
Transactional Outbox y Change Data Capture con Debezium y Kafka Connect
Publicado por Manuel García de Vinuesa Gómez el
Arquitectura de SolucionesCDCDebeziumKafka ConnectEDA2PCTransactional
Introducción
Desde hace unos años, las arquitecturas de eventos (EDA) se han ido haciendo un hueco en las arquitecturas empresariales que se nutren de sus múltiples ventajas para ofrecer soluciones que favorezcan la transformación digital de su core de negocio. Pero como cualquier otro paradigma, no está exento de nuevos retos y posibles complicaciones o retos que se deben asumir y solventar.
Citando a un ex-compañero mío:
La complejidad ni se crea ni se destruye, sólo se transforma.

Bromas aparte, lo que viene a decir es que la inclusión de nuevos paradigmas o soluciones no implican directamente la reducción de la complejidad dentro de un sistema, quizás unos se reduzcan y otros nuevos aparezcan, es ahí donde en función de las necesidades de negocio unas arquitecturas pueden encajar perfectamente y otras suponer un auténtico lastre.
Con EDA y el uso de eventos (Event Sourcing), uno de los principales handicaps que aparecen en el desarrollo de aplicaciones es como gestionamos la transaccionabilidad cuando se combina la escritura en base de datos con la emisión de eventos, ya que en muchos casos la atomicidad de la operación va ligada a ambas operaciones, por tanto llega el momento de decidir cual es la "Single Source of Truth" o única fuente de verdad, y no siempre es sencillo.
En este artículo no vamos a profundizar en todas las diferencias, ventajas y desventajas de estas aproximaciones, en cambio, vamos a centrarnos en un caso particular con el patrón Transactional Outbox y Change Data Capture o CDC y cómo usando Debezium y Kafka Connect podemos gestionar nuestros datos y plantear nuestra solución de EDA basándose en eventos generados por el CDC para evitar el dilema que se nos plantea sobre la transaccionabilidad.
¿Qué es el patrón Transactional Outbox?
Es un patrón de arquitectura que se suele aplicar a la hora de evitar que una aplicación "mezcle" llamadas a una BD y emisión de eventos, y a su vez queramos aplicar el concepto de operación atómica sin entrar en soluciones 2PC (Two phase commit) con transacciones distribuidas como XA.
¿Qué ocurriría si una de las dos operaciones falla? ¿Cómo gestionamos un posible rollback? Si hemos emitido el evento, pero falla el commit, ¿cómo recuperamos ese mensaje ya emitido? Este patrón ofrece una solución a este problema.
La solución se basa en que la información que debe mandarse a través de los eventos sea almacenada de manera temporal en otra tabla de la base de datos (outbox table) con el objetivo de aprovechar la transacción asociada a la BD, y un proceso externo se encargue de leer esa información y emitir los eventos correspondientes.
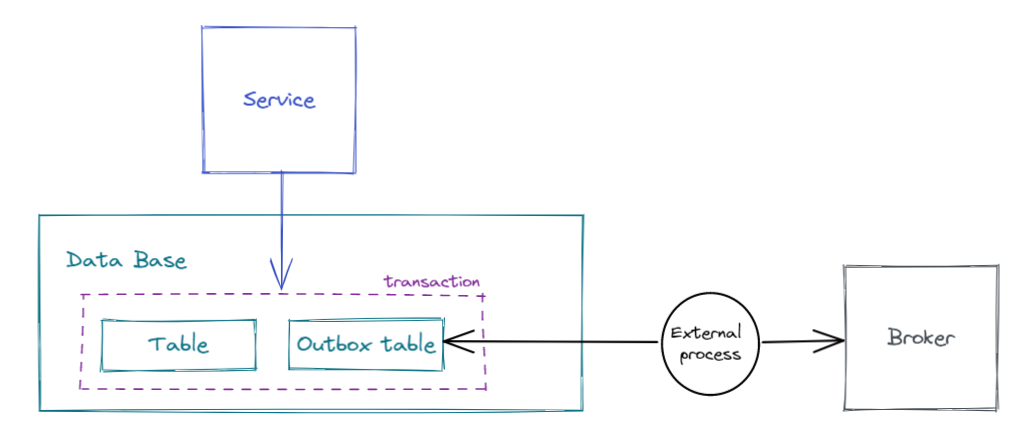
Las ventajas de este patrón son principalmente:
- Evitar el uso de sistemas 2PC
- Asociar la creación del mensaje a enviar a que la transacción de BD termine correctamente (commit).
- En caso de error en escritura (rollback) el mensaje no se guardará en la outbox table y por tanto no se emitirá al exterior.
Por supuesto, no todo son ventajas:
- La solución es más compleja (nueva tabla, change data capture...)
