
¿Y si documentamos la base de datos? ... SchemaSpy al rescate
Publicado por Víctor Madrid el
A veces "buceando" en Internet uno llega a encontrar por casualidad cosas realmente interesantes a todos los niveles, pero ahora nos vamos a centrar en esos productos de software con nombres "mágicos" que no sabíamos que existían, pero si que los necesitábamos. Cuando esto pasa tratamos de aprender todo lo que podemos sobre ellos, buscamos referencias de gente que lo haya utilizado, cruzamos los dedos para que funcione bien y sobre todo, confirmamos que tenga soporte actualizado (de alguna manera) y que no lleve discontinuado más de un año (esto da mucha rabia...jejeje)

Pues eso me ha pasado, estaba investigando sobre un tema de persistencia y un artículo me llevo a un tutorial, un tutorial a un comentario, y... al final encontré un producto de nombre curioso: SchemaSpy, que hizo que focalizara toda mi atención. Supuestamente era capaz de documentar una base de datos y lo mejor es que parecía relativamente sencillo de utilizar.
Este artículo está dividido en 4 partes:
- 1. Introducción
- 2. ¿Qué es un SchemaSpy?
- 3. Ejemplos de Uso
- 4. Conclusiones
1. Introducción
¿Cuánto conoces de tus Bases de Datos?
Partimos de que estamos acostumbrados a "desconocer" la información de las bases de datos con las que trabajamos y el hecho de pedir la información en muchos casos se convierte en un tema tabú /top secret para la mayoría de los proyectos. (a mi me lleva pasando años).
Pues resulta que estamos hablando de una de las piezas más importantes en cualquier desarrollo empresarial, ya que guardamos los datos que luego convertimos en información, posteriormente en conocimiento y esto define el core de una compañía y el sector sobre el que aplica.
Algunos ejemplos de situaciones que me he encontrado :
- Que NO exista nada de información salvo la conexión a la base de datos
- Que exista algún Confluence o Wiki en la compañía pero que normalmente o NO se sabe donde esta o esta desactualizadísimo
- Que exista algún documento inicial (de cuando se diseñó la base de datos con muy buena predisposición) pero que nadie sabe dónde esta, no se tiene la última versión, nunca se ha actualizado, etc.
- Que NO se tenga clara la información de la infraestructura utilizada : versión, máquina on-premise / cloud, SSOO, parches aplicados, soporte contratado, etc.
- Que la información sobre la base de datos sea una persona, es decir, existe una persona que tiene todo el conocimiento -> ¿Y si se pone malo? ¿Y si se va de la empresa? ¿tiene backup en otra persona?
- Que NO se tiene constancia de los cambios de base de datos en producción y en ningún otro entorno -> Requiere tracking, gestión y aplicación de base de datos (en base al resto de versiones de documentos)
- Que NO se pueda acceder a backups preparados para entornos bajos, es decir, para probar
- ...existen un millón de penurias más....
Soy de los que piensan que para la mayoría de los casos teniendo este conocimiento uno puede hacerse una idea del comportamiento de la aplicación o aplicaciones que lo utilizan casi al 80%. Recordemos que además de las tablas y sus relaciones existen otras piezas como: funciones, procedimientos almacenados, triggers, restricciones, vistas, tablas de secuencias...
En algunos casos si uno tiene el conocimiento anterior puede llegar a tener un conocimiento muy alto del funcionamiento de una empresa a muchos niveles : procedimientos de trabajo, volumetrías de uso, dominios funcionales con los que trabaja, alineamiento IT-Negocio, etc.
Propuestas para mejorarlo
Todos nos armamos de buenas voluntades como ir al gimnasio, dejar de fumar, .... y por qué no ... documentar las bases de datos :-)
Si lo pensamos fríamente al final nos tiramos muchas horas en el trabajo y si estas propuestas nos mejoraran nuestra calidad de vida cuando estamos en él con menos sustos, menos incertidumbres, un mayor conocimiento etc. entonces sería una buena inversión, ¿no?
