
Clúster de Docker con Swarm Mode
Publicado por Ignacio Sánchez Ginés el
A partir de la versión 1.12 de Docker es muy sencillo hacer un clúster formado por varios Docker Hosts mediante lo que se conoce como Swarm Mode.
Swarm es ahora parte integral del engine y no tendremos que instalar elementos adicionales.

Además, se han incluido nuevas funcionalidades como escalado, balanceo de carga y rolling updates, todo ello completamente integrado en la instalación de Docker.
Vamos a ver en primer lugar los conceptos básicos dentro de Swarm y después, gracias a Vagrant, veremos cómo crear un clúster funcional.
Si lo que quieres es ver directamente el Vagrantfile aquí tienes el repo.
Nodos
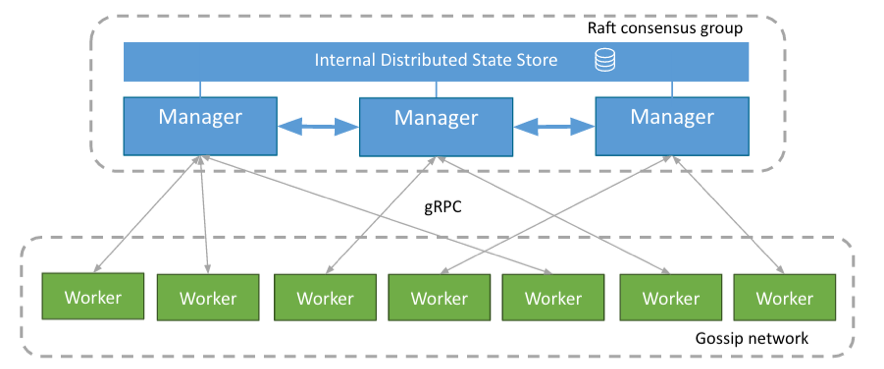
En un clúster de Swarm existen dos tipos de nodo, Manager y Worker.
Los nodos Manager son los encargados de gestionar el clúster. Entre todos los Manager se elige automáticamente un líder y éste es el encargado de mantener el estado del clúster.
Los Manager son también los encargados de distribuir las tareas o tasks (unidades básicas de trabajo) entre todos los nodos Worker, los cuales reciben estas tareas y las ejecutan.
Los nodos Manager por defecto también actúan como nodos Worker aunque se puede cambiar su configuración para que sólo asuman tareas de Manager.
Servicios y tareas
Un servicio define las tareas que serán ejecutadas dentro del clúster.
Cuando creamos un servicio le indicamos a Swarm qué imagen y qué parametrización se utilizará para crear los contenedores que se ejecutarán después como tareas dentro del clúster.
Existen dos tipos de servicios, replicados y globales:
- En un servicio replicado, Swarm creará una tarea por cada réplica que le indiquemos para después distribuirlas en el clúster. Por ejemplo, si creamos un servicio con 4 réplicas, Swarm creará 4 tareas.
- En un servicio global, Swarm ejecutará una tarea en cada uno de los nodos del clúster.
Como hemos dicho antes, las tareas son la unidad de trabajo dentro de Swarm. Realmente son la suma de un contenedor más el comando que ejecutaremos dentro de ese contenedor.
Los Manager asignan tareas a los nodos Worker de acuerdo al número de réplicas definidas por el servicio. Una vez que la tarea es asignada a un nodo ya no se puede mover a otro, tan sólo puede ejecutarse o morir.
Ante la caída de una tarea, Swarm es capaz de crear otra similar en ese u otro nodo para cumplir con el número de réplicas definido.
Balanceo
Swarm tiene un sistema de balanceo interno para exponer servicios hacia el exterior del clúster.
Un Manger es capaz de publicar automáticamente un puerto generado al azar en el rango 30000-32767 para cada servicio, o bien, nosotros podemos publicar uno específico.
Cualquier sistema externo al clúster podrá acceder al servicio en este puerto publicado a través de cualquier nodo del clúster, independientemente de que ese nodo esté ejecutando una tarea del servicio o no.
Todos los nodos del clúster enrutarán a una tarea que esté ejecutando el servicio solicitado.
