
Tratamiento de imágenes usando ImageDataGenerator en Keras
Publicado por Jesús Utrera Burgal el
En los artículos anteriores hemos entrenado diferentes modelos usando el dataset de imágenes CIFAR-100. Este dataset usa imágenes de 32x32 píxeles de resolución, por lo que trabajar con él en memoria es fácil. El problema aparece cuando se quieren entrenar modelos con resoluciones mayores (por ejemplo 500x500). En estos casos, intentar entrenar el modelo requiere de mucha memoria que no tenemos, por lo que es necesario dividir el proceso de entrenamiento en bloques (o batchs, en inglés) de menor tamaño de imágenes.

Para ello, Keras cuenta con la clase ImageDataGenerator, que nos permite generar dichos bloques, además de realizar la técnica llamada data augmentation.
Data augmentation
Antes de continuar, merece la pena explicar qué es data augmentation. La idea es que, cuando se dispone de un número de imágenes relativamente pequeño, podemos aumentar el número modificando las imágenes originales (haciendo zoom, escalado, flip horizontal, etc)

Notas del código
El código de este artículo lo he generado en la web de kaggle. Si quieres probar el código, descárgate el dataset y modifica las rutas al mismo en tu código o, si tienes cuenta de kaggle, haz un fork sobre el mismo.
Preparando el conjunto de datos
El primer paso es usar un dataset con imágenes suficientemente grandes. Usaremos una versión que modifiqué hace tiempo del dataset de imágenes de automóviles de Stanford. Éste se encuentra en la web de Kaggle en la siguiente dirección: Stanford car dataset by classes folder.
Las imágenes se dividen en dos carpetas: train y test (ya os imagináis para qué sirve cada una). Dentro de éstas, encontraremos otras carpetas que se van a corresponder con la etiqueta de la propia imagen. A su vez, dentro de estas subcarpetas, tenemos las imágenes. De esta forma, las imágenes correspondientes a un coche Acura TL Type-S del año 2008 se incluyen dentro de la subcarpeta Acura TL Type-S 2008.
Bien, pues empezamos cargando unas cuantas librerías necesarias y obtenemos el dataset.
import numpy as np # linear algebra
import pandas as pd # data processing, CSV file I/O (e.g. pd.read_csv)
import cv2
%matplotlib inline
import matplotlib.pyplot as plt
import seaborn as sn
import pandas as pd
import pickle
import csv
from sklearn.metrics import confusion_matrix, classification_report
import tensorflow as tf
from PIL import Image
import os
#Imprimimos para confirmar que está descargado el dataset
print(os.listdir("../input/stanford-car-dataset-by-classes-folder"))
['anno_test.csv', 'car_data', 'anno_train.csv', 'names.csv']
A continuación vamos a definir la ruta base para el dataset y mostraremos una imagen de prueba.
path_base = '../input/stanford-car-dataset-by-classes-folder'
image = Image.open(path_base + '/car_data/train/Volvo XC90 SUV 2007/00954.jpg')
imgplot = plt.imshow(image)
plt.show()

Ahora vamos a leer las etiquetas que se encuentran en el archivo names.csv.
