1. Introducción
Recientemente he tenido la oportunidad de realizar una batería de pruebas comparativas entre dos entornos similares creados para tal propósito. Un entorno se basaría en el sistema operativo Windows y el otro entorno tendría la misma especificación en cuanto a recursos asignados, pero se instalaría RedHat Linux como sistema operativo.

Para este ejercicio se diseñó una batería de pruebas de carga y se ejecutaron las mismas en ambos entornos, ofreciendo de este modo una línea base de rendimiento y, al mismo tiempo, una sólida base en cuanto al tipo de entorno a utilizar para la mensajería de cualquier cliente.
La infraestructura provista para estas pruebas fue:
- Windows: 2 x 2vcpu + 8GB RAM instancias en AZURE con Windows Server 2016
- Linux: 2 x 2vcpu + 8GB RAM instancias en AZURE con RHEL 7.1
La versión de Erlang usada fue 20.3 y RabbitMQ se configuró con versión 3.7.4.
2. Objetivo
El objetivo es la obtención de resultados de las pruebas de carga y su comparación. Ésta permitirá la toma de una decisión informada acerca de la infraestructura y el número de nodos a emplear en el sistema de mensajería y, al mismo tiempo, decidir el sistema operativo adecuado para obtener los resultados de rendimiento deseados en fase de producción.
3. Realización de pruebas
3.1 Herramienta
La herramienta a utilizar, tal y como se cita en la documentación de RabbitMQ, será PerfTest.
PerfTest es la herramienta de carga de RabbitMQ, y se basa en un cliente de Java que se puede configurar para pruebas tanto sencillas como complejas de carga y rendimiento.
Para poder visualizar de modo gráfico el resultado de las pruebas de rendimiento, se utilizará una extensión de HTML que por medio de JavaScript se encarga de plasmar la volumetría obtenida en gráficas de una página de web.
3.2 Estrategia de pruebas de carga
En total se crearon dieciséis ficheros de pruebas para ser utilizados por las herramientas descritas en la sección anterior como pruebas secuenciales. Los ficheros se denominaron spec-file< n >_< l >.js tal y como se indica en las instrucciones de la herramienta.
En estos ficheros se han utilizado un número de parámetros para cubrir un abanico de escenarios que puedan acercarse a la utilización real del sistema de mensajería.
{ 'name': 'Test1', 'type': 'simple', 'uri': 'amqp://<user>:<password>@<node_fqdn_string>', 'params':[{ 'time-limit': 60, 'producer-count': 1, 'consumer-count': 1, 'producer-rate-limit': 1000, 'min-msg-size':64, 'queue-names':['test1'] }] },
Además de las pruebas secuenciales arriba descritas, se creó otro tipo de fichero usando parámetros variables tal y como se describe en el uso de la extensión HTML en su página de GitHub (véase la sección de referencias).
Las subsecciones 3.2.6 en adelante listan la sintaxis y el uso de cada parámetro, siendo muy descriptivas.
[ {'name': 'no-ack', 'type': 'simple', 'uri': 'amqp://<user>:<password>@<node_fqdn_string>', 'params': [{ 'time-limit': 30 }] }, {'name': 'message-sizes-and-producers', 'type': 'varying', 'uri': 'amqp://<user>:<password>@<node_fqdn_string>', 'params': [{'time-limit': 30, 'consumer-count': 0}], 'variables': [{'name': 'min-msg-size', 'values': [0, 64, 128, 1024, 1024000]}, {'name': 'producer-count', 'values': [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]}] }, {'name': 'message-sizes-large', 'type': 'varying', 'uri': 'amqp://<user>:<password>@<node_fqdn_string>', 'params': [{'time-limit': 30}], 'variables': [{'name': 'min-msg-size', 'values': [10000, 64000, 128000, 256000, 512000, 1024000]}] }, {'name': 'rate-vs-latency', 'type': 'rate-vs-latency', 'uri': 'amqp://<user>:<password>@<node_fqdn_string>', 'params': [{'time-limit': 30}]}]
3.2.1 Periodo de prueba
El periodo de duración de la prueba se ha variado en días alternos. Mientras que un periodo de 1 minuto (60 segundos) ofrece la posibilidad de completar el test sin saturar RabbitMQ, el periodo inicial de 3 minutos consecutivos (180 segundos) sobrecargó el sistema de mensajería primero (en Windows) y llegó a provocar el reinicio de uno de los servidores configurado como master del cluster en el entorno Windows, dada la falta de recursos.
Con el fin de completar el máximo número de pruebas, se rebajó de nuevo el tiempo límite del test y se configuró a 60 segundos.
Asimismo como se explica a continuación en la sección 3.2.3, se variaron algunos parámetros para permitir que las pruebas fuesen más completas.
3.2.2 Número de productores y consumidores.
Los ficheros de la serie primera spec-file1_< l >.js contienen tests que se llevan a cabo tan solo por un productor y un consumidor.
De igual forma, los ficheros de la serie segunda spec-file2_< l >.js contienen dos productores y dos consumidores. Este test se presupone como el más parecido a lo que se pueda encontrar en los entornos de producción, donde cada servicio (por necesidades de redundancia) contará con al menos dos productores y también dos consumidores.
La serie tercera contendrá tres productores y consumidores , la cuarta cuatro, etcétera.
3.2.3 Tasa de producción
En cada sección del fichero (de los tests 1 al 10) se incrementa el número de mensajes por segundo en mil unidades (e.g. test1 = 1000, test2 = 2000, test3 = 3000, etc hasta llegar al test 10, con 10000 mensajes por segundo).
Es importante notar que en los ficheros en los que hay más de un productor, la tasa de producción se aplica a cada uno de los productores en hilos distintos de la aplicación. Por lo tanto, la carga es simultánea y concurrente.
Dados los problemas que se experimentaron durante pruebas preliminares en el cluster de Windows, se decidió recortar la tasa de producción para facilitar que el número de pruebas completas fuese mayor. Una vez la tasa se recortó se aplicó el mismo valor para las pruebas en Linux.
3.2.4 Tamaño mínimo del mensaje
Mientras que un test sencillo realizado con la herramienta envió hasta 29000 mensajes por segundo al cluster de RabbitMQ, este tipo de test no es en ningún modo relevante.
Las pruebas se configuraron para enviar mensajes de 0b, 64b, 128b y 1024bs y 1MB.