- El proceso de lectura de mensajes debe controlar qué mensajes han sido emitidos y cuales deben emitirse, puede dar lugar a problemas de "more-than-once" si no queremos que sea bloqueante.
¿Qué es Change Data Capture?
Change Data Capture (CDC) es una solución que nos va a permitir capturar los eventos generados por el transaction log de nuestra base datos y emitir esos eventos hacía los distintos flujos de consumición que decidamos.
La mayoría las soluciones de CDC basadas en transaction log (tanto las OpenSource como las que están bajo licencia) y por tanto, necesitan "acoplarse" a este, por tanto dependerá de la base de datos aplicar una u otra solución para conseguir CDC.
Existen otras aproximaciones, pero para no entrar nosotros en detalles os animo a leer este interesante artículo donde se exponen estos matices con mucha mayor claridad de lo que yo lo haría.
Para cada base de datos tendríamos una solución distinta, como por ejemplo en el caso de MySQL ofrece BinLog como solución de CDC, pero podríamos emularlo usando TRIGGERS.
En el caso de DB2 tenemos SQL Replication y por ejemplo en el caso de PostgreSQL Logical Decoding Output plugin
El objetivo en todos estos casos es permitir capturar los cambios y poder emitirlos a un flujo de consumición a través de un CDC.
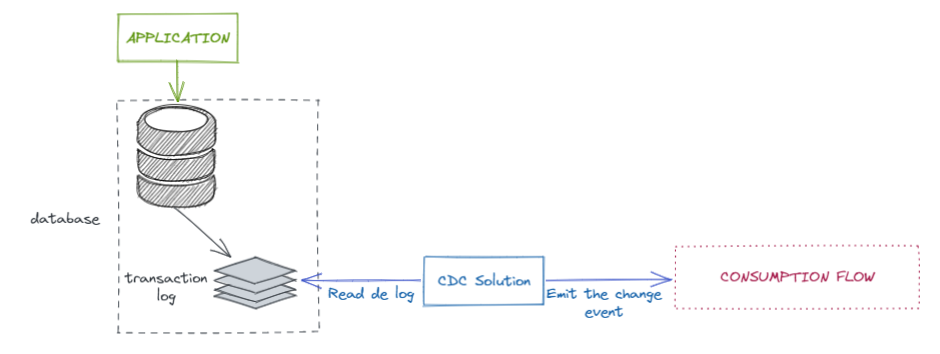
En el caso de nuestro artículo nos basaremos en Debezium, que ofrece conectores a todas esas bases de datos y que será nuestro punto de salida para el CDC.
¿Qué es Debezium?
Debezium es una plataforma open source para implementar CDC y conectarlos a un broker de mensajería de Kafka. Ofrece un conector específico de Kafka Connect que nos va a permitir utilizar el CDC como "source" de nuestro sistema y emitirlos a través de una infraestructura Kafka. También ofrece una solución fuera de Kafka Connect, aunque en este caso nos basaremos en la primera opción.
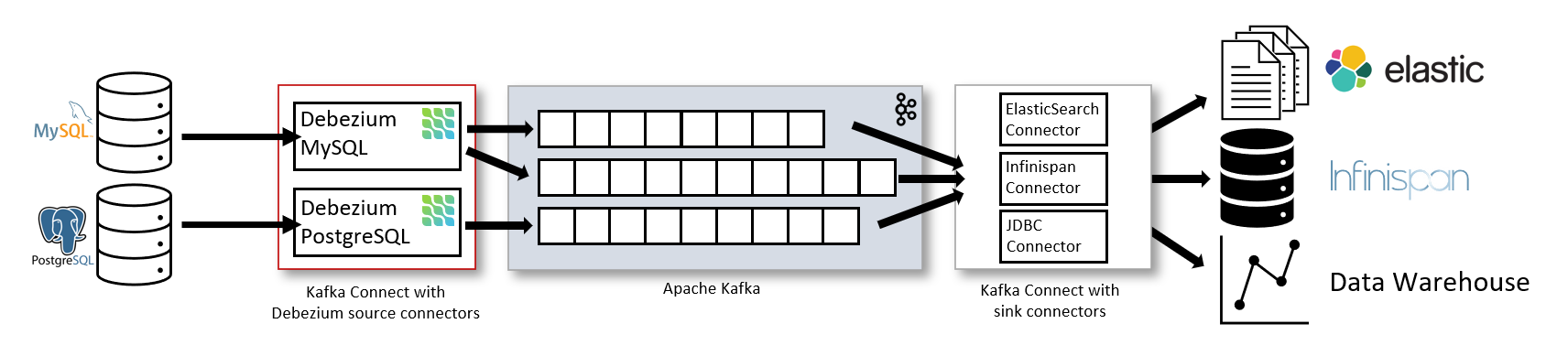
Las principales ventajas de debezium son las siguientes:
-
Al estar acoplado al transaction log de la BD garantiza que todos los cambios son procesados, incluso los DELETE.