Algunas de las propuestas sobre la base de datos que hago:
- Tratar de documentar lo máximo posible en alguno de los sistemas: documento, wiki, etc.
- Si NO se puede documentar casi todo entonces elegir aquello con lo que se debe tener más cuidado y/o consideración-> Enfoque Defensivo
- Lo que se "decida documentar" tratar de cumplirlo y llevarlo al día
- Disponer de algún diagrama visual que explique como se relacionan las tablas
- Tener documentados los procedimientos/funciones y otros elementos que normalmente tienen un ciclo de mantenimiento más frecuente que las tablas
- Usar algún framework como Liquibase o Flyway para el tracking de cambios en la base de datos
- Usar otras herramientas que nos puedan venir bien para nuestra casuística
- ...
2. ¿Qué es SchemaSpy?
Recursos con información sobre él:
- Web Principal SchemaSpy
- Documentación SchemaSpy
- Repositiorio de código Github
- Repositorio de contenedores Docker Hub
SchemaSpy es una herramienta definida como una librería de Java para proporcionar una documentación visual en HTML sobre la plataforma de base de datos, destaca por ser agnóstica de la plataforma (SQL Server, MySQL, Postgresql, ...) y muy fácil de utilizar.
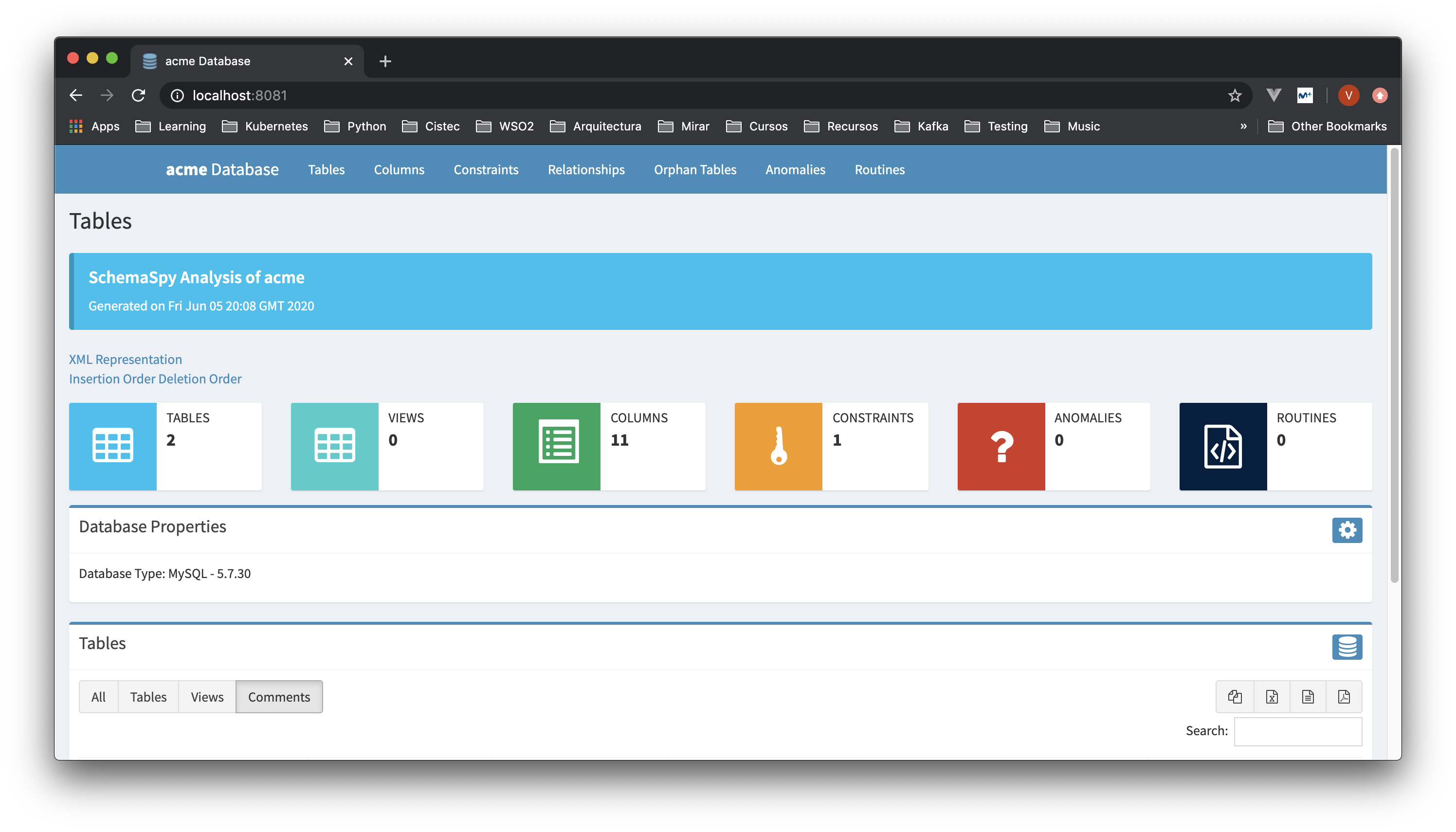
¿Qué información muestra de la base de datos analizada?
- Información sobre sus propiedades
- Información sobre el total de tablas : nombre, tablas hijas, tablas padre, volumetría de columnas, volumetría de filas, comentarios, etc.