Las pruebas mixtas se hicieron con mensajes de mayor tamaño como se puede apreciar en el snippet de código que hay arriba.
Si bien los mensajes de tamaño 0b no son muy significativos, sí que sirven para determinar la latencia del sistema de mensajería. Aunque hubiese sido más productivo si se pudiesen haber configurado las opciones del encabezamiento del mensaje, introducir este tipo de variables hubiese extendido la duración de las pruebas demasiado.
3.2.5 Nombre de las colas
Las colas se han nombrado siguiendo el mismo nombre que la prueba de la que formaba parte. Se hizo de este modo para comprobar que cuando el test terminaba, la cola desaparecía.
3.2.6 Parámetros
Los parámetros son completamente configurables. En este caso se han tomado los de la herramienta por defecto para tener una prueba estándar. Estos parámetros determinan el tipo de colección de datos y la gráfica resultante de las pruebas
3.2.7 Variables y valores
Dado que las pruebas se basan en ficheros JSON (JavaScript Object Notation), las variables de declaran por pares, siendo un campo el nombre de la variable que se va a utilizar (en este caso a recolectar) y el otro el valor de esa variable. En estas pruebas se juega con el tamaño de los mensajes y el número de productores.
3.3 Resultados de pruebas de carga
3.3.1 Entornos Windows
3.3.1.1 Prueba 1a – 1 productor y hasta 10000 mps de tamaño 0 bytes
Los entornos Windows se crearon dentro del marco de Active Directory, por lo tanto, ambas instancias en Azure tuvieron su nombre añadido al DNS. Esto facilitó la configuración en cluster y que ambas instancias se reconociesen entre ellas.
Primero se aplicaron las pruebas secuenciales (tal y como se aprecia en la siguiente ilustración). El primer test se realizó con mensajes vacíos (mínimum message size = 0) y con acuse de recibo.
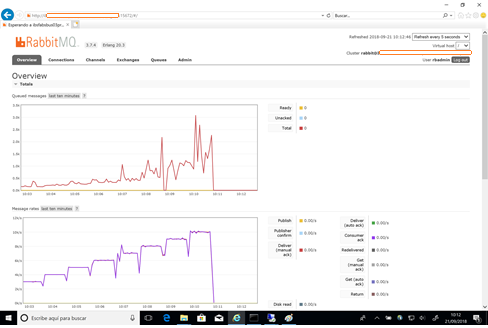
Fig1 Gráfica de RabbitMQ - Prueba 1a
La gráfica en escalera se corresponde con el número de mensajes emitidos un único productor en cada prueba (de 1 a 10 productores enviaron hasta 10000 mensajes simultáneos).
En la gráfica superior se aprecia que el número de mensajes almacenados en cola tuvo su pico en algo más de 3000 mensajes.
Mientras que esta prueba se completó correctamente, la infraestructura se encontró desahogada en ambos nodos, aunque se empezó a notar el alto volumen de uso de los procesadores hacia el final de la prueba.
Otro detalle significativo es que ambas instancias se configuraron como nodos con persistencia disco. En la ilustración se aprecian ya periodos en los cuales la actividad del disco alcanza el 100%. En esta segunda instancia la carga general del disco es menor, ya que tan solo se lleva a cabo la replicación.
La actividad de red es también menor en la réplica.
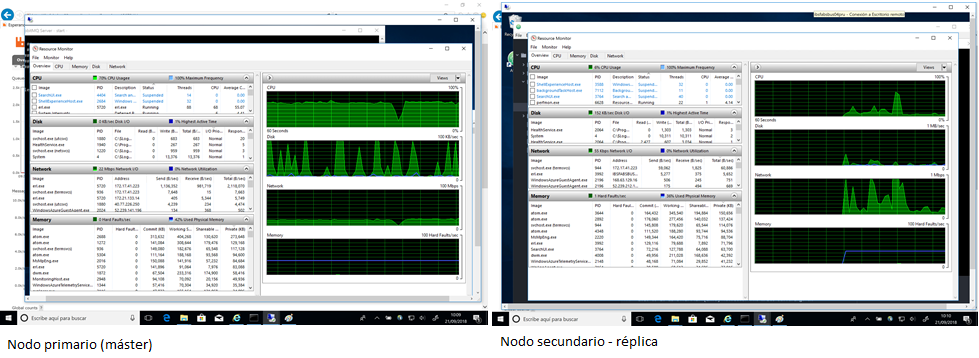
Fig2 - Recursos de los nodos durante Prueba 1a
3.3.1.2 Prueba 1b – 1 productor y hasta 10000 mps de tamaño 64 bytes
Los resultados de la prueba 1b, en la cual la única variación fue el tamaño de los mensajes de 0 bytes a 64 bytes (el tamaño de una oración simple) fueron significativos.
La producción de diez mil mensajes simultáneos ocasionó errores en la prueba que terminó con errores Java de conexión al cluster.
Aun así, se llegaron a alcanzar diez mil mensajes por segundo. Debido al error, más de doce mil mensajes no fueron consumidos y se quedaron almacenados en RabbitMQ a la espera de un consumidor.
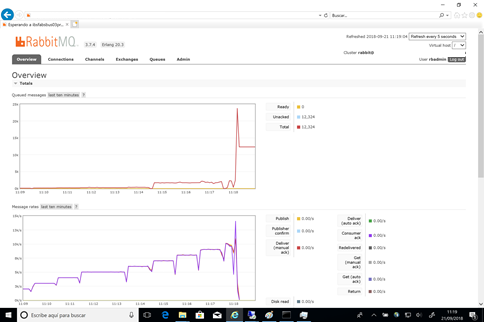
Fig3 - Gráfica RabbitMQ - Prueba 1b
En la infraestructura se pudieron apreciar ya un consumo de procesador sostenido y un mayor uso de la red para la transmisión de datos. Ello se debe, en el nodo primario, al tráfico generado por la prueba más la replicación con el secundario.
En el nodo replicado, el consumo de procesador fue nominal, mientras el uso de disco duro y red replica (en menor medida) el del primario.
3.3.1.3 Prueba 1c – 1 productor y hasta 10000 mps de tamaño 128 bytes
Esta prueba no llegó a completarse correctamente en ninguna de las ocasiones en las que se intentó. Como se puede apreciar en la siguiente ilustración, durante el test 8 (de 8000 mensajes por segundo), el servidor de RabbitMQ dejó de procesar mensajes correctamente y estos comenzaron a almacenarse (hasta llegar a un total de 215000 mensajes almacenados esperando un consumidor).