-
Evita el polling y minimiza el delay de los cambios, reduciendo el consumo de CPU. Esta ventaja se enmarca dentro de la comparativa con CDC Query Based vs CDC Log Based como es Debezium.
-
No necesitas cambiar el modelo de datos para conocer los cambios, como por ejemplo añadiendo columnas de tipo date para indicar "Last Update". Esta ventaja se enmarca dentro de la comparativa con CDC Query Based vs CDC Log Based como es Debezium.
-
Permite añadir en el mensaje información extra como metadatos, el transaction Id la query ejecutada...
-
Es Open Source, es decir GRATIS. Pero está bajo el paraguas de RedHat.
Además ofrece las siguientes características:
-
Capacidad de hacer SNAPSHOTS (fotos) del estado actual de la BD ya sea en arranque o bajo demanda, y emitir todos esos cambios al broker.
-
Realizar filtrados, enmascarado y ofuscación de datos mediante configuración.
-
Es un sistema plugable como Kafka Connect, pudiendo añadir transformadores (SMTs) específicos para ajustar las necesidades de emisión de los mensajes. De hecho, para nuestro ejemplo usaremos un SMT proporcionado por Debezium que nos facilitará aplicar este patrón.
Actualmente ofrece soporte a las siguientes Bases de datos
-
MongoDB
-
MySQL
-
PostgreSQL
-
SQL Server
-
Oracle
-
Db2
-
Cassandra (Incubating)
-
Vitess (Incubating)
Los principales casos de uso que podemos aplicar con Debezium son:
- Replicación de datos. En cualquiera de sus formas:
- Migración entre modelos de datos, p.e: SQL -> NOSQL
- Nutrir sistemas de BigData o de Indexación para búsquedas.
- Mover datos entre ubicaciones físicas distintas
- ...
- Auditoría de datos.
- Gobierno de cachés.
- Aplicación de CQRS.
- ...
Y muchísimas ventajas más, por lo que os animo a descubrir este stack desde su página web debezium.io y a bucear un poquito más sobre él.
Aunque no es estrictamente necesario, sí que es interesante conocer un poco sobre Kafka Connect a la hora de enteder Debezium, ya que usaremos su conector, por tanto os animo a leer un poquito en el siguiente enlace: https://docs.confluent.io/platform/current/connect/index.html
Ejemplo de uso
En nuestro caso, vamos a centrarnos en cómo mediante un Debezium vamos a implementar el CDC y Transacional Outbox pattern aprovechando ciertas ventajas que vienen incluidas dentro de este producto como es Outbox Event Router dentro de los SMT (Single Message Transformation) que ofrece Debezium.
El ejemplo basado en Spring Boot 3, lo podréis descargar mgvinuesa/debezium-example está basado en otro de la propia página de github de debezium hecho en Quarkus debezium/outbox
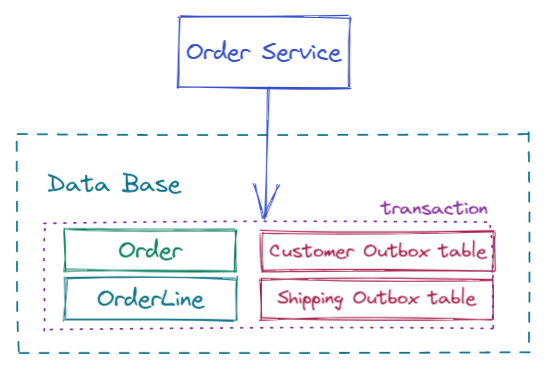
El objetivo es conseguir lo siguiente:
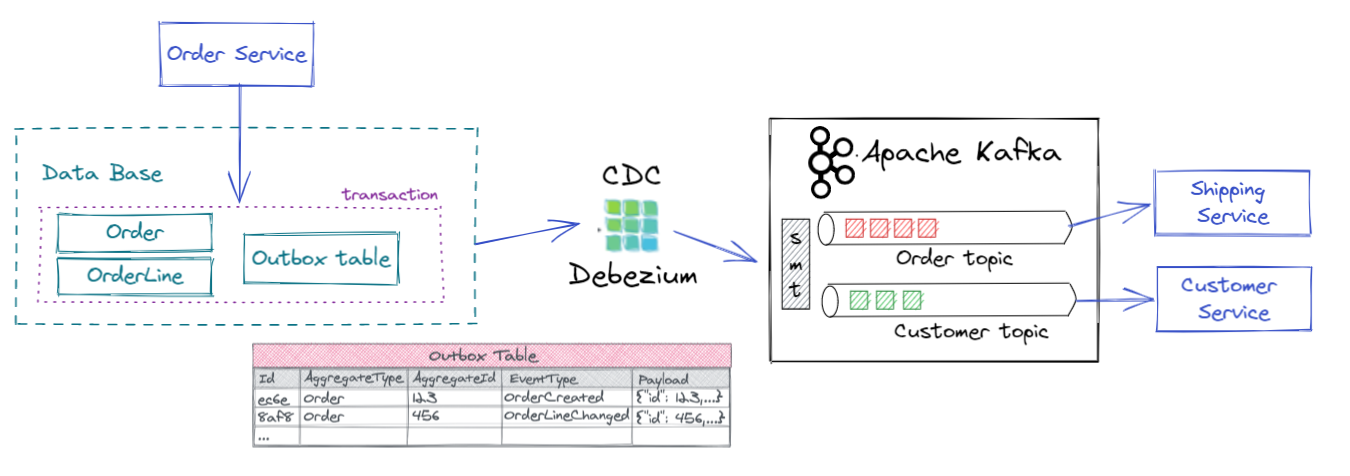
En nuestro caso vamos a crear lo siguiente:
-