- Información sobre una tabla : nombre, estructura de columnas, estructura de índices y diagrama de relación de la tabla con otros por niveles, volumetría de columnas, volumetría de filas, comentarios, etc.
- Información sobre el total de vistas: nombre, vistas hija, vistas padre, etc.
- Información sobre una vista: nombre, estructura de columnas, diagrama de relación, definición de la vista y tablas con las que se relacionan
- Información sobre las columnas: nombre y características (tabla, tipo, valor por defecto, etc.)
- Información sobre las relaciones a nivel de restricciones / constraints : nombre, columna a la que aplica, columna con la que esta relacionada, etc.
- Información visual sobre las relaciones de todas tablas en diferentes formatos: compacto (menos información) y largo (más información)
- Información sobre las tablas huérfanas
Información sobre ciertas anomalías:
- Columnas cuyo nombre y tipo indican la relación con la primary key de otra tabla
- Tablas SIN índices
- Tablas que contienen una única columna
- Tablas que podrían indicar desnormalización
- Columnas que tienen como valor por defecto 'NULL' o 'null'
- Información sobre rutinas (procedimientos /funciones) : nombre, lenguaje, valor de retorno, restricciones, etc.
- Información sobre una rutina (procedimiento /funciones) : nombre, parámetros y definición
Otras características :
- Generación de informes de algunos de sus elementos : PDF, CSV, xlsx. etc.