class_names = []
with open(path_base + '/names.csv') as csvDataFile:
csvReader = csv.reader(csvDataFile, delimiter=';')
for row in csvReader:
class_names.append(row[0])
print(class_names)
['AM General Hummer SUV 2000', 'Acura RL Sedan 2012', 'Acura TL Sedan 2012', 'Acura TL Type-S 2008', 'Acura TSX Sedan 2012', 'Acura Integra Type R 2001', 'Acura ZDX Hatchback 2012', 'Aston Martin V8 Vantage Convertible 2012', 'Aston Martin V8 Vantage Coupe 2012', 'Aston Martin Virage Convertible 2012', 'Aston Martin Virage Coupe 2012', 'Audi RS 4 Convertible 2008', 'Audi A5 Coupe 2012', 'Audi TTS Coupe 2012', 'Audi R8 Coupe 2012', 'Audi V8 Sedan 1994', 'Audi 100 Sedan 1994', 'Audi 100 Wagon 1994', 'Audi TT Hatchback 2011', 'Audi S6 Sedan 2011', 'Audi S5 Convertible 2012', 'Audi S5 Coupe 2012', 'Audi S4 Sedan 2012', 'Audi S4 Sedan 2007', 'Audi TT RS Coupe 2012', 'BMW ActiveHybrid 5 Sedan 2012', 'BMW 1 Series Convertible 2012', 'BMW 1 Series Coupe 2012', 'BMW 3 Series Sedan 2012', 'BMW 3 Series Wagon 2012', 'BMW 6 Series Convertible 2007', 'BMW X5 SUV 2007', 'BMW X6 SUV 2012', 'BMW M3 Coupe 2012', 'BMW M5 Sedan 2010', 'BMW M6 Convertible 2010', 'BMW X3 SUV 2012', 'BMW Z4 Convertible 2012', 'Bentley Continental Supersports Conv. Convertible 2012', 'Bentley Arnage Sedan 2009', 'Bentley Mulsanne Sedan 2011', 'Bentley Continental GT Coupe 2012', ...]
Construyendo el modelo
Vamos a definir la arquitectura del modelo que vamos a usar. En este caso, vamos a entrenar una DenseNET. Antes de nada, cargamos las librerías de Keras.
from keras.preprocessing.image import ImageDataGenerator
from keras.applications import densenet
from keras.models import Sequential, Model, load_model
from keras.layers import Conv2D, MaxPooling2D
from keras.layers import Activation, Dropout, Flatten, Dense
from keras.callbacks import EarlyStopping, ReduceLROnPlateau, ModelCheckpoint, Callback
from keras import regularizers
from keras import backend as K
Y ahora, definimos los parámetros de entrenamiento.
K.set_learning_phase(1)
img_width, img_height = 224, 224
nb_train_samples = 8144
nb_validation_samples = 8041
epochs = 10
batch_size = 32
n_classes = 196
Hemos definido que la resolución de las imágenes será de 224x224 pero, si vemos las imágenes originales, son mayores (y diferentes entre sí). Pues bien, vamos a definir el generador de imágenes de entrenamiento usando la clase ImageDataGenerator.
train_data_dir = path_base + '/car_data/train'
validation_data_dir = path_base + '/car_data/test'
train_datagen = ImageDataGenerator(
rescale=1. / 255,
zoom_range=0.2,
rotation_range = 5,
horizontal_flip=True)
test_datagen = ImageDataGenerator(rescale=1. / 255)
train_generator = train_datagen.flow_from_directory(
train_data_dir,
target_size=(img_width, img_height),
batch_size=batch_size,
class_mode='categorical')
validation_generator = test_datagen.flow_from_directory(
validation_data_dir,
target_size=(img_width, img_height),
batch_size=batch_size,
class_mode='categorical')
Hemos definido la ruta de las imágenes de entrenamiento y validación. Para las de entrenamiento, le pedimos que las normalice y además queremos que, aparte de entrenar la imagen original, entrene con la misma imagen pero transformada mediante zoom, rotándola 5 grados y haciendo un flip horizontal. Para validar no haremos ninguna transformación aparte de la normalización.
Con esto definimos un generador de imágenes que podremos pasar directamente al modelo de entrenamiento. Mediante la operación flow_from_directory, le especificamos que use el directorio especificado como base y las etiquetas serán los nombres de los subdirectorios de la misma. Además, definimos la resolución específica de las imágenes y que el entrenamiento será multiclase. El parámetro batch_size especifica el número de imágenes a entrenar en cada bloque.