Además, Swarm cuenta con un DNS interno que asigna automáticamente una entrada a cada uno de los servicios desplegados en el clúster.
Creación del clúster
Para crear un clúster con Swarm Mode tenemos que partir de un nodo destinado a ser Manager. Este nodo debe tener Docker 1.12 o superior ya instalado.
Suponiendo que la IP del nodo es 192.168.3.80, ejecutamos el siguiente comando:
$ docker swarm init --advertise-addr 192.168.3.80
Swarm initialized: current node (cf2mywzpa3pd77z23u5jciqwi) is now a manager.
To add a worker to this swarm, run the following command:
docker swarm join \
--token SWMTKN-1-50edlk935u9qgvrs8alhpzf1awgdil2dmfs4zgpd8ue2ltkmww-3y9tb0pjnieqao9ahkutpvpxe \
192.168.3.80:2377
To add a manager to this swarm, run the following command:
docker swarm join \
--token SWMTKN-1-50edlk935u9qgvrs8alhpzf1awgdil2dmfs4zgpd8ue2ltkmww-06m3vta11n4ihjyr1ytycwqvf \
192.168.3.80:2377
Al ejecutar el comando hemos inicializado este nodo como Manager.
Con el parámetro obligatorio --advertise-addr le indicamos la IP del Manager que se utilizará internamente para las conexiones de Swarm. Si omitimos el puerto tomará el 2377 por defecto.
La salida del comando nos muestra dos tokens. Cada uno de ellos sirve para unir nodos Manager y Worker adicionales.
Añadiremos ahora un nodo Worker al clúster. Para ello y desde la consola del Worker ejecutamos:
$ docker swarm join --token SWMTKN-1-50edlk935u9qgvrs8alhpzf1awgdil2dmfs4zgpd8ue2ltkmww-3y9tb0pjnieqao9ahkutpvpxe 192.168.3.80:2377
This node joined a swarm as a worker.
Como puedes ver hemos utilizado el token para nodos Worker. Le indicamos también la IP y puerto de uno de los nodos Manager del clúster existente.
Si queremos añadir otro Manager el comando sería el mismo, pero usaríamos el otro token.
Gestión de servicios
Una vez tengamos el clúster preparado, podemos empezar a correr servicios sobre él.
Para dar de alta un nuevo servicio nos vamos a la consola de un Manager y ejecutamos lo siguiente:
$ docker service create --replicas 1 --name helloworld alpine ping enmilocalfunciona.io
Donde --name es el nombre del servicio y --replicas es el número de tareas de este servicio que queremos crear.
Ahora podemos ver un listado de todos los servicios en el clúster:
$ docker service ls
ID NAME SCALE IMAGE COMMAND
9uk4639qpg7n helloworld 1/1 alpine ping enmilocalfunciona.io
Y podemos ver información sobre el servicio:
$ docker service inspect --pretty helloworld
ID: 9uk4639qpg7npwf3fn2aasksr
Name: helloworld
Mode: REPLICATED
Replicas: 1
Placement:
UpdateConfig:
Parallelism: 1
ContainerSpec:
Image: alpine
Args: ping docker.com
Podemos ver todas las tareas que se están ejecutando para este servicio:
$ docker service ps helloworld
ID NAME SERVICE IMAGE LAST STATE DESIRED STATE NODE
8p1vev3fq5zm0mi8g0as41w35 helloworld.1 helloworld alpine Running 3 minutes Running worker2
Si queremos aumentar o disminuir el número de réplicas ejecutamos:
$ docker service scale helloworld=5
helloworld scaled to 5
Y después comprobamos en qué nodos están corriendo las nuevas réplicas:
$ docker service ps helloworld
ID NAME SERVICE IMAGE LAST STATE DESIRED STATE NODE
8p1vev3fq5zm0mi8g0as41w35 helloworld.1 helloworld alpine Running 7 minutes Running worker2
c7a7tcdq5s0uk3qr88mf8xco6 helloworld.2 helloworld alpine Running 24 seconds Running worker1
6crl09vdcalvtfehfh69ogfb1 helloworld.3 helloworld alpine Running 24 seconds Running worker1
auky6trawmdlcne8ad8phb0f1 helloworld.4 helloworld alpine Running 24 seconds Accepted manager1
ba19kca06l18zujfwxyc5lkyn helloworld.5 helloworld alpine Running 24 seconds Running worker2
Rolling Updates
Otra funcionalidad de Swarm Mode son los Rolling Updates, es decir, la capacidad de gestionar actualizaciones en los servicios.