- Opciones de buscador
- Opciones de paginación
- Exportación de la representacion a XML
Entre todas las características que tiene la que más conquista a todos es su capacidad de mostrar en un diagrama la relación entre los elementos:
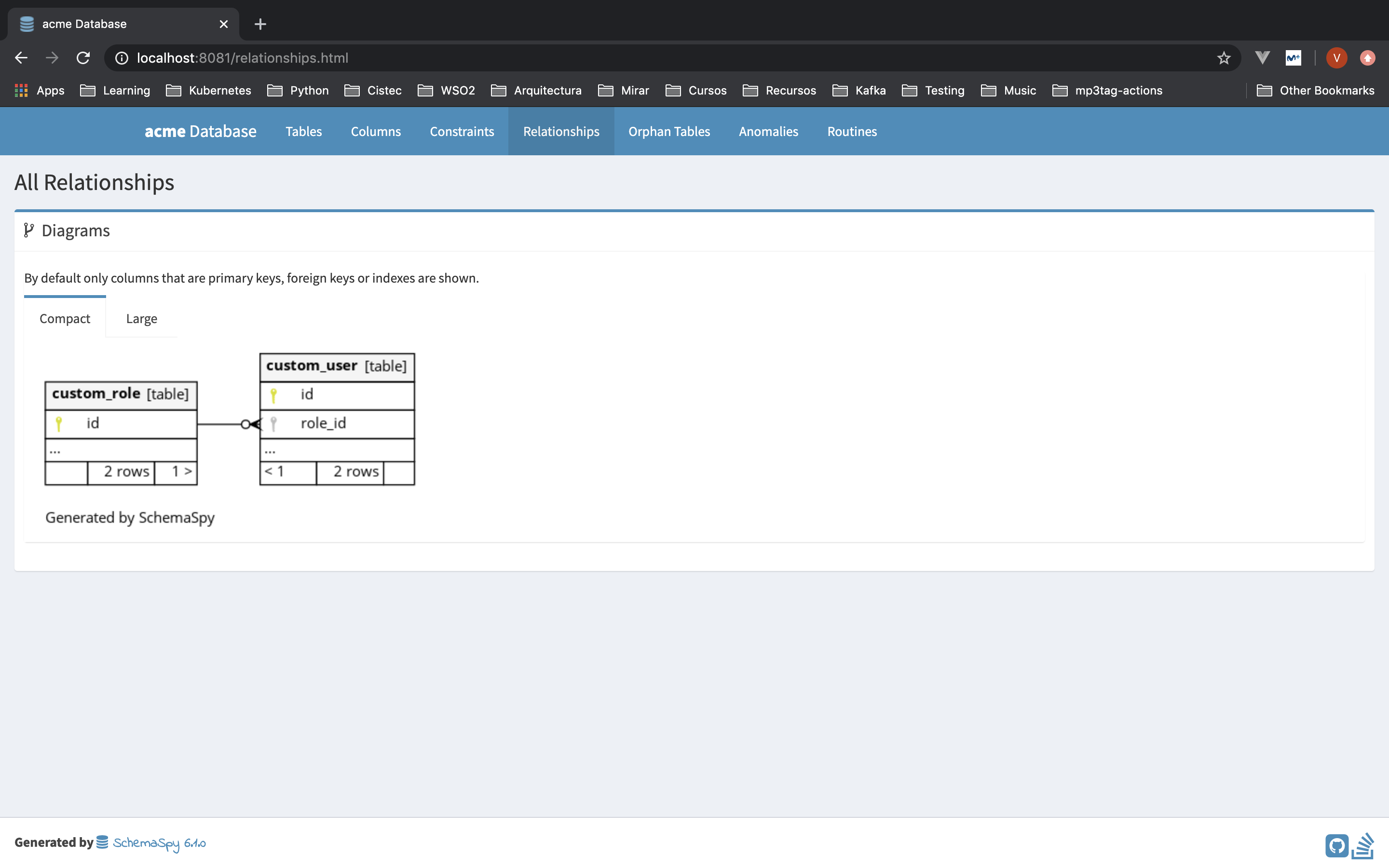
Para verificar la instalación mirar su documentación:
- La versión 6.1.0 no requiere el uso de la dependencia de Graphviz ya que lo tiene embebido.
- Las fuentes utilizadas para mostrar la información si que pueden ser necesarias tenerlas instaladas
3. Ejemplos de Uso
Para enseñar a utilizarlo y así practicar hemos habilitado un repositorio.
En estos ejemplos se implementará el modo de uso : standalone
¿Qué es el modo de uso "standalone"?
Ejecutar Schemaspy como una librería Java en base a 2 modos de ejecución (mediante ficheros y por parámetros) y generando los resultados HTML en un directorio
IMPORTANTE : En este caso Schemaspy requiere tener ciertas dependencias instaladas previamente (Graphviz) que será resuelto por la versión 6.1.0.