Existe un servicio principal (order-service) que recibirá los pedidos vía HTTP y los gestionará, para ello almacenará cierta información en BD y otra la emitirá como eventos. En una arquitectura EDA tradicional emitiría directamente los eventos asociados a envíos (Order) y facturas (Customer). Aplicando transacional outbox, almacenaremos esa información en la outbox table de la BD.
-
La información almacenada en la outbox table es posteriormente leída a través del CDC (Debezium sobre Kafka Connect) y emitida a diferentes topics en base al tipo de mensaje (definido en una columna). Sin Debezium y sin el outbox event router aplicar esta solución sería más compleja, lo veremos a continuación.
-
Una vez cada mensaje es emitido al topic correspondiente existirían unos servicios encargados de procesar cada uno de ellos, en nuestro ejemplo no llegaremos a consumir los mensajes, ya que que aporta valor a la solución.En este caso las peticiones (Orders) serían consumidos por el microservicio de envíos y las facturas (Invoices) por el microservicio de clientes.
Posible alternativa
En muchos casos esta solución se suele aplicar con una outbox table por tipo de evento que queramos emitir, ya que, por organización funcional, en función del CDC o el sistema que tengamos puede ser complicado disgregar la información una vez está almacenada en la misma tabla. Pero pensemos que la outbox table es una tabla auxiliar, con un único propósito, mantener la transacción ACID y desacoplar la emisión de eventos de la transacción local.
Stack de la solución
En este caso el stack de la solución lo define el siguiente fichero de docker-compose:
version: '3'
services:
zookeeper:
image: quay.io/debezium/zookeeper:2.1.1.Final
ports:
- 2181:2181
- 2888:2888
- 3888:3888
kafka:
image: quay.io/debezium/kafka:2.1.1.Final
ports:
- 9092:9092
links:
- zookeeper
environment:
- ZOOKEEPER_CONNECT=zookeeper:2181
connect:
image: quay.io/debezium/connect:2.1.1.Final
ports:
- 8083:8083
links:
- kafka
- order-db
environment:
- BOOTSTRAP_SERVERS=kafka:9092
- GROUP_ID=1
- CONFIG_STORAGE_TOPIC=my_connect_configs
- OFFSET_STORAGE_TOPIC=my_connect_offsets
- STATUS_STORAGE_TOPIC=my_connect_statuses
- KAFKA_LOG4J_LOGGERS=io.debezium.connector=DEBUG
kafdrop:
image: obsidiandynamics/kafdrop:latest
ports:
- "9000:9000"
environment:
KAFKA_BROKERCONNECT: "kafka:9092,zookeeper:2181"
depends_on:
- kafka
- zookeeper
adminer:
image: adminer
restart: always
ports:
- 8090:8080
order-service:
build: ./order-service
environment:
SPRING_PROFILES_ACTIVE: "docker"
SPRING_DATASOURCE_URL: jdbc:postgresql://order-db:5432/orderdb?currentSchema=inventory
ports:
- "8080:8080"
depends_on:
- order-db
order-db:
image: quay.io/debezium/example-postgres:2.1.1.Final
ports:
- 5433:5432
healthcheck:
test: "pg_isready -U postgresuser -d orderdb"
interval: 2s
timeout: 20s
retries: 10
environment:
- POSTGRES_USER=postgresuser
- POSTGRES_PASSWORD=postgrespw
- POSTGRES_DB=orderdb
En dicho fichero podemos ver lo siguiente:
- Microservicio de orders y base de datos: Un micro basado en spring boot con acceso a BD de PostgreSQL.