Si la imagen de un servicio se ha actualizado o cambia, podemos decirle a Swarm que actualice el servicio y, a su vez, todas las tareas asociadas al servicio.
La actualización de las tareas se puede hacer secuencialmente o en paralelo.
Por defecto se hace secuencialmente. Si queremos paralelizar las actualizaciones debemos indicarlo en el momento de la creación del servicio:
$ docker service create --replicas 4 --name redis --update-delay 10s --update-parallelism 2 redis:3.0.6
Donde --update-delay es el tiempo que esperará hasta empezar con la actualización de la siguiente tarea, y donde --update-parallelism será el número de tareas que actualizará en paralelo.
Para realizar una actualización le indicamos la nueva imagen:
$ docker service update --image redis:3.0.7 redis
Ejemplo con Vagrant
He preparado un Vagrantfile que define la creación de 4 máquinas: 1 Manager y 3 Workers.
Puedes descargarlo desde este repositorio en GitHub.
Para ejecutar el ejemplo necesitas Vagrant y VirtualBox instalados en tu equipo.
Abre un terminal, ubícate en la carpeta donde está el Vagrantfile y ejecuta lo siguiente:
$ vagrant up
Tardará un rato en crear y provisionar las 4 máquinas. Una vez terminado podrás ver las máquinas corriendo en la consola de VirtualBox.
El proceso de provisión dentro del Vagrantfile inicializa el clúster, por lo que la máquina manager será un nodo Manager y las máquinas worker01, worker02 y worker03 serán nodos Worker.
Vuelve a la línea de comandos y ejecuta lo siguiente:
$ vagrant ssh manager
Con este comando establecemos una conexión SSH con el nodo Manager. Desde aquí podemos lanzar comandos contra el clúster.
Por ejemplo, podemos ver todos los nodos:
ubuntu@manager:~$ docker node ls
ID HOSTNAME STATUS AVAILABILITY MANAGER STATUS
00wdlxkq8z3vclk4qhnvbwcte * manager Ready Active Leader
0hb5gtdgyz12ur6tc0w19i1ms worker01 Ready Active
27kfxl9tt8cp8tlocsixzadhs worker03 Ready Active
eym3j1kpehhnpi3kn6y3t8tgr worker02 Ready Active
Crear un servicio nuevo:
ubuntu@manager:~$ docker service create --replicas 10 --name helloworld -p 8080:8080 drhelius/helloworld-node-microservice
ewa6g6c3vg2kbqzl5uqvi3pli
Y ver sus tareas:
ubuntu@manager:~$ docker service ps helloworld
ID NAME IMAGE NODE DESIRED STATE CURRENT STATE ERROR
dzzx4h9hvrtw3epmevcu7yy2l helloworld.1 drhelius/helloworld-node-microservice worker01 Running Running 21 seconds ago
bno0v0qbwg0w0s6f1g6x1alf8 helloworld.2 drhelius/helloworld-node-microservice worker01 Running Running 19 seconds ago
dsr04ea3elew33o322rgc7hrf helloworld.3 drhelius/helloworld-node-microservice worker02 Running Running 19 seconds ago
dbdx3h4i2wu9vv9blbummxjbf helloworld.4 drhelius/helloworld-node-microservice manager Running Running 18 seconds ago
dzvx5ytxesyep19w3um0cjydt helloworld.5 drhelius/helloworld-node-microservice manager Running Running 18 seconds ago
7ok2a8f38v8vvowte2296l5si helloworld.6 drhelius/helloworld-node-microservice manager Running Running 18 seconds ago
99cu0ng1gwrld9qn9zob71lo6 helloworld.7 drhelius/helloworld-node-microservice worker02 Running Running 19 seconds ago
52ocauexh8pxkn2sl6xqtr3he helloworld.8 drhelius/helloworld-node-microservice worker03 Running Running 20 seconds ago
1p1rxo3cjku5wbddseig86d9c helloworld.9 drhelius/helloworld-node-microservice worker03 Running Running 19 seconds ago
cj7q61uifz0aha4axzotko868 helloworld.10 drhelius/helloworld-node-microservice worker03 Running Running 19 seconds ago
Para consumir este servicio podemos realizar una petición sobre cualquier nodo del clúster.