Preparación del entorno
Para ayudar en la realización del ejemplo se han definido 2 contenedores Docker de infraestructura para base de datos que montan la misma estructura y contenido de los datos al arrancar:
IMPORTANTE: Cada uno tiene el detalle de su implementación y uso en su fichero README
Si te no apetece utilizarlos también puedes utilizar tu propia instalación de base de datos on-premise o cloud, esto únicamente implicará cambios en el fichero de configuración utilizado para Schemaspy
Ejecución de los ejemplos
Para facilitar los ejemplos se han definidos dos proyectos de Schemaspy configurados de forma particular para funcionar con las 2 bases de datos utilizadas en el apartado "Preparación del entorno":
IMPORTANTE: Cada uno tiene el detalle de su implementación y uso en su fichero README
Cada proyecto consta de 3 elementos:
- Librería Schemaspy.
- Librería de conector / driver compatible con la base de datos a utilizar.
- Fichero de configuración que contiene los elementos de conexión a la base de datos.
Ejemplo de fichero de configuración para el ejemplo de MySQL:
# Database Type
schemaspy.t=mysql
# Path Database JDBC driver
schemaspy.dp=mysql-connector-java-6.0.6.jar
# Database Machine
schemaspy.host=127.0.0.1
schemaspy.port=3306
# Database user
schemaspy.u=test
schemaspy.p=test
# Database Name
schemaspy.db=acme
# Database Schema
schemaspy.s=acme
# Path output folder for the generated result
schemaspy.o=output
Se explico que en el modo "Standalone" que existen 2 modos de ejecución, ahora detallaremos cada uno de ellos:
Modo "Fichero de configuración"
El fichero de configuración contiene toda la información de la conexión
# Opción 1: Busca el fichero de configuración por defecto en la misma ruta de la librería
java -jar schemaspy-6.1.0.jar
# Opción 2: Se le facilita un fichero de configuración específico como parámetro
java -jar schemaspy-6.1.0.jar -configFile config/schemaspy-dev.properties
Modo "Parámetros"