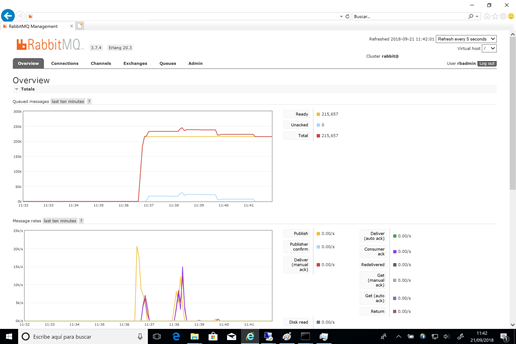
Fig4 - Gráfica RabbitMQ - Prueba 1c
Durante esta prueba, el consumo de recursos de ambos nodos no se pudo capturar debido a problemas de conectividad con ambas instancias en Azure. A pesar de haber problemas de acceso a las instancias, la salud del cluster permaneció estable durante todo el test, sin encontrar ningún problema de partición de red (evento durante el cual ambos miembros del cluster pierden conectividad y el cluster se disocia – también conocido como Split-brain cluster).
3.3.1.4 Prueba 1d – 1 productor y hasta 10000 mps de tamaño 1 Kbyte
La prueba 1d, con un tamaño mayor de mensaje, no llegó a completar más que hasta el test 2 (envío de 2000 mensajes por segundo) antes de comenzar a dar fallos. Falta de conectividad no permitió sacar pantallas de la aplicación (el servidor de web interno perdió conectividad con la aplicación).
Tampoco fue posible conectar al nodo primario para tomar detalles de los recursos consumidos hacia el final de la prueba. Se apreció que RabbitMQ consumía una media del 34% del procesamiento, 30% de la capacidad de red y 30% de la memoria total disponible.
3.3.1.5 Pruebas 2 - 2 productores y hasta 10000 mps
En general, con todos los ficheros de pruebas de tipo 2 (2 productores y 2 consumidores) de mensajes se apreció una degradación del rendimiento. El incremento del número de hilos (threads) de aplicación, afectó a RabbitMQ especialmente a la hora de consumir mensajes (incluso cuando el tamaño de mensaje fue 0bytes). Durante el test 2, RabbitMQ llegó a tener almacenados en exceso de 250.000 mensajes mientras que los productores no tuvieron la consistencia debida, dados los errores de conexión a los sockets de la aplicación.
Después de vaciar las colas y dar unos minutos de reposo, RabbitMQ fue capaz de procesar un máximo de 10.000 mensajes por segundo durante unos minutos.
El mejor rendimiento con dos productores se obtuvo con mensajes de 128bytes, durante esta prueba se alcanzó una tasa sostenida de 8000 mensajes por segundo.
El rendimiento de mensajes de 1kb no llegó a exceder 5k mensajes por segundo.
En cuanto a carga en los servidores virtuales, tampoco fue consistente. Mientras algunas pruebas hicieron un uso mayor de procesador (hasta 55% de media), otras tuvieron el I/O del disco como factor limitante.
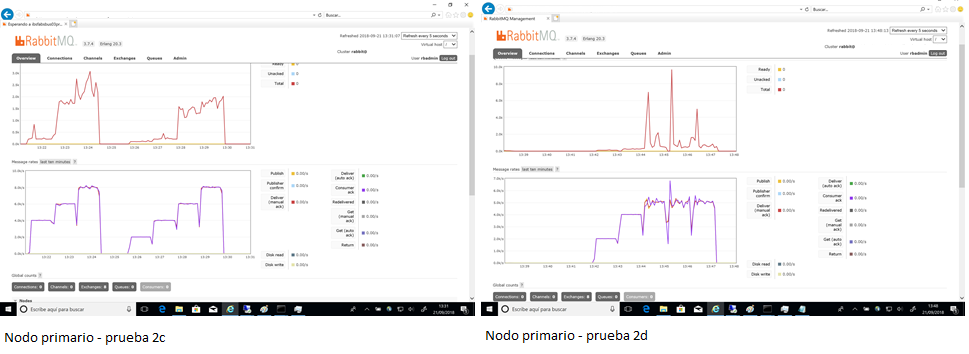
Fig5 - Pruebas 2c y 2d en Windows
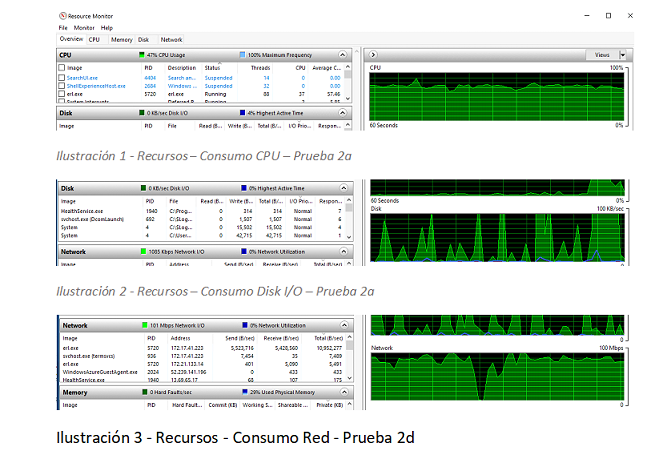
Fig6 - Recursos nodos durante Pruebas serie 2
Un tamaño de mensaje mayor utilizó mayor cantidad de red (transacciones y replicado).
En líneas generales, no se apreció un mayor consumo de RAM al incrementar los mensajes y su volumen. Sin embargo, sí que se experimentaron mayores periodos de falta de conectividad al nodo primario durante la serie de Pruebas 2.
3.3.1.6 Pruebas 3 - 3 productores y hasta 10000 mps
Los mismos problemas encontrados durante la serie dos, se repitieron en mayor medida en la serie 3 dado que el incremento del número de productores y consumidores causó una vez más, problemas de conectividad. Las pruebas comenzaron a ser irregulares a partir de los 4000 mps (mensajes por segundo) y nunca llegaron a terminar por completo. El cliente Java de PerfTest empezaría a experimentar falta de conexión, y finalmente errores de timeout y de acceso a sockets de aplicación, con lo cual el cliente fallaría con errores fatales.