Swarm enrutará nuestra petición a un nodo que tenga una tarea de ese servicio corriendo.
Por ejemplo, podemos probarlo apuntando al Manager y utilizando el puerto que expusimos en su creación, 8080:
ubuntu@manager:~$ curl localhost:8080
Hello World!
Aunque esta prueba funcionaría desde cualquier nodo o desde el exterior del clúster si apuntamos a la IP de un nodo.
En este momento podemos simular el fallo del nodo worker03 con 3 tareas corriendo.
Swarm tratará de mantener el estado dentro del clúster. Como se pierden 3 tareas, tendrá que ejecutar 3 nuevas en otros nodos.
Para probarlo, terminamos la sesión SSH con el Manager, entramos en el worker03 y lo apagamos:
ubuntu@manager:~$ exit
$ vagrant ssh worker03
ubuntu@worker03:~$ sudo shutdown -h now
Entramos de nuevo en el Manager y vemos qué ha pasado:
ubuntu@manager:~$ docker service ps helloworld
ID NAME IMAGE NODE DESIRED STATE CURRENT STATE ERROR
dzzx4h9hvrtw3epmevcu7yy2l helloworld.1 drhelius/helloworld-node-microservice worker01 Running Running 4 minutes ago
bno0v0qbwg0w0s6f1g6x1alf8 helloworld.2 drhelius/helloworld-node-microservice worker01 Running Running 4 minutes ago
dsr04ea3elew33o322rgc7hrf helloworld.3 drhelius/helloworld-node-microservice worker02 Running Running 4 minutes ago
dbdx3h4i2wu9vv9blbummxjbf helloworld.4 drhelius/helloworld-node-microservice manager Running Running 4 minutes ago
dzvx5ytxesyep19w3um0cjydt helloworld.5 drhelius/helloworld-node-microservice manager Running Running 4 minutes ago
7ok2a8f38v8vvowte2296l5si helloworld.6 drhelius/helloworld-node-microservice manager Running Running 4 minutes ago
99cu0ng1gwrld9qn9zob71lo6 helloworld.7 drhelius/helloworld-node-microservice worker02 Running Running 4 minutes ago
bi9hj1ewoudsvus0otqgy5851 helloworld.8 drhelius/helloworld-node-microservice worker01 Running Running 12 seconds ago
52ocauexh8pxkn2sl6xqtr3he \_ helloworld.8 drhelius/helloworld-node-microservice worker03 Shutdown Running 4 minutes ago
3n0l2q8xk8ub6teh9n6fm014l helloworld.9 drhelius/helloworld-node-microservice worker01 Running Running 13 seconds ago
1p1rxo3cjku5wbddseig86d9c \_ helloworld.9 drhelius/helloworld-node-microservice worker03 Shutdown Running 4 minutes ago
93b9jwhx3kef40vp2yncu2jgr helloworld.10 drhelius/helloworld-node-microservice worker02 Running Running 12 seconds ago
cj7q61uifz0aha4axzotko868 \_ helloworld.10 drhelius/helloworld-node-microservice worker03 Shutdown Running 4 minutes ago
Si en este momento arrancamos de nuevo el worker03 veremos que las tareas se quedan como están, ya que ahora no es necesario ningún cambio para cumplir con las 10 réplicas.
Conclusión
Hemos visto los conceptos básicos y algunos comandos de Swarm Mode.
También hemos comprobado lo sencillo que resulta crear un clúster y hacerlo funcionar en Vagrant.
Toda la documentación sobre Swarm Mode se encuentra aquí.
Además, tenemos un listado con todos los comandos de Swarm.
A partir de aquí, puedes seguir haciendo cualquier tipo de prueba sobre el clúster en Vagrant.
Puedes consultar otros posts sobre Docker aquí.