En el momento de la ejecución se le proporciona toda la información de la conexión por parámetro
java -jar schemaspy-6.1.0.jar -t mysql -dp mysql-connector-java-6.0.6.jar -host 127.0.0.1 -port 3306 -u test -p test -db acme -s acme -o output
Verificar resultados
Tras la ejecución de lo anterior y si todo ha ido bien se generarán los resultados del análisis en el directorio indicado, al cual podremos acceder y visualizar desde un navegador:
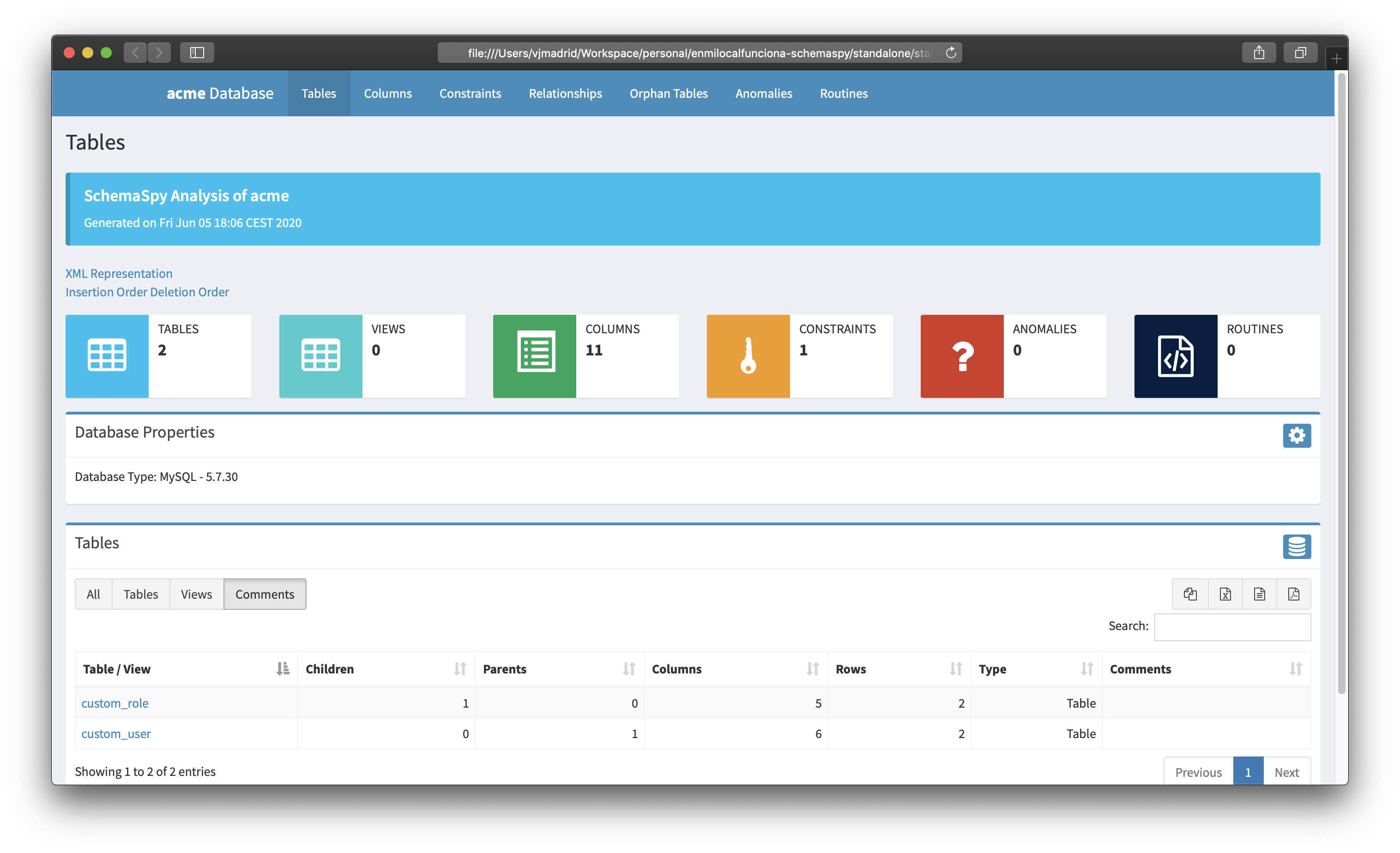
4. Conclusiones
La primera vez que lo vi funcionar contra el proyecto actual me pareció verdadera magia y más viendo lo poco que había costado configurarlo / utilizarlo. De hecho yo lo he utilizado para varias cosas interesantes :
- Verificar el comportamiento que debería de tener una funcionalidad en base a las restricciones que tenía en base de datos y a su diagrama de relación con otras tablas
- Disponer de una foto actual de todo lo desarrollado hasta el momento
- Verificar que el área o persona encargada ha aplicado los cambios sobre la base de datos tal y como estaban definidos
- Encontrar problemas de mapeo de entidades en el desarrollo
- Comparar versiones de análisis para ver los cambios realizados a alto nivel (sin tener una herramienta de tracking)
- Verificar que la base de datos tiene lo prometido (El clásico "Si son 4 tablas" y luego son 73...jejeje)
- Verificar que el driver de conexión utilizado en el desarrollo es totalmente compatible con la plataforma actual o ante un posible upgrade
- ...
Creo que puede ser una muy buena alternativa para generar documentación sobre la base de datos o complementar la existente y así solventar algunos de problemas que enumeraba en el punto 1.
Una posible mejora de esto podría ser no tener que realizar el análisis bajo demanda, sino que lo podríamos incluir como un producto más dentro del ciclo de ejecución de una pipeline de CI... pero para esto tendréis que esperar a próximos artículos :-)
Si te ha gustado, ¡síguenos en Twitter para estar al día de nuevos artículos!