Durante esta prueba, con 3 productores y hasta 4000mps (mensajes por segundo), la tasa de mensajes de entrada fue de 11,938/s. Muy cerca de la nominal esperada (12k), sin embargo, el cluster tardó unos 10 minutos en recuperar la conexión de nuevo. Para entonces, el cliente de Java había fallado con error fatal y el ejercicio no completó.
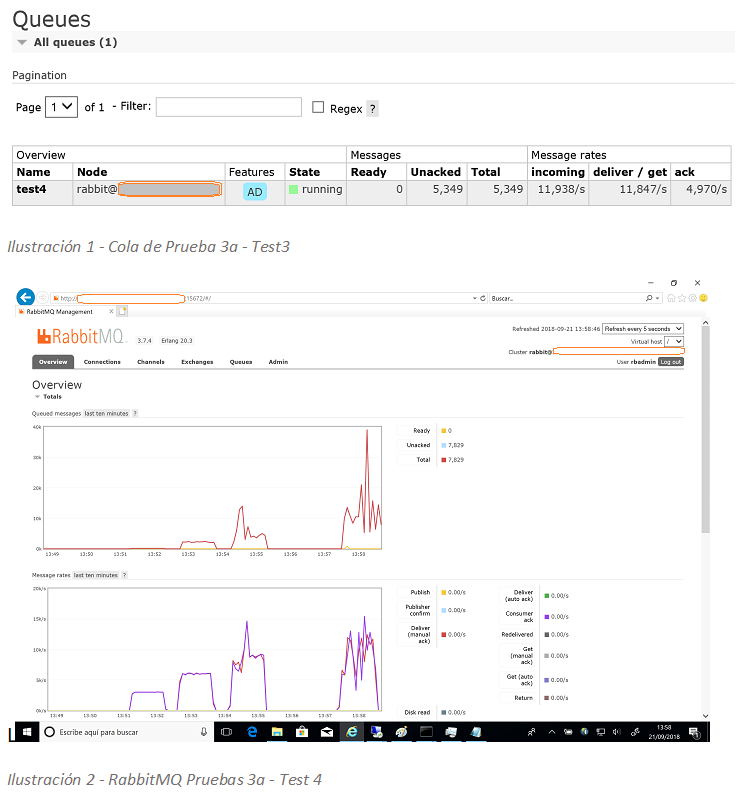
Fig7 - Cola de Prueba 3a - Test3
Lo mismo sucedió en la prueba 5, tras la cual PerfTest falló por completo. La cola no llegó a drenarse y tuvo que ser purgada manualmente.
Los recursos del nodo primario no se vieron tan afectados como se esperaba en vista de los resultado, salvo el uso del red, que en este caso sí representó la limitación y posiblemente fuese la causa de la partición de red resultante.
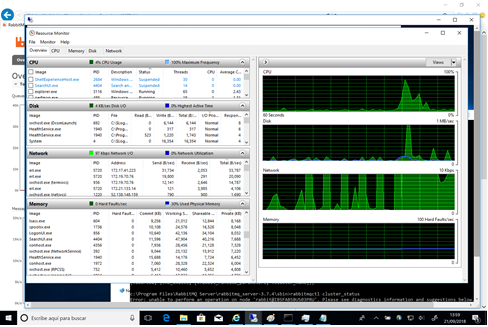
Fig8 - Recursos - Prueba 3a
3.3.1.7 Pruebas 4 - 4 productores y hasta 10000 mps
Ninguna de las pruebas de la serie 4 llegó a completarse. Al fallar la aplicación cliente, Java no llegó a registrar ningún dato en las ocasiones en las que se intentó. El uso de cuatro productores y consumidores saturó los recursos de las instancias. El servicio RabbitMQ dejó de funcionar y se paró causando corrupción en Mnesia que hubo que solventar por medio de un reinicio limpio del servicio. En caso de uso en producción, este evento hubiese ocasionado pérdidas de mensajes.
3.3.1.8 Pruebas mixtas
Estas pruebas tampoco llegaron a completarse, aunque esta vez, el cliente sí consiguió registrar algunos datos. El mayor volumen de mensajes alcanzado superó los 50.000 mps, y los recursos del nodo primario no parecieron estresados en ningún momento.
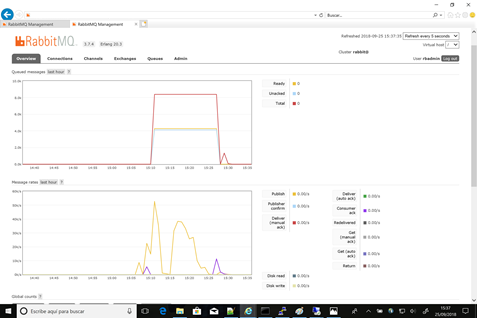
Fig9 - Pruebas varias - Test 3
3.3.2 Entornos Linux
3.3.2.1 Prueba 1a – 1 productor y hasta 10000 mps de tamaño 0 bytes
Las primeras pruebas en Linux completaron sin problemas, aunque no de un modo tan “limpio” como lo hicieron las de Windows. El arranque de cada prueba en la serie provoca un incremento del número de mensajes inicial antes de estabilizarse. Se aprecia un mayor consumo entre el final de una prueba en la serie y la siguiente.
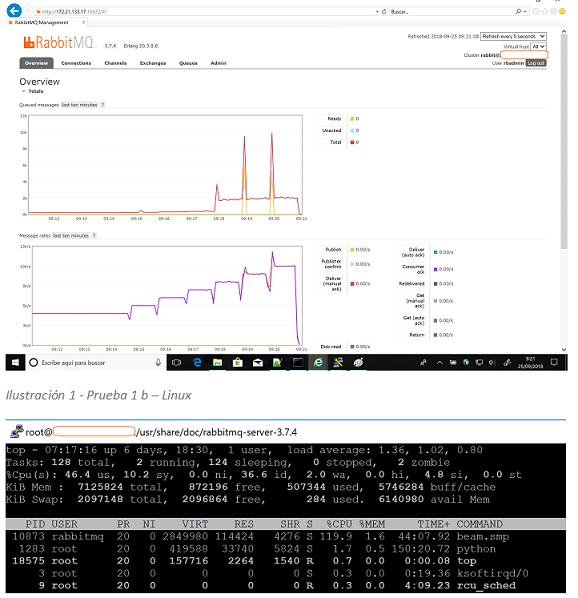
Fig10 - Prueba 1a Linux
3.3.2.2 Prueba 1b – 1 productor y hasta 10000 mps de tamaño 64 bytes
El script del cliente Java pareció quedarse trabado durante la ejecución de esta prueba. Sin embargo, la duración extendida no afectó el número de mensajes en cola que salvo en periodos de cambio de prueba incrementaron dramáticamente antes de ser consumidos.