- Stack de kafka: (kafka, zoopkeeper y connect), en este caso hemos usados las imagenes proporcionadas por debezium para tener preparada la infraestructura con el conector de connect para PostgreSQL.
- Herramientas de ayuda, como son un cliente de BD (adminer) y un cliente de kafka para visualizar la BD y los topics de kafka (kafdrop)
Además, usaremos postman para realizar las peticiones HTTP correspondientes.
Una vez levantado el stack con:
docker-compose up -d
Lo primero que deberíamos hacer es crear el conector de debezium que se encargará de extraer la información de la outbox table. Para ello deberemos invocar a la API de Kafka Connect. La especificación la podéis encontrar aquí
La petición que haremos será la siguiente:
curl --location --request POST 'http://localhost:8083/connectors/' \
--header 'Accept: application/json' \
--header 'Content-Type: application/json' --data-raw ...
Siendo el body de la petición el siguiente
{
"name": "orders-connector",
"config": {
"connector.class": "io.debezium.connector.postgresql.PostgresConnector",
"database.hostname": "order-db",
"database.port": "5432",
"database.user": "postgresuser",
"database.password": "postgrespw",
"database.dbname" : "orderdb",
"schema.include.list": "inventory",
"table.include.list" : "inventory.outbox",
"topic.prefix": "orders",
"transforms" : "outbox",
"transforms.outbox.type" : "io.debezium.transforms.outbox.EventRouter",
"transforms.outbox.table.expand.json.payload": "true",
"transforms.outbox.route.topic.replacement" : "outbox.${routedByValue}",
"transforms.outbox.table.fields.additional.placement" : "type:header:eventType",
"value.converter": "org.apache.kafka.connect.json.JsonConverter"
}
}
De esta manera crearemos el conector de debezium con las siguientes características:
- name: Nombre del conector
- connector.class: Clase del conector, en este caso, el conector de Postgresql
- database.hostname | port | user | password | dbname: Los parámetros asociados a la conexión de la BD donde aplicar el CDC.
- schema.include.list: schema de la base de datos donde se aplicará el CDC
- table.include.list: tablas donde aplicar el cdc, en este caso
- topic.prefix: prefijo a aplicar a los topics del CDC, por defecto Debezium emite a los topics con
prefijo-nombre de tabla, este parámetro luego no tendrá efecto al aplicar el EventRouter.
Toda la información sobre cómo crear este conector para postgresql la puedes encontrar aquí.
Y posteriormente la información asociada al transformador Outbox Event Router, aquí podéis ver toda la información sobre dicho SMT.
Es importante entender que este transformador está definido principalmente para trabajar con una tabla con la siguiente estructura:
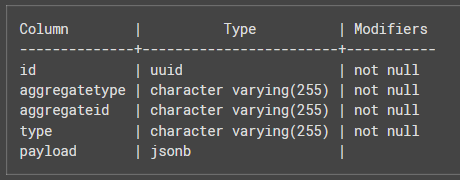
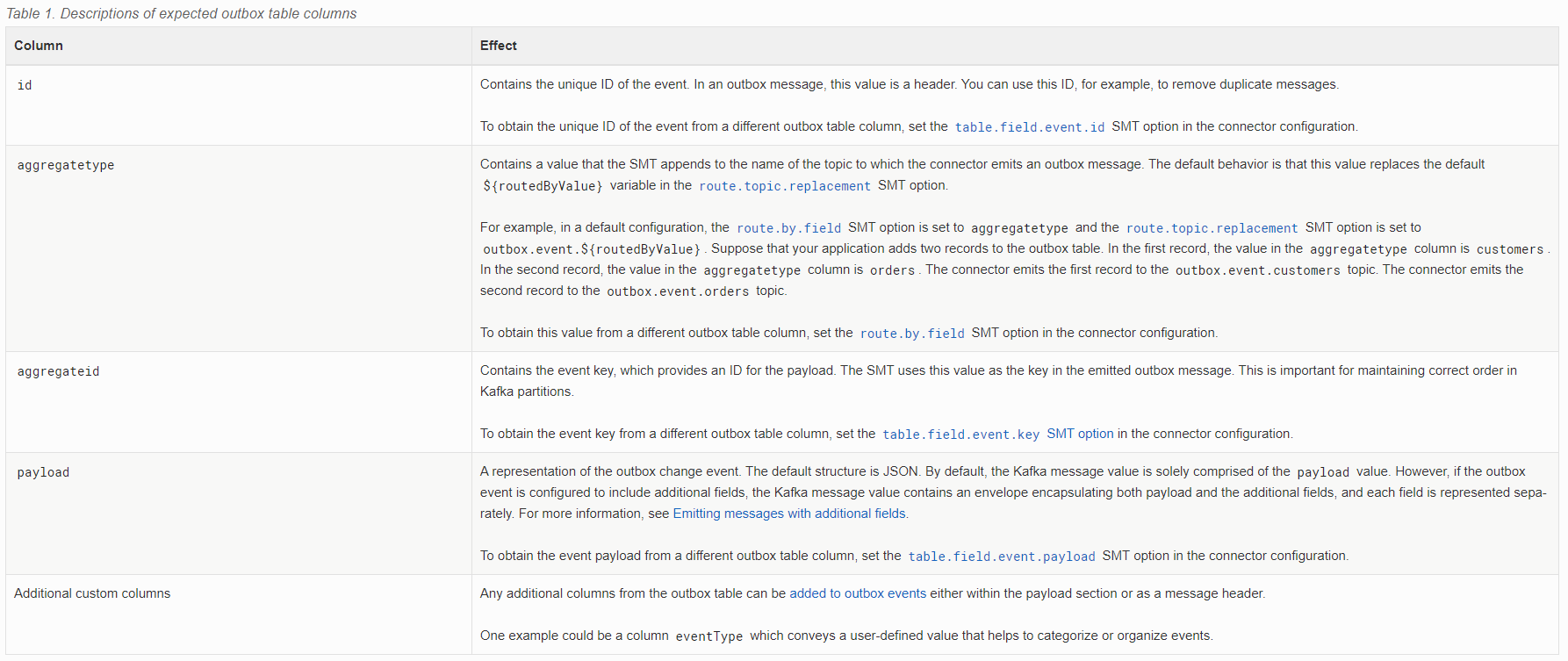
Pero es totalmente customizable como veremos a continuación.
- transforms: SMT o Transformadores a aplicar antes de emitir los eventos a Kafka.
- type: Tipo de SMT
- table.expand.json.payload: Nos va a permitir extraer el mensaje de tipo json formateado como objeto, luego veremos el ejemplo.
- route.topic.replacement: Nombre de los topics donde se emitirán los mensajes del outbox, es aquí donde ocurre parte de la magia, ya que para una única tabla, por defecto Debezium emitiría a un único topic, con esta opción podemos elegir el topic en base a una columna de la tabla outbox, en este caso la columna aggregateType (por defecto). Si se quisiera cambiar la columna deberíamos añadir la propiedad