Definiendo la arquitectura
Usaremos la DenseNet-121 que Keras nos da por defecto. Inicializaremos el modelo con los pesos de la Imagenet ya preentrenada y, finalmente, añadiremos las capas de la red neuronal final.
ef build_model():
base_model = densenet.DenseNet121(input_shape=(img_width, img_height, 3),
weights='../input/full-keras-pretrained-no-top/densenet121_weights_tf_dim_ordering_tf_kernels_notop.h5',
include_top=False,
pooling='avg')
x = base_model.output
x = Dense(1000, kernel_regularizer=regularizers.l1_l2(0.01), activity_regularizer=regularizers.l2(0.01))(x)
x = Activation('relu')(x)
x = Dense(500, kernel_regularizer=regularizers.l1_l2(0.01), activity_regularizer=regularizers.l2(0.01))(x)
x = Activation('relu')(x)
predictions = Dense(n_classes, activation='softmax')(x)
model = Model(inputs=base_model.input, outputs=predictions)
return model
Como se puede ver, he usado regularización L1 y L2 para que el modelo generalice un poco mejor y la función de activación en las capas ocultas es ReLu. Finalmente, como el entrenamiento es multietiqueta pero no multiclase (un coche es de un modelo únicamente), usaremos Softmax para la capa final.
Lo siguiente es generar el modelo especificando las funciones de coste, optimización y las métricas, como siempre.
model = build_model()
model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['acc', 'mse'])
Las funciones de callback que vamos a usar son EarlyStopping, para que el entrenamiento pare si ve que no mejora la función de coste tras determinados epochs, y ReduceLROnPlateau, que si el entrenamiento no mejora tras unos epochs específicos, reduce el valor de learning rate del modelo, lo que normalmente obtiene una mejora del entrenamiento.
early_stop = EarlyStopping(monitor='val_loss', patience=8, verbose=1, min_delta=1e-4)
reduce_lr = ReduceLROnPlateau(monitor='val_loss', factor=0.1, patience=4, verbose=1, min_delta=1e-4)
callbacks_list = [early_stop, reduce_lr]
Entrenando el modelo
Lo siguiente que haremos será entrenar el modelo. Para ello, le pasaremos los generadores de imágenes que hemos definido en lugar del dataset.
model_history = model.fit_generator(
train_generator,
epochs=epochs,
validation_data=validation_generator,
validation_steps=nb_validation_samples // batch_size,
callbacks=callbacks_list)
Epoch 1/10
255/255 [==============================] - 428s 2s/step - loss: 87.8189 - acc: 0.0053 - mean_squared_error: 0.0051 - val_loss: 7.2779 - val_acc: 0.0085 - val_mean_squared_error: 0.0051
Epoch 2/10
255/255 [==============================] - 366s 1s/step - loss: 6.8774 - acc: 0.0085 - mean_squared_error: 0.0051 - val_loss: 6.8381 - val_acc: 0.0085 - val_mean_squared_error: 0.0051
Epoch 3/10
255/255 [==============================] - 365s 1s/step - loss: 6.8592 - acc: 0.0083 - mean_squared_error: 0.0051 - val_loss: 6.8758 - val_acc: 0.0085 - val_mean_squared_error: 0.0051
Epoch 4/10
255/255 [==============================] - 362s 1s/step - loss: 6.9016 - acc: 0.0083 - mean_squared_error: 0.0051 - val_loss: 6.9183 - val_acc: 0.0085 - val_mean_squared_error: 0.0051
Epoch 5/10
255/255 [==============================] - 338s 1s/step - loss: 6.9397 - acc: 0.0085 - mean_squared_error: 0.0051 - val_loss: 6.9541 - val_acc: 0.0085 - val_mean_squared_error: 0.0051
Epoch 6/10
255/255 [==============================] - 330s 1s/step - loss: 6.9764 - acc: 0.0083 - mean_squared_error: 0.0051 - val_loss: 6.9941 - val_acc: 0.0085 - val_mean_squared_error: 0.0051
Epoch 00006: ReduceLROnPlateau reducing learning rate to 0.00010000000474974513.