El nodo pimario empezó a consumir procesador durante esta prueba. Dado que las instancias se hospedan en Azure y su configuración es elástica, se consumen más de 100% del procesador asignado.
3.3.2.3 Prueba 1c – 1 productor y hasta 10000 mps de tamaño 128 bytes
Durante esta prueba, al llegar a 8000 mensajes por segundo, se produjo un problema de conexión en el servidor. En ese momento, comienza un almacenamiento de mensajes que llega a alcanzar más 360.000 mensajes. En el momento del problema, el servidor no se encuentra estresado en exceso. A pesar de este error de conexión, la prueba continuó y acabó (si bien el consumidor de la cola test8 no llegó a consumir los mensajes almacenados).
3.3.2.4 Prueba 1d – 1 productor y hasta 10000 mps de tamaño 1 Kbyte
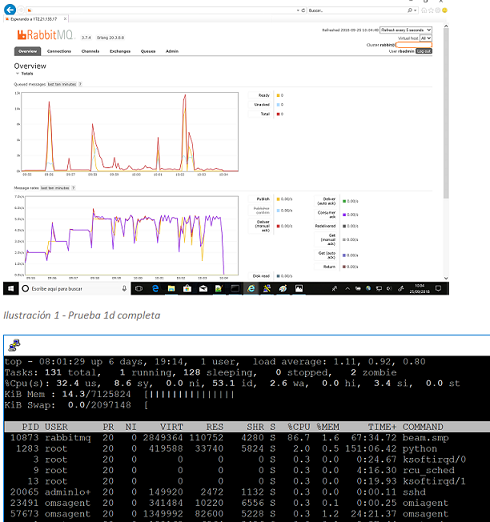
Fig11 - Prueba 1d Linux
Al contrario del rendimiento obtenido en Windows, en cuyo entorno esta prueba con mensajes no se llegó a completar en ninguna de las ocasiones en las que se intentó, la prueba sí acabó en Linux, con un rendimiento menor de lo esperado de tan sólo 5000 mensajes por segundo, pero una media sostenida, tal y como se aprecia en la figura 11 (arriba).
La carga del servidor es nominal, al haber un menor número de mensajes procesados debido al tamaño de los mismos, se causa un menor uso del procesador y un ligero incremento del uso de memoria.
3.3.2.5 Pruebas 2 – 2 productores y hasta 10000 mps
Las pruebas de la serie 2 sin carga (2a) no llegaron a completar correctamente a partir de 8000 mensajes por productor. Sin embargo, se llegaron a alcanzar en exceso de los 16.000 mensajes esperados, aunque no fuese de una manera sostenida.
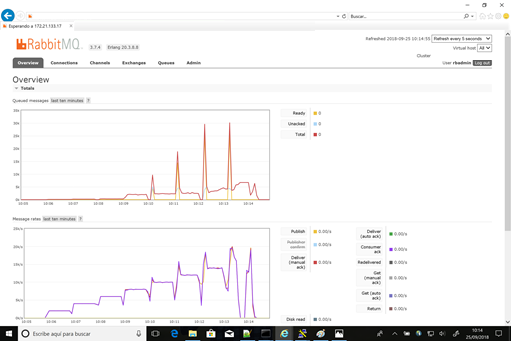
Fig12 - Prueba 2a - Test 8
En cuanto a los recursos del nodo primario durante la prueba se el consumo de procesador, que incrementa de 147% a 159% progresivamente con la ejecución de cada prueba (consumo elástico de los recursos de Azure, en una instalación on-premise, el procesador alcanzaría el 100% de recursos). El uso de memoria es nominal.
La Prueba 2b se ejecutó con los mismos parámetros que en Windows, es decir, llegando tan sólo hasta el Test 8 de 8000 mps, y completó sin errores.
También se completaron las pruebas 2c y 2d con los mismos parámetros que en Windows (es decir, reducidas en número de mensajes por segundo para evitar que el cliente Java se cayese). Con mensajes de 128 bytes, el cluster en Linux llegó a sostener 10.000 mensajes por segundo. La prueba 2d (mensajes de 1Kb) completó con una media cercana a 5000 mensajes por segundo incluso cuando se perdió conexión momentáneamente durante la ejecución. También esta prueba se aplicó del mismo modo que en Windows, es decir, con el número de mensajes por segundo limitados para permitir su ejecución sin problemas del cliente Java.
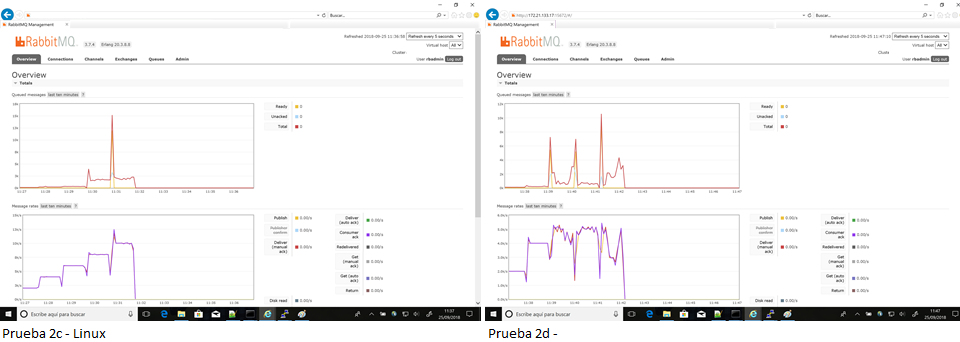
Fig13 - Pruebas 2c y 2d en Linux – Completa
3.3.2.6 Pruebas 3 – 3 productores y hasta 10000 mps
En conjunto, todas las pruebas realizadas con 3 productores concurrentes completaron sin experimentar el tipo de problemas de conexión que se encontraron en el cluster de Windows.