route.by.field - table.fields.additional.placement: Permite añadir más información al mensaje en base a columnas adicionales.
- value.converter: Necesario para hacer el expand comentado en el atributo anterior.
Ahora sí, creamos el conector con esa configuración.
Sin entrar a explicar todo el código del microservicio order-service, el cual está disponible aquí, si que es interesante ver cómo se va a popular la tabla Outbox Table.
Para ello, en la capa de servicios, en el momento de guardar en la BD la información asociada de la petición invocamos a una interfaz de tipo Publisher. Una opción hubiera sido llamar el Repositorio de Outbox Table, pero de esta manera desacoplamos el código de negocio de esta solución técnica y además hacemos la analogía de cómo se implementaría la emisión de eventos sin el Transactional Outbox.
public PurchaseOrder addOrder(PurchaseOrder order) {
PurchaseOrder newOrder = repository.save(order);
publisher.fire(OrderCreatedEvent.of(this,order));
publisher.fire(InvoiceCreatedEvent.of(this,order));
return newOrder;
}
En un sistema sin CDC, estos eventos emitirían mensajes a un sistema de colas, ya sea Kafka, RabbitMQ... para informar de los cambios necesarios. Esta implementación tendría el problema inicial descrito a nivel de transaccionabilidad del sistema. Si falla el commit de la BD, los eventos ya se habrían emitido y necesitaríamos gestionar transacciones distribuidas, con el problema que eso conlleva.
En vez de eso, nuestra interfaz de tipo Publisher la usamos para desacoplar la escritura en la Outbox table, y usamos el sistema de eventos de Spring para simplemente invocar a los servicios encargados de almacenar la información en la tabla. La implementación es tan sencilla como una fachada sobre la clase de Spring ApplicationEventPublisher
@Component
public class SpringEventPublisher implements EventPublisher {
private ApplicationEventPublisher publisher;
public SpringEventPublisher(ApplicationEventPublisher publisher) {
this.publisher = publisher;
}
@Override
public void fire(Object event) {
publisher.publishEvent(event);
}
}
En este caso los eventos o mensajes simplemente deben extender de ApplicationEvent y crear los servicios de tipo Listener que implementarán las interfaces ApplicationListener<TIPO DE EVENTO>, por ejemplo para el evento OrderCreatedEvent tenemos el siguiente listener:
@Service
public class OrderCreatedEventListener implements ApplicationListener<OrderLineUpdatedEvent> {
private OutboxRepository repository;
public OrderCreatedEventListener(OutboxRepository repository) {
this.repository = repository;
}
@Override
public void onApplicationEvent(OrderLineUpdatedEvent event) {
Outbox outbox = Outbox.builder().aggregateid(event.getAggregateId())
.aggregatetype(event.getAggregateType())
.payload(event.getPayload().toString()).type(event.getType())
.id(UUID.randomUUID().toString())
.timestamp(event.getTimestamp()).build();
this.repository.save(outbox);
}
}
El cual a través del repositorio JPA de la Outbox table hace las inserciones aprovechando la transacción en curso. Otra alternativa podría ser usar la anotación @EventListener que podríamos usar a nivel de método.
