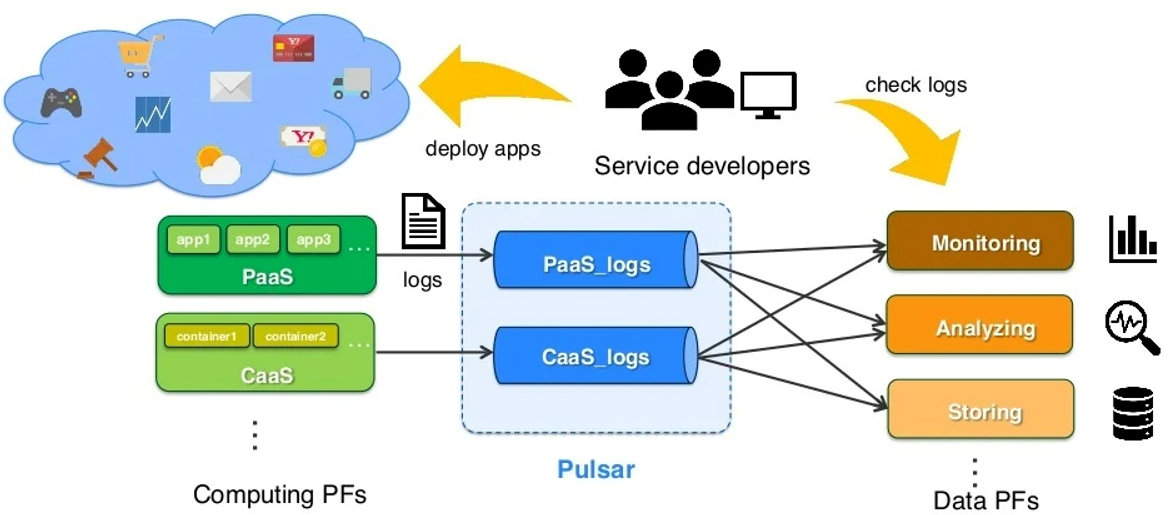
siendo la resultante, la capacidad de construir modelos que actúen bajo la definición de funciones:
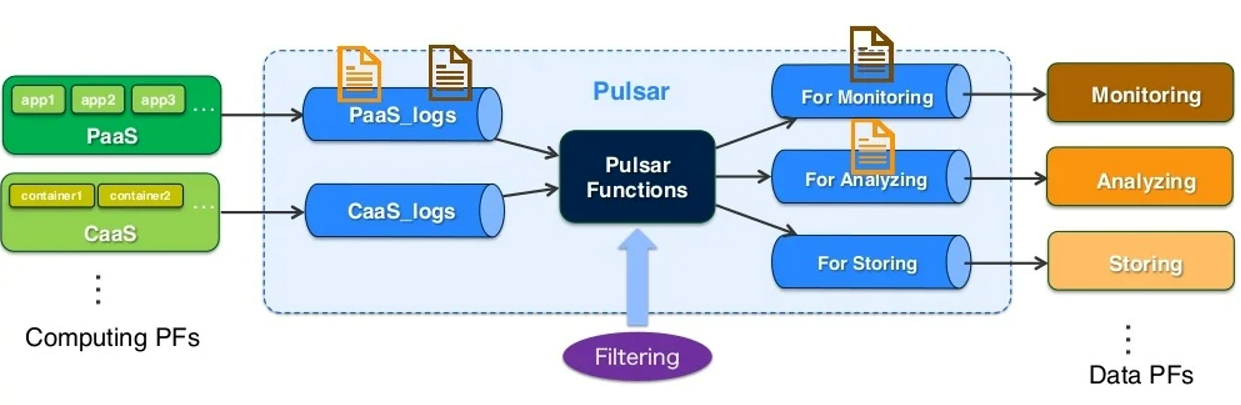
La programación de estas funciones se realiza a través de un SDK, por ejemplo, el propio de Java, bien a través de librerías propias de Pulsar o también mediante Spring Cloud/Integrations.

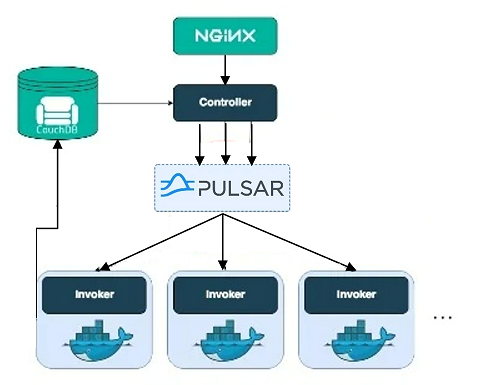
También se pueden usar funciones para invocar a los microservicios contenerizados,
Conclusiones y finalizando.
Presentado Apache Pulsar, una alternativa de mensajería de muy alta prestaciones, plataforma Open Source, amplias capacidades de procesamiento de mensajes y almacenamiento, escalable, multitenant, con operativa probada de geo-replicación y capacidades de ejecución mediante funciones.
Si te ha gustado, ¡síguenos en Twitter para estar al día de próximos posts!