La prueba 3a llegó a alcanzar una carga de 15.000 mensajes por segundo, mientras que en las pruebas siguientes fueron variadas. En la prueba 3b hasta la prueba 8 se mantuvo el rendimiento de 15.000 mensajes, sin embargo, en la prueba 9 el rendimiento cayó a tan sólo 100 mensajes por segundo.
De un modo similar, las pruebas 3c llegaron a superar 15.000 mps aunque de un modo algo irregular. Las pruebas 3d fueron consistentes, pero con mensajes de 1Kb tan sólo se llegó a mantener un rendimiento de 5000 mps.
Mientras las pruebas 3b, c y d nunca llegaron a completar en Windows, todas terminaron en Linux, aunque el rendimiento de la mensajería varió dentro de una misma prueba (e.g. 15.000 mps en test 9 y tan sólo 100mps en test 10).
Es de notar que en ningún momento, a pesar de que el procesamiento excedió los límites físicos, nunca llegó a sobrepasar el 180% en ninguna de las pruebas.
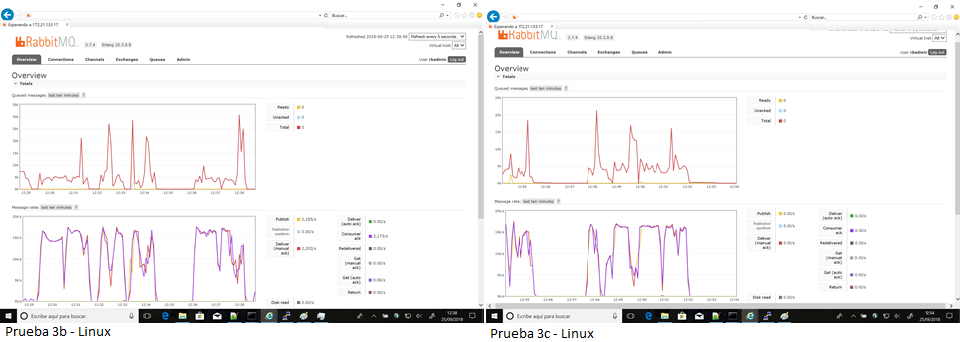
Fig14 - Pruebas 3b y 3c en Linux - Completas
3.3.2.7 Pruebas 4 – 4 productores y hasta 10000 mps
Al igual que en el cluster de Windows, el aumento de productores y consumidores hasta 4 causó algunos problemas con la ejecución de las pruebas.
Aun así, la pruebas 4a llegó a completar todos los pasos y en 4b llegaron a completarse cuatro de ellas tal y como se muestra en los gráficos a continuación.
En la prueba 4a se llegó a alcanzar un rendimiento de 17.000 mps en las últimas fases (debieran haber sido 40k mps dado que los 4 productores tenían como límite 10k mps).
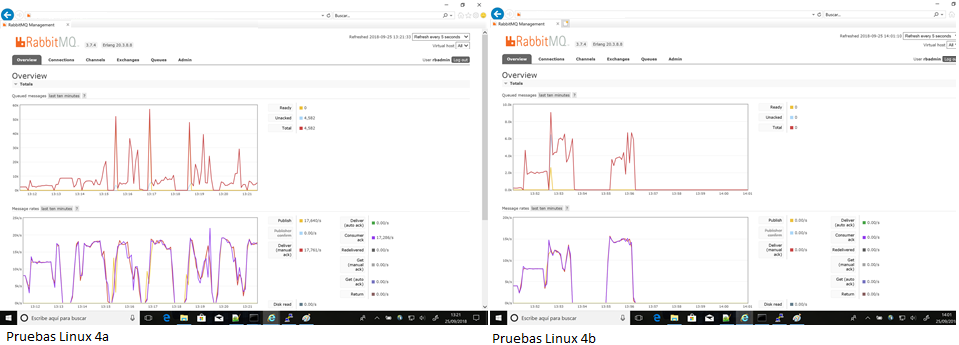
Fig15 - Pruebas 4a y 4b en Linux - Completas
En la prueba 4b, durante el test 4, se alcanzaron 15k mps.
Estas pruebas también fueron modificadas con respecto a las originales para permitir que acabasen en el entorno de Windows. Mientras que en Windows no completaron, en Linux lo hicieron, aunque con un rendimiento menor del esperado.
3.3.2.8 Pruebas mixtas
La ejecución de las pruebas mixtas llegó a completar en Linux y los resultados se pudieron salvar a un archivo para su posterior utilización.
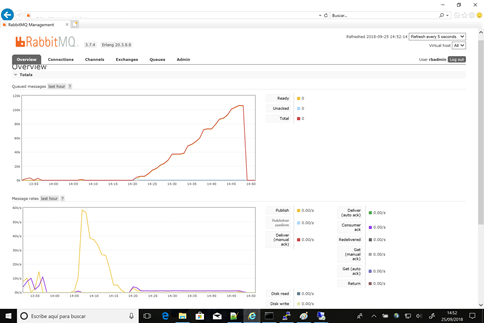
Fig16 - Pruebas mixtas - Ventana 1 hora
Tal y como se puede apreciar en la ilustración 16 (arriba), la ejecución del script de pruebas llevó 45 minutos (aproximadamente) y durante ésta, el número de mensajes de prueba se incrementó hasta llegar a un total de más de 100.000 mensajes que fueron finalmente consumidos.
En cuanto al máximo número de mensajes que el cluster pudo procesar (mensajes de carga nominal 64b y sin acuse de recibo), el entorno Linux alcanzó 57.000 mps comparado con los 50.000 de Windows.
Durante esta prueba, el número de mensajes publicados es ligeramente mayor que el de mensajes consumidos, lo que ocasiona un aumento progresivo de mensajes almacenados en la cola. Una vez que los productores dejaron de emitir, los mensajes se consumen rápidamente y la cola se drenó por completo en menos de un minuto.
En vista de que el rendimiento de los servidores del cluster Linux fue más fiable que el del entorno Windows, se intentaron algunas pruebas tal y como se esperaban haber realizado inicialmente, con mensajes de 1Mb.
En estas pruebas el rendimiento cayó a 5 mensajes por segundo. Si bien los servidores no se estresaron, no está claro si la sobrecarga se debe al cliente Java (ejecutando en el Tablet), o bien a RabbitMQ.