¿Cómo se mantiene en la transacción si estamos usando eventos? Los eventos de Spring son por defecto síncronos, por lo que dicho evento sigue participando en la transacción. Aun así, podríamos usar la anotación @TransactionalEventListener o definirlos de manera asíncrona para tener un control más fino sobre dichos eventos.
Y ya finalmente, si invocamos al endpoint de nuestro servicio encargado de crear las peticiones:
curl --location --request POST 'localhost:8080/order' \
--header 'Content-Type: application/json' \
--data-raw '{
"customerId": 3,
"orderDate": "2023-01-02 15:43:57",
"lineItems": [
{
"item": "Table",
"quantity": 1,
"totalPrice": 7.6,
"status": null
}
]
}'
Podemos ver que ha pasado con el sistema:
-
Se ha creado el registro correspondiente en la tabla purchase_orders:
-
Se ha creado el registro correspondiente en la tabla order_line:
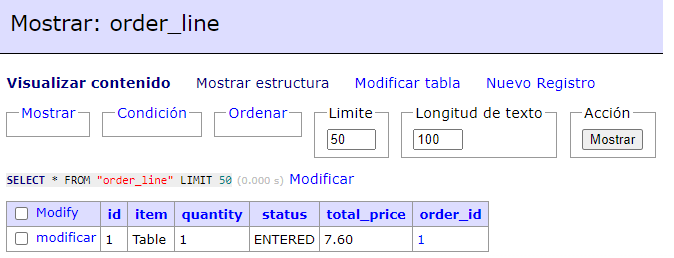
-
Y por supuesto, los registros en la tabla outbox asociados a los eventos que queremos generar:

De dicha tabla es importante revisar la columna aggregateType, la cual se usará para definir los topics donde se emitirán los eventos y por supuesto el payload, un JSON que se ha creado en el microservicio order-service para ser usado como cuerpo del mensaje.
Además, en este punto el CDC ha emitido los mensajes a los topics correspondientes, siguiendo el patrón definido: outbox.${routedByValue}

En cada uno de los topics tendremos el contenido almacenado en el payload de la tabla outbox:
-
Mensajes en el topic de customers:
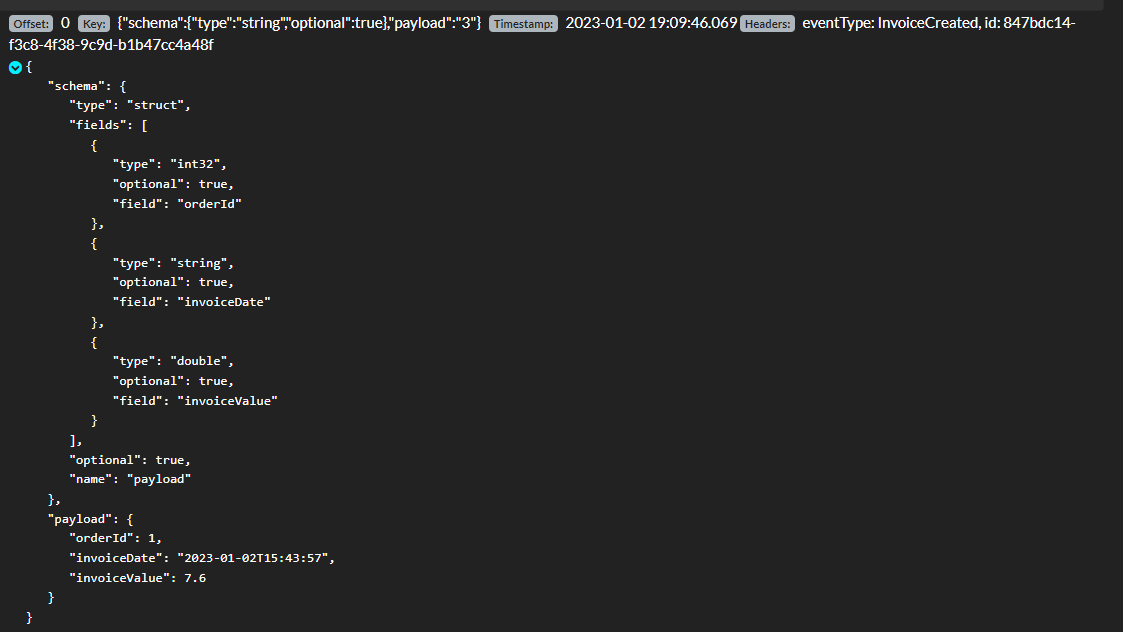