Epoch 7/10
255/255 [==============================] - 323s 1s/step - loss: 5.5087 - acc: 0.0083 - mean_squared_error: 0.0051 - val_loss: 5.4515 - val_acc: 0.0085 - val_mean_squared_error: 0.0051
Epoch 8/10
255/255 [==============================] - 346s 1s/step - loss: 5.4495 - acc: 0.0083 - mean_squared_error: 0.0051 - val_loss: 5.4531 - val_acc: 0.0085 - val_mean_squared_error: 0.0051
Epoch 9/10
255/255 [==============================] - 333s 1s/step - loss: 5.4504 - acc: 0.0083 - mean_squared_error: 0.0051 - val_loss: 5.4491 - val_acc: 0.0085 - val_mean_squared_error: 0.0051
Epoch 10/10
255/255 [==============================] - 330s 1s/step - loss: 5.4510 - acc: 0.0083 - mean_squared_error: 0.0051 - val_loss: 5.4519 - val_acc: 0.0085 - val_mean_squared_error: 0.0051
Una vez entrenado, vamos a ver las gráficas.
plt.figure(0)
plt.plot(model_history.history['acc'],'r')
plt.plot(model_history.history['val_acc'],'g')
plt.xticks(np.arange(0, 20, 1.0))
plt.rcParams['figure.figsize'] = (8, 6)
plt.xlabel("Num of Epochs")
plt.ylabel("Accuracy")
plt.title("Training Accuracy vs Validation Accuracy")
plt.legend(['train','validation'])
plt.figure(1)
plt.plot(model_history.history['loss'],'r')
plt.plot(model_history.history['val_loss'],'g')
plt.xticks(np.arange(0, 20, 1.0))
plt.rcParams['figure.figsize'] = (8, 6)
plt.xlabel("Num of Epochs")
plt.ylabel("Loss")
plt.title("Training Loss vs Validation Loss")
plt.legend(['train','validation'])
plt.figure(2)
plt.plot(model_history.history['mean_squared_error'],'r')
plt.plot(model_history.history['val_mean_squared_error'],'g')
plt.xticks(np.arange(0, 20, 1.0))
plt.rcParams['figure.figsize'] = (8, 6)
plt.xlabel("Num of Epochs")
plt.ylabel("MSE")
plt.title("Training Loss vs Validation Loss")
plt.legend(['train','validation'])
plt.show()

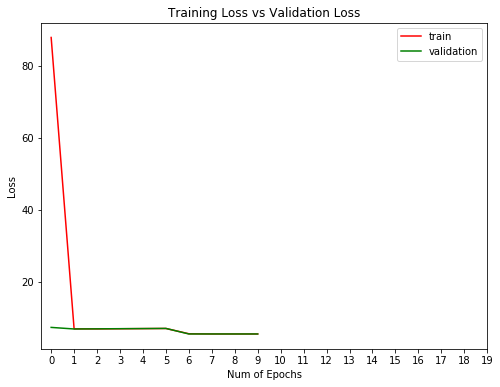
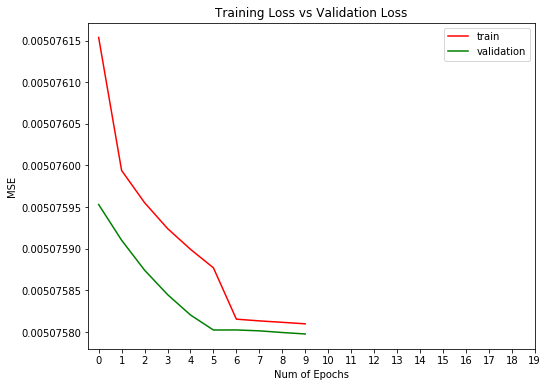
Bien, no ha ido mal. Vamos a evaluar el entrenamiento.
model.evaluate_generator(validation_generator, steps=None, max_queue_size=10, workers=1, use_multiprocessing=False)
[5.451917445210435, 0.008456659619450317, 0.005075798696735122]
Y generamos las predicciones del dataset de validación. Vamos a decir que el modelo de vehículo predicho será el máximo valor obtenido.