3.3.2.9 Prueba Mixta HiPe Compiler – 1 – Sin replicación
La precompilación HiPe se recomienda en la página de RabbitMQ para obtener un beneficio de rendimiento de entre el 20 y el 50%. Esta precompilación no se puede ejecutar en el entorno de Windows.
La compilación se inició en el subdirectorio de RabbitMQ. Hipe compiló 57 carpetas en un total de 74 segundos. Se reinició el servicio RabbitMQ en ambos nodos del cluster y se intentó el arranque de las pruebas mixtas.
Como se puede apreciar, cuanto mayor es el tamaño del mensaje, menor es el rendimiento en cuanto a mensajes por segundo. El incremento de mensaje de 0 a 64 bytes ocasiona una bajada de 20.000 mps. En comparación, el tamaño idóneo para obtener un compromiso tamaño / velocidad es 128 bytes, ya que se pueden llegar a alcanzar velocidades de hasta 30.000 mps.
Mensajes de 1mb (como podrían ser escaneos de fotos de ID o imágenes de similar tamaño) alcanzan 5mps, como se vió durante las pruebas manuales. Este tamaño se puede ver en la base del diagrama superior.
Sabiendo que RabbitMQ define latencia como el tiempo que tarda un mensaje en ser recibido, es importante señalar que en las pruebas mixtas sin replicación, la latencia permanece estable sin importar el número de mensajes que se envían.
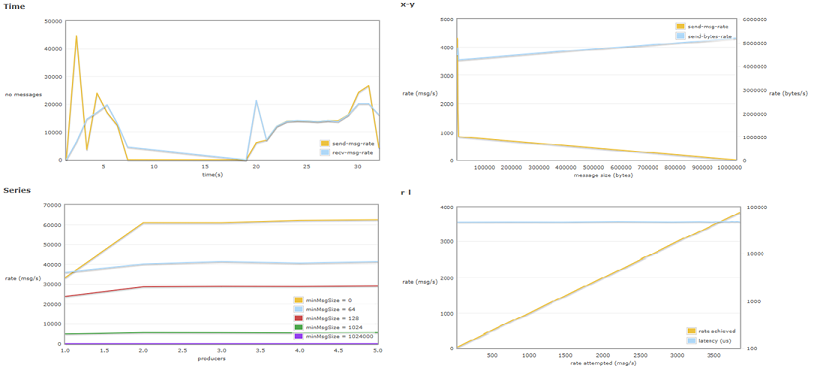
Fig17 - Pruebas mixtas - HiPe Compiler activado
En la gráfica x-y, se aprecia la existencia de una relación proporcional inversa, como ya se describió en este documento. Cuanto mayor es el tamaño del mensaje, menos mensajes se pueden enviar. La saturación puede ser en ambos sentidos, en recursos de servidor y al mismo tiempo en saturación de red.
3.3.2.10 Prueba Mixta HiPe Compiler – 2 – Replicación de colas
Con el fin de simular por completo el entorno de producción, en el cual se sugiere la replicación de colas e intercambios entro los nodos del cluster, se creó una política de replicado a todas las colas de mensajería denominadas “amq.” ya que ésa es la nomenclatura de colas usada por la herramienta PerfTest.
Una vez que se reinició RabbitMQ en ambos nodos, fue necesario “imprimar” el RabbitMQ por medio de un test sencillo.
Los resultados merman las ganancias obtenidas por la habilitación del Hipe compiler pero otorgan una plena fiabilidad, ya que los mensajes se replican a discos en todos los nodos seleccionados del cluster (en este caso “todos” – 05 y 06 en PRU).
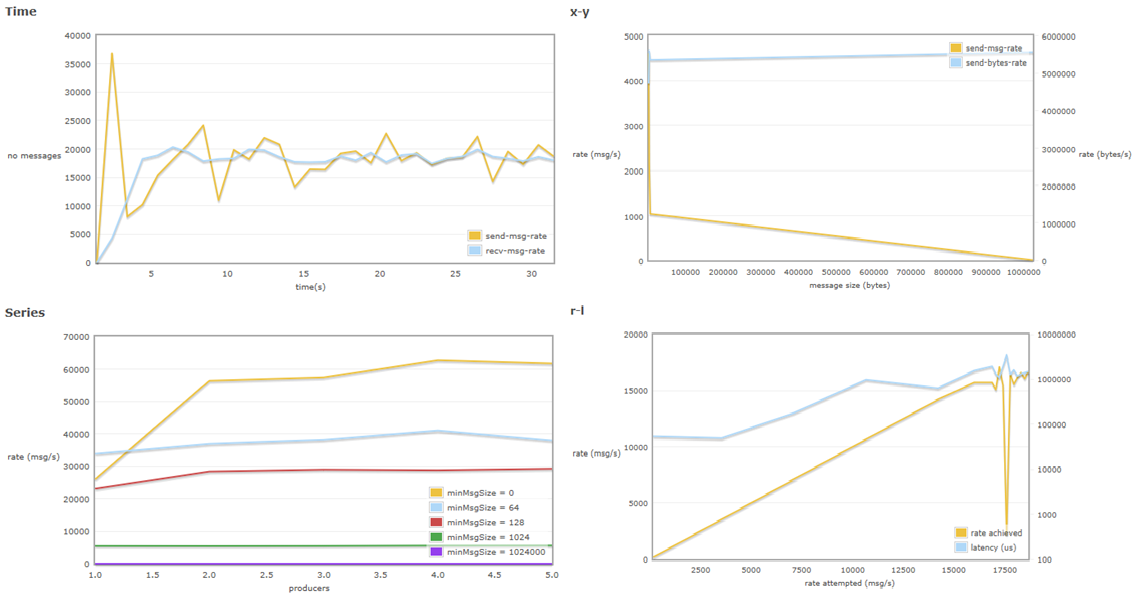
Fig18 - Pruebas Mixta HiPe Compiler - 2 - Replicado
Mientras que la prueba realizada de compilación HiPe en si misma el número de mensajes alcanzaba un pico antes de descender y recuperarse, en este caso, con las colas replicadas, el número de mensajes permanece estable durante la prueba de mensajes vs tiempo. Estos mensajes no están configurados para recibir acuse de recibo. Son puramente de rendimiento (no tanto de carga).
La Serie velocidad de mensajes por número de productores es similar a la obtenida sin replicado de colas.