-
Mensajes en el tipic de orders:
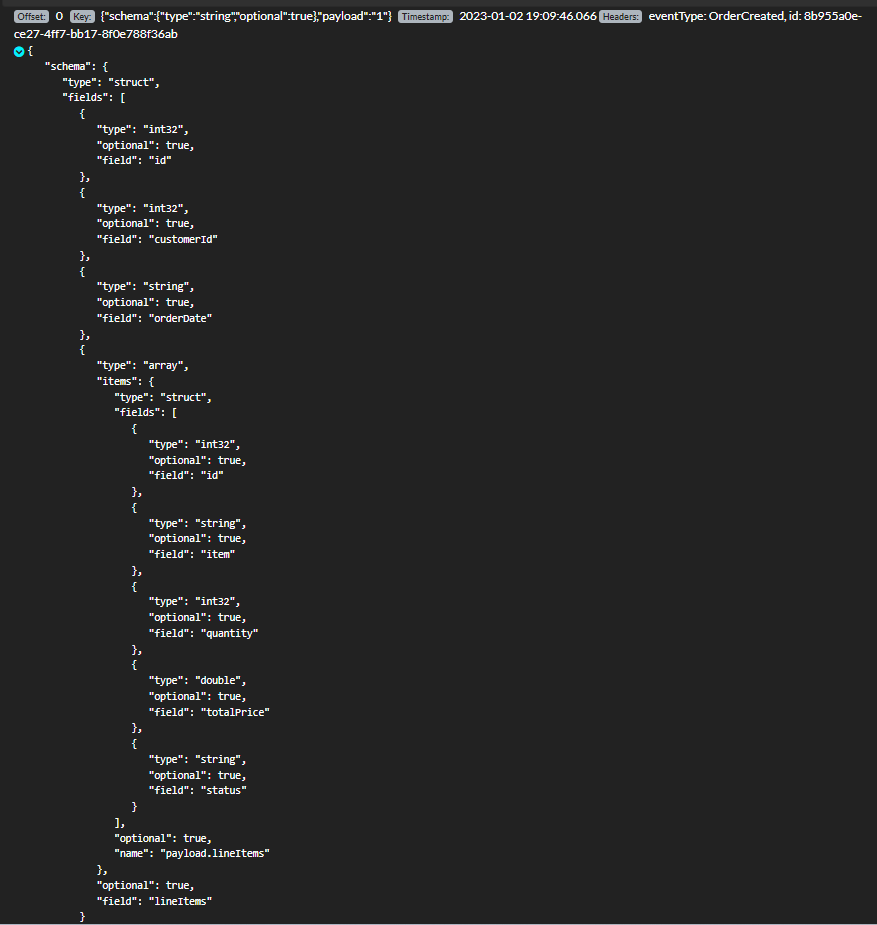

Además, se puede observar cómo se ha añadido cabeceras custom como el eventType usando la configuración del transformador:
"transforms.outbox.table.fields.additional.placement" : "type:header:eventType"
Dichos mensajes posteriormente ya si que podrían ser consumidos por los respectivos consumidores y tratados de la manera que el negocio determine.
Conclusiones
En este artículo hemos conocido dos patrones que nos ayudan a solventar uno de los principales riesgos de las arquitecturas de eventos, como es la transaccionabilidad.
El patrón Transactional Outbox tiene un objetivo muy claro, pero normalmente necesita apoyarse en otras soluciones como el Change Data Capture para ser efectivo.
Por supuesto, el uso de Debezium no se centra tan sólo en este problema, es una herramienta versátil, potente y OpenSource, que nos permite aplicar el patrón Change Data Capture en cualquiera de sus formas.
Bibliografía
https://debezium.io/blog/2020/02/10/event-sourcing-vs-cdc/
https://debezium.io/blog/2019/02/19/reliable-microservices-data-exchange-with-the-outbox-pattern/
https://microservices.io/patterns/data/transactional-outbox.html
https://speakerdeck.com/gunnarmorling/practical-change-data-streaming-use-cases-with-apache-kafka-and-debezium-qcon-san-francisco-2019
https://github.com/debezium/debezium-examples
https://docs.confluent.io/platform/current/connect/index.html
https://www.baeldung.com/spring-events
https://reflectoring.io/spring-boot-application-events-explained/