pred = model.predict_generator(validation_generator, steps=None, max_queue_size=10, workers=1, use_multiprocessing=False, verbose=1)
predicted = np.argmax(pred, axis=1)
252/252 [==============================] - 93s 370ms/step
Finalmente, vamos a ver algunas imágenes enfrentando su predicción con el valor real.
def predict_one(model):
image_batch, classes_batch = next(validation_generator)
predicted_batch = model.predict(image_batch)
for k in range(0,image_batch.shape[0]):
image = image_batch[k]
pred = predicted_batch[k]
the_pred = np.argmax(pred)
predicted = class_names[the_pred]
val_pred = max(pred)
the_class = np.argmax(classes_batch[k])
value = class_names[np.argmax(classes_batch[k])]
plt.figure(k)
isTrue = (the_pred == the_class)
plt.title(str(isTrue) + ' - class: ' + value + ' - ' + 'predicted: ' + predicted + '[' + str(val_pred) + ']')
plt.imshow(image)
predict_one(model)
Con este código, podemos ver un batch de imágenes del generador.
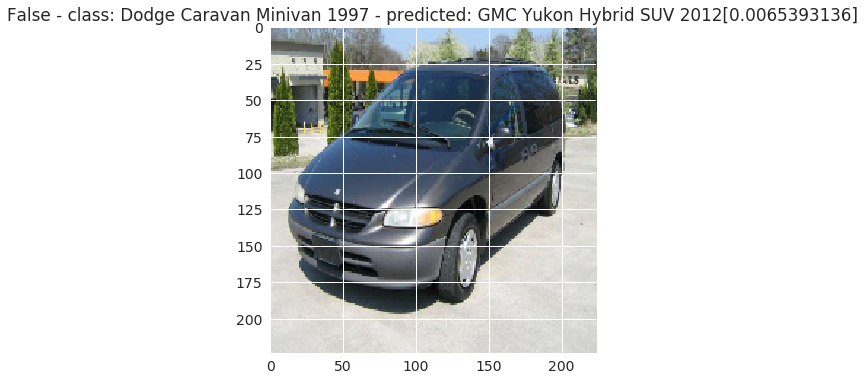
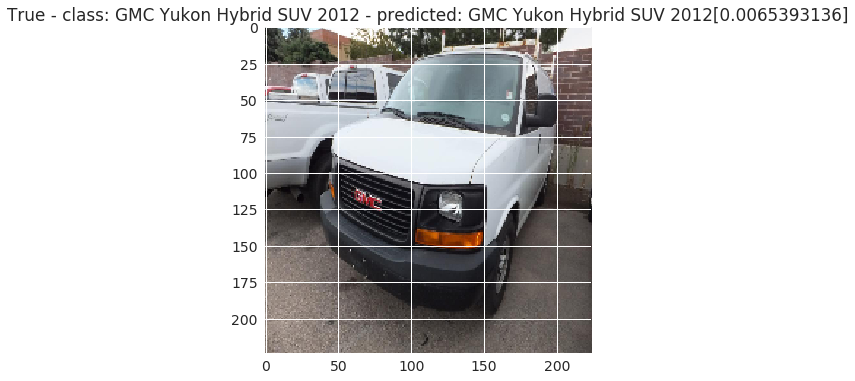
Conclusiones
En este artículo hemos podido ver como podemos trabajar con imágenes de mayor tamaño y como podemos realizar el proceso de data augmentation, técnica muy usada sobre todo para dataset poco numerosos, permitiendo disponer de un número mayor de imágenes a entrenar y permitiendo al modelo reconocer imágenes "no perfectas" al realizar las transformaciones.
Otro punto importante a tener en cuenta es que podemos definir nuestra propia clase DataGenerator y pasárselo a nuestro modelo, pero esto ya forma parte de un próximo artículo.
Hasta la próxima.
¡Síguenos en Twitter para estar al día de nuestros próximos posts!