Mientras que en la gráfica con HiPe pero sin replicación la latencia se mantiene uniforme, una vez que se activa la replicación de colas, se aprecia que la latencia aumenta casi en paralelo al número de mensajes.
3.3.2.11 Prueba Mixta HiPe Compiler – 3 – Cluster Híbrido
Una vez más, con el fin de realizar una prueba en un entorno similar al de producción, pero en menor escala. Se removió el nodo secundario del cluster y se volvió a unir como nodo de RAM. Una vez más con replicado de colas “amq”.
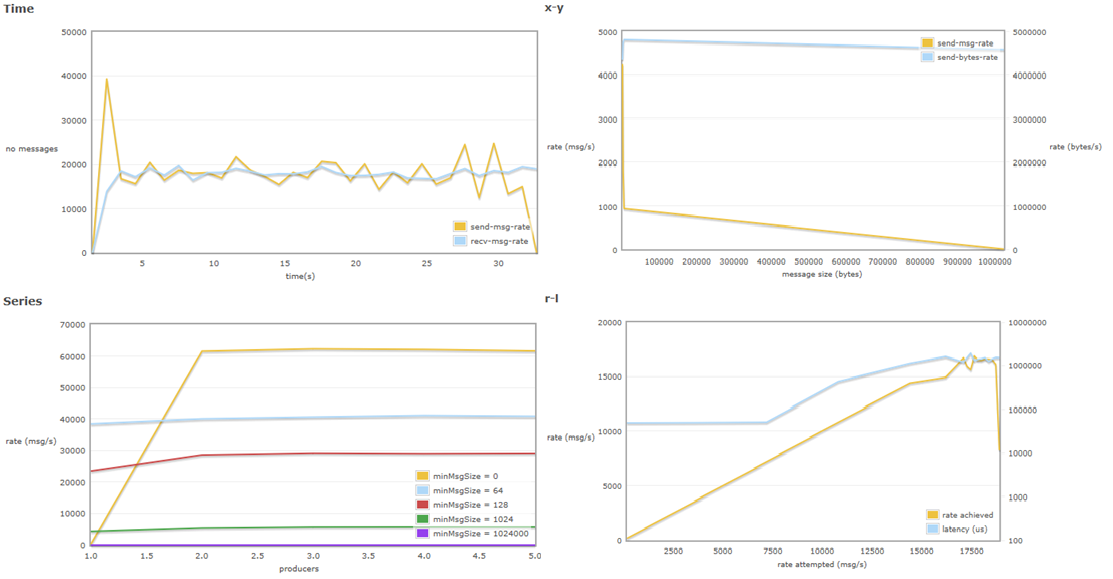
Fig19 - Pruebas mixtas - Hipe Compiler - 3 - Cluster Híbrido
Los resultados en ambas gráficas se parecen a los resultados de ejercicios de pruebas anteriores, si bien el número de mensajes vs tiempo es más estable (con menos picos) que en la versión de pruebas anterior (Hipe habilitado y colas replicadas pero ambos nodos de disco).
Lo mismo que en la gráfica anterior, los resultados son similares, pero más armónicos en apariencia. Ello se debe en parte a que el replicado ocurre en memoria y no en disco, con lo cual no hay demora en la sincronización. En la gráfica superior, se muestra que el número de bytes enviados es ligeramente superior al de la prueba anterior.
Las gráficas de consola de RabbitMQ, tal y como se aprecia en la siguiente imagen, son muy distintas de las obtenidas en previos ejercicios, empezando por la duración. La prueba completa en esta ocasión duró unos 30 minutos, mientras que en previas ocasiones llegó a durar 45.
3.3.3 Comparativa
Mientras que el cluster en entorno Windows no llegó a completar varias de las pruebas debido a errores de conexión y falta de recursos, el cluster en Linux sí que mostró mejor rendimiento en condiciones de conexión múltiple (2, 3 y 4 productores en pruebas secuenciales y hasta 5 en pruebas mixtas), que al mismo tiempo es un elemento diferenciador entre ambas tecnologías.
En mensajes de hasta 128bytes, el cluster de Windows tuvo un rendimiento consistente, pero tan sólo en pruebas de 30 ó 60 segundos. Las pruebas sostenidas de 180 segundos hubieron de descartarse ya que el entorno no aguantó la carga por un tiempo sostenido.
La habilitación del HiPe compiler en Linux ha reducido, en general, el número de mensajes en cola y ha acortado los tiempos de prueba considerablemente, acelerando al mismo tiempo el envío a consumidores.
Otro importante elemento a considerar es que, en toda la fase de pruebas, el cluster de Windows sufrió dos particiones de red que hubieron de subsanarse manualmente. La segunda partición de red ocasionó una corrupción en la base de datos interna usada por RabbitMQ (Mnesia). Este evento hubiese ocasionado pérdida de mensajes en RabbitMQ (no necesariamente en el sistema si los productores no hubiesen recibido acuse de recibo).
Mientras tanto, incluso en aquellas pruebas en las que se ha perdido conectividad a los sistemas Linux, en ningún caso esta perdida ocasionó demoras o funcionamiento erróneo en la aplicación.
En cuanto a la facilidad de administración. La mayor parte de las tareas administrativas se pueden realizar desde el portal web con un usuario que tenga permisos administrativos. Los comandos desde la consola de DOS o BASH son muy similares, variando ligeramente la sintaxis.
El archivo de configuración y el de entorno son idénticos.
3.3.4 Recomendaciones
Las pruebas realizadas en este ejercicio son sintéticas y el tamaño de mensajes está predeterminado a ciertos valores. Por ello, aunque dan una indicación informada acerca del rendimiento que se puede llegar a esperar, no pueden reemplazar la precisión de las pruebas realizadas con los elementos reales en cuanto a productores y consumidores basadas en el tipo de mensaje a enviar.
Las pruebas deberían ser duplicadas con el mismo tipo de mensaje en ambos sistemas mientras se obtienen gráficas desde la consola y se monitorizan el consumo de recursos en la línea de comandos.
4. REFERENCIAS
- RabbitMQ Testeo de carga:
https://www.rabbitmq.com/java-tools.html
https://rabbitmq.github.io/rabbitmq-perf-test/stable/htmlsingle/ - RabbitMQ Monitorización:
https://www.rabbitmq.com/monitoring.html